标签:信息 def col 用处 inner 技术 ann min str
参考:https://blog.csdn.net/b1055077005/article/details/100152102 (文中所有公式均来自该bolg,侵删)
信息奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”,我们需要寻找一个量来衡量信息的有用程度。首先要先明确,这里的信息都指的是正确信息。
一件越不可能的事发生了,对其他人的用处就越大。比如:我的cvpr被拒稿了。这是一个极大概率事件,所以我跟你说的话,你会感觉:这还用你说?也就是说这句话对你没啥用。
但是如果我说:我cvpr被接收了。你肯定内心立刻被‘震’了一下子,说明这句话的信息量很大,所以,我们可以用一个量来描述信息的有用性,它就是信息量:I(x)=−log(P(x))
但是用信息量来衡量一件有一定概率发生的信息的有用程度是不合逻辑的,‘彩票中奖了’,‘太阳从西方升起’这种信息量很大的信息因为发生概率太小使其有用程度大打折扣。
明显,衡量信息有用程度的这个量需要有这样的性质:对于越不确定的信息,这个量应该越大。因此,定义一个新的量来衡量一定概率发生的信息,信息熵:
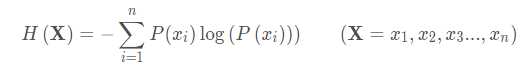
这实际上就是信息量的期望。

因此KL散度又称为相对熵。在深度学习中,信息熵是个定值,因此大多数情况下KL散度和交叉熵是等价的。
标签:信息 def col 用处 inner 技术 ann min str
原文地址:https://www.cnblogs.com/jiangnanyanyuchen/p/12148246.html