标签:nal val lam ali play size nali making pop
Problem with Large Weights
Large weights in a neural network are a sign of overfitting.
A network with large weights has very likely learned the statistical noise in the training data. This results in a model that is unstable, and very sensitive to changes to the input variables. In turn, the overfit network has poor performance when making predictions on new unseen data.
Regularization? A popular and effective technique to address the problem is to update the loss function that is optimized during training to take the size of the weights into account.
This is called a penalty, as the larger the weights of the network become, the more the network is penalized, resulting in larger loss and, in turn, larger updates. The effect is that the penalty encourages weights to be small, or no larger than is required during the training process, in turn reducing overfitting.
L1 and L2 norm

A linear regression model that implements L1 norm for regularisation is called lasso regression, and one that implements (squared) L2 norm for regularisation is called ridge regression.

Note: Strictly speaking, the last equation (ridge regression) is a loss function with squared L2 norm of the weights (notice the absence of the square root). When the Gradient Descent is used to update the weights, the rule is:
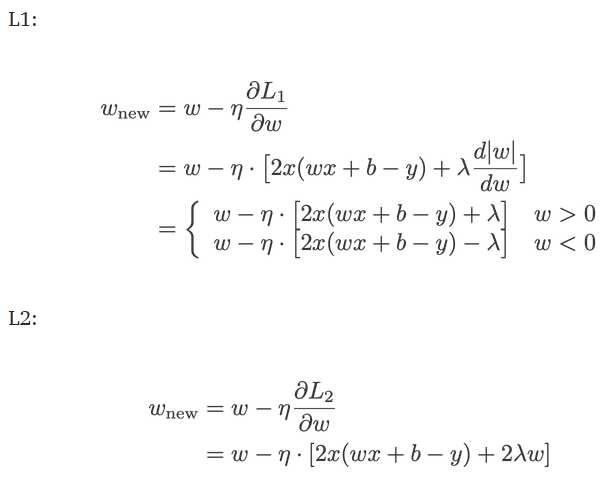
Compare the second term of each of the equation above. Apart from the derivative of original loss, the change in w depends on the ±λ term or the -2λw term. Both of them decrease the value of the weights.
Regularization from Large Wights Perspective
标签:nal val lam ali play size nali making pop
原文地址:https://www.cnblogs.com/rhyswang/p/12151425.html