标签:aaa 数据类型 条件 res objects ESS 大小 多个 转义符
定义:
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等.
简单来说就是匹配字符或者字符串的一种规则,可以在很多特殊或者复杂的条件下进行匹配.再结合自身以及字符串的一些方法和函数,它的用途有时候很广.
如何创建正则表达式
1.字面量
const re = /ab+c/;
//以下是字符串的字面量,能看出区别了吧?最大的区别就是一个用//包含字符串,一个用‘‘包含,那他们等效吗?
const re = ‘ab+c‘;
2.RegExp(正则表达式)对象的构造函数
const re1 = new RegExp("ab+c");//仔细看是否就是字符串的字面量?下面讨论
我们接下来结合这两种创建方式来区分一下正则表达式的使用
特殊字符
正则表达式和普通字符串最大的区别就是字符串是死的,正则表达式是活的,更加灵活.
举个栗子:现有一字符串‘2020中国nb‘,我想找到里面的所有数字,用字符串怎么做?拿0-9的数字字符去一一匹配,显然代码很繁杂.所以死的不行,我就用活的.
如果我告诉你有一个字符就是表示0-9的所有数字字符,那是不是就不用一一去套了?直接一个字符就可以匹配了.刚好,确实有这么一个字符:\d 它表示只要是数字都能匹配等效于[0-9].
现在,用两种方式试写一下匹配0-9的字符的正则表达式
结果

match()是一个匹配方法,后面在细讲,这里就是去找原字符串中的数字然后打印出来.很明显,第一个和第三个没有达到预期效果,而且结果都一样.
结论:正则表达式的特殊字符不能直接放到引号中作为字符串去匹配
留下的问题有:
1.构造函数的参数是字符串吗?因为结果和直接用字符串的一样
2.构造函数里的参数是直接传正则表达式的字面量吗?
修改如下
const a = ‘aaadd123/=1a‘
const r = ‘\\d‘ //在原来的基础上多了个‘\‘转义符
const re = /\d/; //没变
const re1 = new RegExp(re) //放入正则字面量
const re2 = new RegExp(r) //放入有转义符的字符串
console.log(‘字符‘, a.match(r), a.match(re), a.match(re1),a.match(re2))
结果

综上所述,可得结论:
1.正则表达式的特殊字符不能直接放到引号中作为字符串去匹配,需要配合转义符使用.
2.用字面量,即//包含的特殊字符能被自动识别并转义,不需要加转义符.
3.构造函数的参数可以是包含转义符的字符串也可以直接是正则表达式的字面量.他们两者在这里是等效的.
而想\d这样的特殊字符在正则表达式中实际有很多个比如\S:非空字符等,所以我们在使用的过程中需要注意是否应该加转义符.简单的来说,就是,用/包含的字符不需要转义符/,用‘需要转义符‘.
特殊字符有
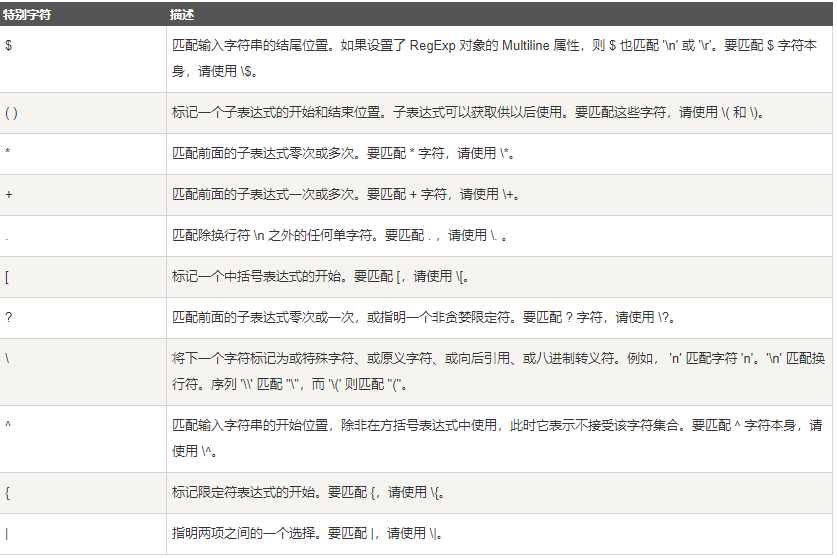
限定符(次数)
限定符也是特殊字符的一种,也是需要转义的.不过它的作用跟上面的字符不一样.

仔细看上面的打印结果,字符串‘aaadd123/=1a‘中实际有4个数字,但是只找到了一个,如果我需要限定匹配次数,比如我要匹配连续的3个数字.则需要写一些逻辑去实现.但是,正则表达式的限定符让这个需求变得更容易实现.
例如:
const a = ‘aaadd123/=1a‘
const re = /\d{3}/; //这里多了个{3}
console.log(‘字符‘, a.match(re))
结果

熟练使用限定符能减少不少逻辑代码

定位符(所在位置)
比如我想找以字符‘aa‘开头的字符串
const a = ‘aaadd123/=1a‘
const re = /aa/;
const re1 = /^aa/; //前面‘^‘表示以aa开头的字符串
console.log(‘字符‘, a.match(re), a.match(re1))
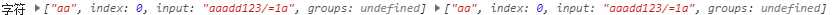
结果一样.是不是觉得有点奇怪,这两个怎么一样?跟我想的以‘aa‘开头的不一样?
那我换个条件
const a = ‘aaadd123/=1a‘
const re = /dd/;
const re1 = /^dd/;
console.log(‘字符‘, a.match(re), a.match(re1))
结果

所以如果定位符单独使用,它的意思更多是限定了后面字符串的位置,/^dd/的意思是给我找到位于字符串头部的‘dd‘.所以/^aa/有结果,而/^dd/没有.定位符相对的是原字符串的位置,而不是正则表达式里的位置.
错误示范:
/^dd\d{3}/ //这个可以匹配到‘dd123‘?不,并不能.
定位符有
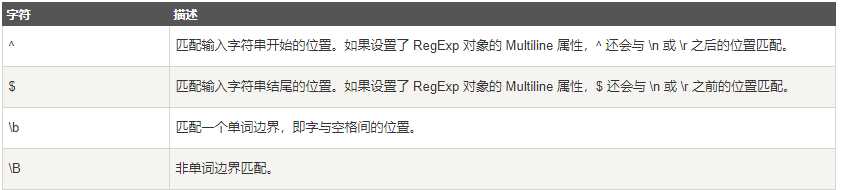
正则表达式标志
这个标志有点特殊,它不属于需要匹配的内容里面的.但它也是一种匹配规则.举例说明:我要匹配这个字符串里的所有‘a‘
const a = ‘aaadd123/=1a‘
const re = /a/g; //这里在两个/的后面多了个‘g‘,而不是在里面,这里表示全局匹配.
const re1 = new RegExp(‘a‘, ‘g‘) //我们可以发现,这里竟然多了个参数,因为这个全局匹配并不能像其他特殊字符可以放入第一个字符中用转义符去解析,所以单独多了一个参数.
console.log(‘字符‘, a.match(re), a.match(re1))
结果
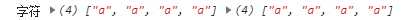
正则表达式的标志有
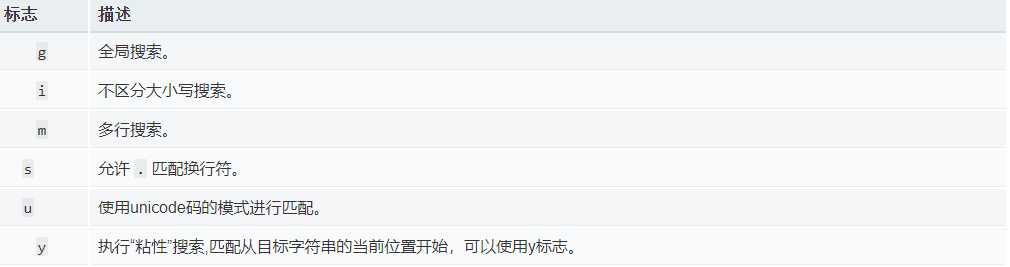
标志可以多个连用,比如‘ig‘则表示不去大小写的全局匹配.根据情况自定义.
很多情况下,是多个匹配规则结合起来使用的,因为单个匹配规则不少时候是能用字符串去实现的.复杂的情况下才使用正则表达式,而复杂的情况下是需要多个匹配规则配合的.
正则表达式方法
正则表达式实际上是一个对象,属于一种数据类型,而数据是需要拿来使用的,所以我们需要一些方法来使用它,比如之前一直在用的match就是其中一直.一下是相关方法.
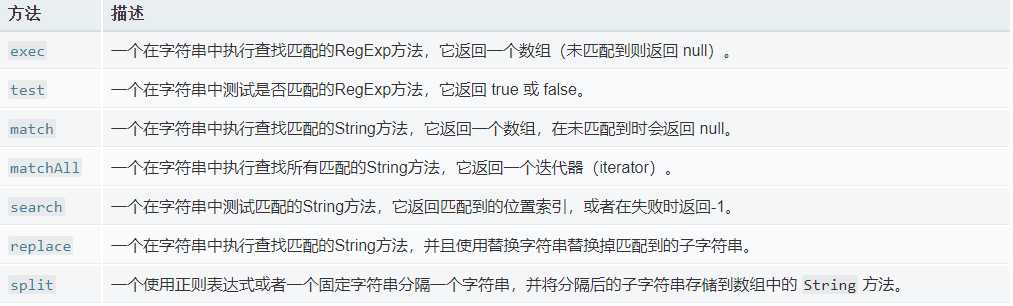
另外,正则表达式还有反向引用之类的匹配规则,由于太过复杂,暂不考虑.接下来实际操作一下.
案例实操
现有字符串‘aaadd123/=1Ad--A‘
需求1: 我需要拿到两个字符中间的字符串,比如‘a‘和‘=‘之间的字符串
//包含两个字符串
const a = ‘aaadd123/=1Ad--A‘ const re = /a\S*=/; const re1 = new RegExp(‘a\\S*=‘, ‘ig‘) console.log(‘字符‘, a.match(re), a.match(re1)) //aaadd123/=
//包含前面不包含后面
需求2:拿到‘d‘和第一个‘A‘之间有‘1‘的字符串,包不包含首位可以参考上面
这里的写法有很多,刚好可以对比一下熟悉一下写法
//re是一个以一个或者多个‘d‘开头,接下来有没有非空字符都可以,接着至少有一个‘1‘,最后以A结尾的字符串
const re = /d+\S*[1]+A/; //dd123/=1A
//re是一个以一个或者多个‘d‘开头,接下来有至少一个‘1‘然后后面有没有非空字符都可以,接下来有至少一个‘1‘,最后以‘A‘结尾
以上案例就差不多说明了正则表达式的使用注意点.
1:必须知道原字符串的一些特征才可以写出匹配规则.
2.别认为你的匹配规则是一个区间.你写的规则一定是包含你匹配到的所有字符的.当你只知道是非空字符,你可以用\S来表示,你不知道有几个,只要有可能有就得写*.不写的话,一旦有了就匹配不上了.
这点不好理解.还是举例说明
//注意这里的‘\S*‘和‘\S‘的区别 const re = /d+\S*[1]+A/; //dd123/=1A \S*表示有没有都可以有几个匹配几个,这里的非空字符实际上匹配到了‘d‘,‘1‘,‘2‘,‘3‘,‘/‘,‘=‘,所以它最终的匹配公式是/d+\S\S\S\S\S\S[1]+A const re = /d+\S[1]+A/; //null 这里就一个\S,也就是说‘d‘和‘1‘之间只能有一个非空字符,而明显,跟我们的字符串不匹配,自然是null const re = /d+[1]+A/; //null 这里的意思更明显,‘d‘后面必须接至少一个‘1‘然后后面接上‘A‘,不能有其他字符,所以匹配不到
关键还是得多加练习才能熟练使用.
标签:aaa 数据类型 条件 res objects ESS 大小 多个 转义符
原文地址:https://www.cnblogs.com/Shyno/p/11598504.html