标签:gb2312 字符 class 兼容 www 如何 信息技术 ref 扩展
标签(空格分隔): Java基础
各种各样的编码标准搞得头大,哪哪分不清。so,想按照字符编码出现的时间顺序做一个梳理。
ASCII,American Standard Code for Information Interchange,美国信息交换标准代码.
由电报码发展而来。
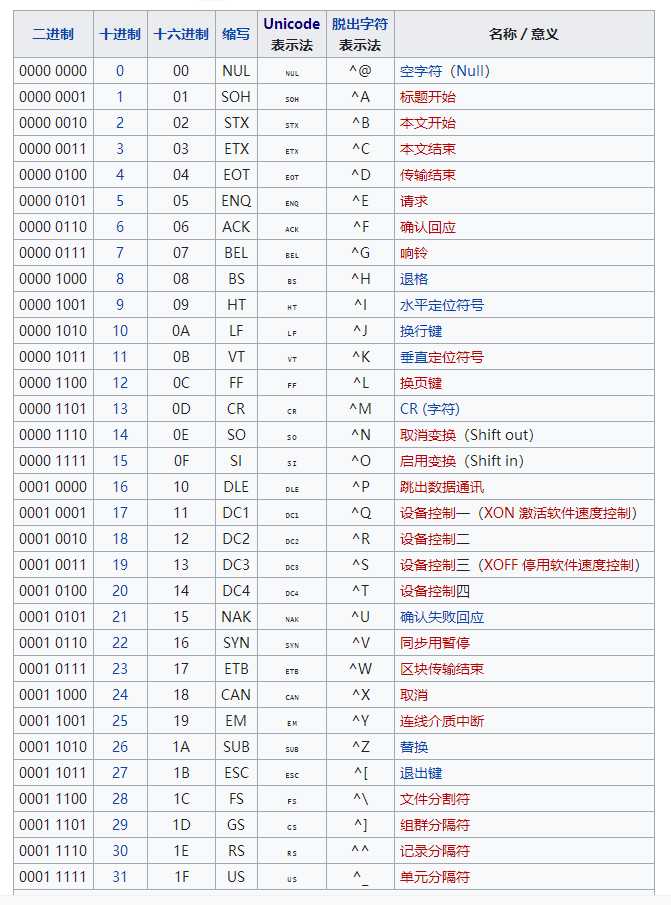
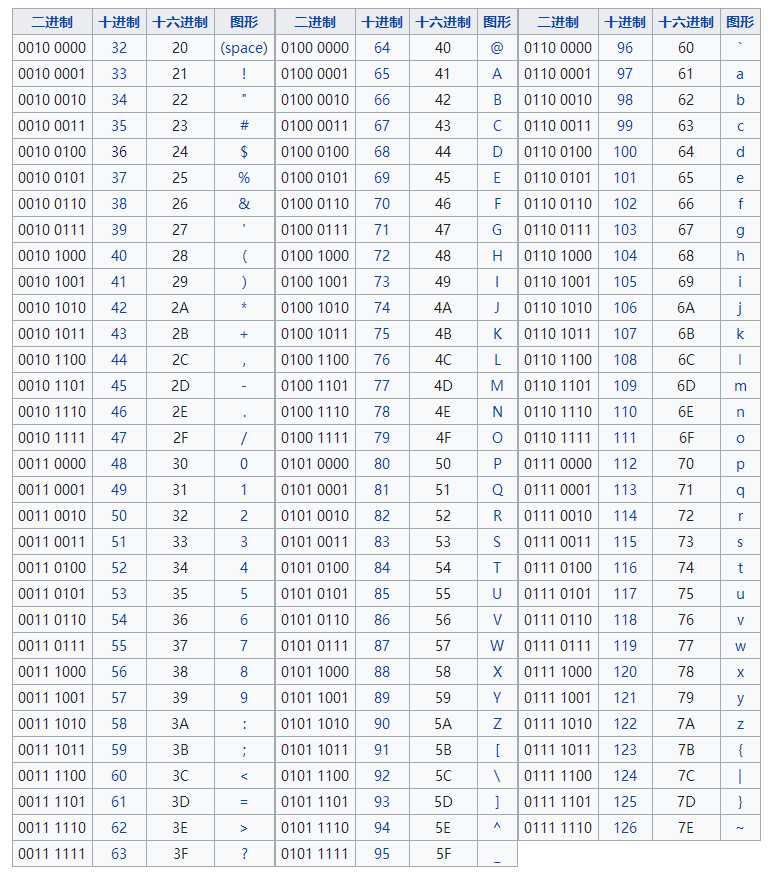
ASCII的局限在于只能显示26个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语
老美发明计算机,ASCII编码就满足使用了。但是计算机这么好的东西,世界人民都想使用,但是128个字符毛毛雨啊,完全不够用。so,开始各显神通,编码标准进入ANSI阶段
先来介绍下ANSI编码标准所规定的内容包含的含义:
Big5,1983年发布繁体中文通行区。
ANSI可谓编码界的战国时代,你搞你的,我搞我的。
中国有GBxxx,Big5
日本有Jis
英文有ASCII
...
不同的字符集标准是不能再多语环境下正常解析的。乱码是个大问题。
so,一个大一统的编码标准应运而生-Unicode
Unicode (万国码、国际码、统一码)。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字
位于美国加州的Unicode组织允许任何愿意支付会费的公司和个人加入,其成员包含了主要的电脑软硬件厂商,例如Adobe系统、苹果公司、惠普、IBM、微软、施乐等。
20世纪80年代末,组成 Unicode
组织的商业机构,和国际合作的国际标准化组织因为电脑普及和信息国际化的前提下,
分别各自成立了 Unicode 组织[3]和 ISO-10646 工作小组。他们不久便发现对方的存在,大家为着相同的目的而工作。1991
年,Unicode Consortium 与 ISO/IEC JTC1/SC2 同意保持 Unicode 码表与 ISO 10646 标准保持兼容并密切协调各自标准近一步的扩展。虽然实际上两者的字集编码相同,但
实质上两者确实为两个不同的标准。Unicode 1.1 对应于 ISO 10646-1:1993,Unicode 3.0 对应于 ISO 10646-1:2000,
Unicode 3.2 对应于 ISO 10646-2:2001,Unicode 4.0 对应于 ISO 10646:2003,Unicode 5.0 对应于 ISO 10646:2003Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式
此外还有 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用
几篇文章拼凑着看下来之后,对编码标准大致的有了一个了解。
参考文献
维基百科ASCII
阮一峰的网络日志
维基百科Unicode
国标GBxxxxxx参考百度百科
标签:gb2312 字符 class 兼容 www 如何 信息技术 ref 扩展
原文地址:https://www.cnblogs.com/JQKA/p/12133453.html