标签:本质 input inpu 持续更新 做了 四种 code ali class
原文link: https://www.cnblogs.com/wzp-749195/p/11114624.html
深度学习大家都知道,在计算机视觉领域取得了很大的成功,在遥感影像自动解译方面,同样带来了快速的发展,我在遥感影像自动解译领域,也做了一些微薄的工作,发表几篇论文,我一直关注遥感影像自动解译领域,
在北京出差的这段时间,终于可以沉下心来,好好研究下深度学习,目前在语义分割领域,也有部分心得,在此同大家分享,权当是互相学习。本篇博文就是论述现有的state-of-art方法在遥感影像语义分割领域的进展,及以后的发展方向!
首先不多说,我采用当前效果表现最稳定、精度较高的几种语义分割网络进行讲述:1.unet网络;2.Deeplab网络(mobile特征提取器,resnet18特征提取器,resnet50特征提取器,Inceptionv3特征提取器等);3.CEnet。
下面我对这几种网络进行简单的讲解,单纯作为抛砖引玉,如有个别不当的地方,请看到的专家不吝赐教,Email:1044625113@qq.com,Phone:15211874660。如果大家需要全套遥感影像语义分割代码,同样可以联系我。
1.unet网络
unet网络由于形状像一个u型,因此称为Unet网络,关于它的资料,大家可以在CSDN的一篇博客找到,介绍的论文太多我就不细讲了!
它的形状如下图所示:
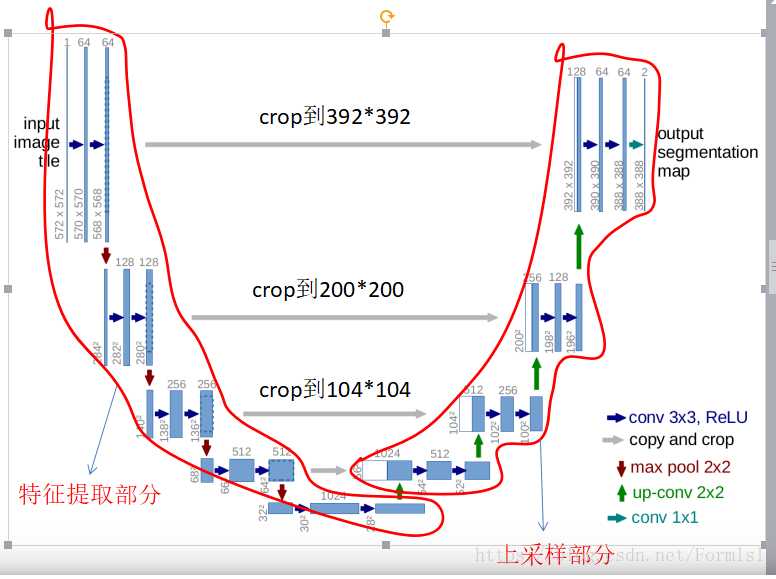
图1 unet语义分割网络(参考unetCSDN博客)
从它的形状,我们可以看出, 非常优美,这是原版论文的架构,我们可以在这个基础上进行大量的改进,比如说,特征提取块,我们可以采用残差网络(resnet)进行替换,这有什么好处呢?主要是可以加深网络,在防止梯度消失的同时,
可以学习到更深层次的特征,有利于提高精度。我看了几个版本的代码,在特征融合层,大家普遍采用两种方式,第一种直接相加,即将编码层与解码层特征直接相加,另外一种就是常用的concat,关于这两种有什么优缺点,我个人的理解是,
concat可以融合更多特征,其实说白了就是以前的向量相加(vector stacking),效果好的同时,GPU的显存肯定要消耗大;而对于特征相加的方式,直观的表现就是节省GPU显存,但是呢,是否比concat更好呢?我这里没有做实验,大家可以
跑跑代码试试!
2.Deeplab网络
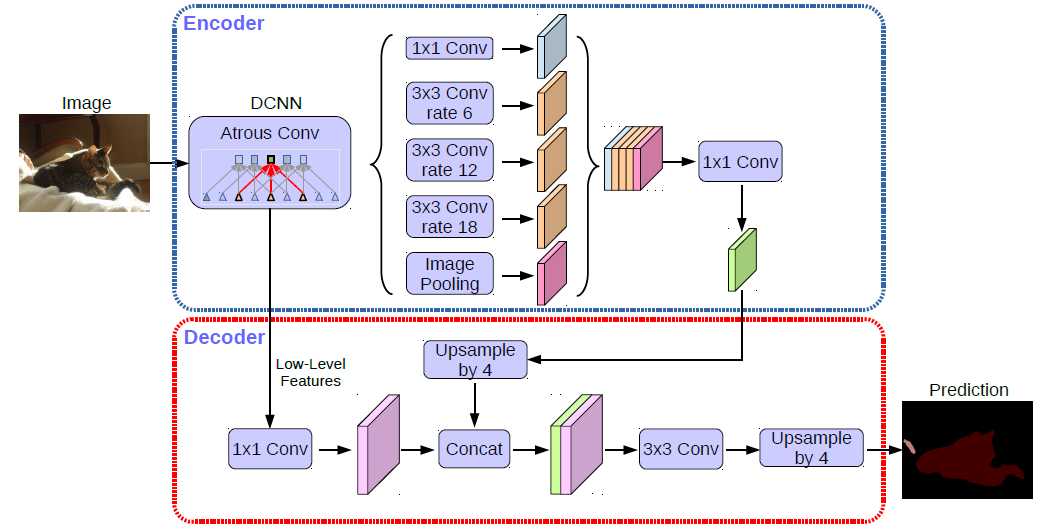
图3 DeeplabV3plus语义分割网络(参考原作者论文)
其实从Deeplab的网络可以看出,这个网络简单优美,没有那么多复杂的组合等等,最核心的东西就是四个空洞卷积块,卷积核的大小分别是1 6 12 18,关于作者为什么只用这四个参数呢,作者也只是用实验进行了说明,
证明了用这四个参数可以获得最高的精度,另外一种解析就是,不同大小的空洞卷积核可以感受不同范围的特征。第二个比较重要的地方,就是与四倍采样大小的特征进行concat,这个比较重要,它融合了编码层与解码层的
特征,从本质上来说,这个其实就是unet的变种,但是你可以自定义特征提取网络,例如我这里实现了mobilenet、inceptionv3,resnet18,resnet50等四种经典的特征提取网络。
关于DeeplabV3 里面的关键部分ASPP(空间金字塔池化),核心代码实现如下:

%% 创建空洞卷积空间金字塔网络,Deeplab的核心算法部分
function LayerGraph = ASPP_layer(LayerGraph)
% 创建ASPP层
dilate_size2 = 6;
dilate_size3 = 12;
dilate_size4 = 18;
% 尺度1空洞卷积层
convLayer_scale1 = convolution2dLayer(1,256,... % 1*1,原文为256个卷积核
‘Padding‘,‘same‘,...
‘BiasL2Factor‘,0,...
‘Name‘,‘convLayer_scale1‘);
% convLayer_scale1 = groupedConvolution2dLayer(1,1,40,‘Padding‘,‘same‘, ‘Name‘,‘convLayer_scale1‘);
bn_scale1 = batchNormalizationLayer(‘Name‘,‘bn_scale1‘);
% relu_scale1 = clippedReluLayer(6,‘Name‘,‘relu_scale1‘);
relu_scale1 = reluLayer(‘Name‘,‘relu_scale1‘);
scale_net1 = [convLayer_scale1;bn_scale1;relu_scale1];
% 尺度2空洞卷积层
convLayer_scale2 = convolution2dLayer(3,256,...
‘Padding‘,‘same‘,...
‘DilationFactor‘, dilate_size2,...
‘BiasL2Factor‘,0,...
‘Name‘,‘convLayer_scale2‘);
% convLayer_scale2 = groupedConvolution2dLayer(3,1,40,‘Padding‘,‘same‘, ‘DilationFactor‘, dilate_size2, ‘Name‘,‘convLayer_scale2‘);
bn_scale2 = batchNormalizationLayer(‘Name‘,‘bn_scale2‘);
% relu_scale2 = clippedReluLayer(6,‘Name‘,‘relu_scale2‘);
relu_scale2 = reluLayer(‘Name‘,‘relu_scale2‘);
scale_net2 = [convLayer_scale2;bn_scale2;relu_scale2];
% 尺度3空洞卷积层
convLayer_scale3 = convolution2dLayer(3,256,...
‘Padding‘,‘same‘,...
‘DilationFactor‘, dilate_size3,...
‘BiasL2Factor‘,0,...
‘Name‘,‘convLayer_scale3‘);
% convLayer_scale3 = groupedConvolution2dLayer(3,1,40,‘Padding‘,‘same‘, ‘DilationFactor‘, dilate_size3, ‘Name‘,‘convLayer_scale3‘);
bn_scale3 = batchNormalizationLayer(‘Name‘,‘bn_scale3‘);
% relu_scale3 = clippedReluLayer(6,‘Name‘,‘relu_scale3‘);
relu_scale3 = reluLayer(‘Name‘,‘relu_scale3‘);
scale_net3 = [convLayer_scale3;bn_scale3;relu_scale3];
% 尺度4空洞卷积层
convLayer_scale4 = convolution2dLayer(3,256,...
‘Padding‘,‘same‘,...
‘DilationFactor‘, dilate_size4,...
‘BiasL2Factor‘,0,...
‘Name‘,‘convLayer_scale4‘);
% convLayer_scale4 = groupedConvolution2dLayer(3,1,40,‘Padding‘,‘same‘, ‘DilationFactor‘, dilate_size4, ‘Name‘,‘convLayer_scale4‘);
bn_scale4 = batchNormalizationLayer(‘Name‘,‘bn_scale4‘);
% relu_scale4 = clippedReluLayer(6,‘Name‘,‘relu_scale4‘);
relu_scale4 = reluLayer(‘Name‘,‘relu_scale4‘);
scale_net4 = [convLayer_scale4; bn_scale4; relu_scale4];
% 组合原来的layer
LayerGraph = addLayers(LayerGraph, scale_net1);
LayerGraph = addLayers(LayerGraph, scale_net2 );
LayerGraph = addLayers(LayerGraph, scale_net3);
LayerGraph = addLayers(LayerGraph, scale_net4);
LayerGraph = connectLayers(LayerGraph, ‘mixed10‘, ‘convLayer_scale1‘);
LayerGraph = connectLayers(LayerGraph, ‘mixed10‘, ‘convLayer_scale2‘);
LayerGraph = connectLayers(LayerGraph, ‘mixed10‘, ‘convLayer_scale3‘);
LayerGraph = connectLayers(LayerGraph, ‘mixed10‘, ‘convLayer_scale4‘);
catFeature4 = depthConcatenationLayer(4,‘Name‘,"dec_cat_aspp"); % 融合多特征
LayerGraph = addLayers(LayerGraph, catFeature4);
LayerGraph = connectLayers(LayerGraph, ‘relu_scale1‘, ‘dec_cat_aspp/in1‘);
LayerGraph = connectLayers(LayerGraph, ‘relu_scale2‘, ‘dec_cat_aspp/in2‘);
LayerGraph = connectLayers(LayerGraph, ‘relu_scale3‘, ‘dec_cat_aspp/in3‘);
LayerGraph = connectLayers(LayerGraph, ‘relu_scale4‘, ‘dec_cat_aspp/in4‘);
% 卷积层降低参数个数
convLayer_input = convolution2dLayer(1,256,... % 1*1卷积就是为了降低参数个数
‘Stride‘,[1 1],...
‘Padding‘,1,...
‘BiasL2Factor‘,0,...
‘Name‘,‘Conv_block16‘);
bn_layer1 = batchNormalizationLayer(‘Name‘,‘bn_block16‘);
% relu_layer1 = clippedReluLayer(6,‘Name‘,‘relu_block16‘);
relu_layer1 = reluLayer(‘Name‘,‘relu_block16‘);
con_net = [convLayer_input; bn_layer1; relu_layer1];
LayerGraph = addLayers(LayerGraph, con_net);
LayerGraph = connectLayers(LayerGraph, ‘dec_cat_aspp‘, ‘Conv_block16‘);
% 向上采样四倍
deconvLayer = transposedConv2dLayer(8,256,... % 8*8
‘Stride‘,[4 4],... % 四倍大小
‘Cropping‘,‘same‘,...
‘BiasL2Factor‘,0,...
‘Name‘,‘deconv_1‘);
decon_net = [deconvLayer;
batchNormalizationLayer(‘Name‘,‘de_batch_1‘);
reluLayer(‘Name‘,‘de_relu_1‘)];
% clippedReluLayer(6,‘Name‘,‘de_relu_1‘)];
LayerGraph = addLayers(LayerGraph, decon_net);
LayerGraph = connectLayers(LayerGraph, ‘relu_block16‘, ‘deconv_1‘);
end
这一段ASPP代码是我根据作者论文的原版实现,同时也参考了pytorch、keras、caffee等不同框架的实现代码,大家可以直接使用!
3.CEnet网络
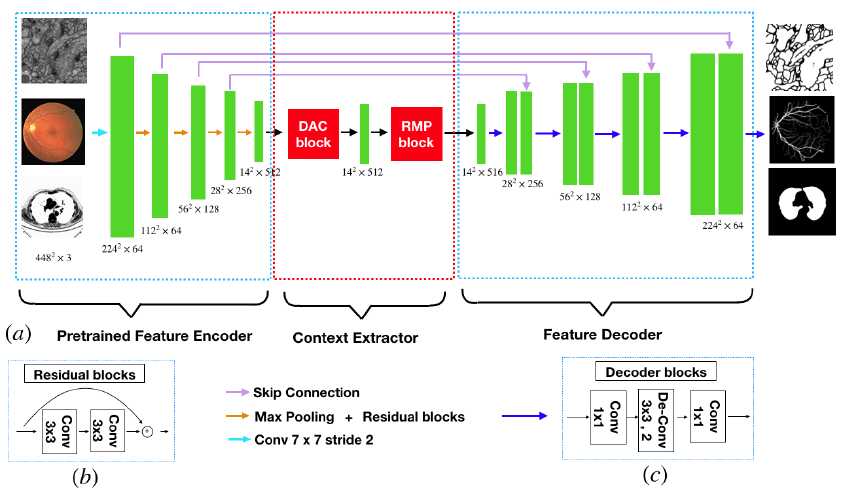
图2 CEet语义分割网络(参考原作者论文)
CEnet这个网络主要是用到医学图像分割里面,发表在IEEE 的医学权威期刊,这个网络我第一眼就感觉特别熟悉,仔细一看,这不就是PSPnet的变种吗?后面组合了多个不同的最大池化层特征,前面组合了Deeplab里面的多尺度空洞卷积,
我觉得这里面比较有意思的地方在于,作者的空洞卷积核大小,由于血管比较小,因此作者的空洞卷积核并不大,最大只有5,这跟Deeplab的参数有较大的不同,作者这种设计网络的方式值得我们去学习,例如,我们只需要提取遥感影像上的
道路网络,我们是否真的需要那么的空洞卷积核呢??不需要!因此我们应当针对遥感影像地物的特征,设计不同的网络参数,这样才能取得一个比较好的精度!(纯属个人思想,如有不当之处,请高手指正!phone:15211874660,Email:1044625113)
关于CEnet的全部代码实现,参见我的github网站(https://github.com/wzp8023391/CEnet,如果觉得好,请大家手动点个星星。。。)
4.其他网络
其他的语义分割网络,如PSPnet等网络,我这里不再多说,大家可以去看论文。回过头来看,大家有没有发现一个问题?就是目前所有的语义分割网络都是人工设计的!关于它表现的怎么样,谁知道呢,跑跑实验,行就行,不行就拉倒,
结果就出现了大量的“水”论文,(原谅我用了这个词,毕竟当年为了毕业,我也干了这种事),我举一个例子,CEnet里面的膨胀卷积+最大池化,为什么要设这个参数,为什么要这么干,作者其实自己并没有完全讲清楚,当然用实验证明也是
可以的,但是我们更讲究理论,这也是深度学习令人诟病的一个重点地方。手工设计的网络跟当年手工设计特征,何其相似!当然了大牛永远是大牛,LI feifei老师提出的auto Deeplearning我个人其实最看好的,下面就是一个自动化语义分割网络的
示例图,大家可以看看(CVPR2019 oral),这里面关键的地方就是自动寻找最优的网络组合,从而得到最优的语义分割网络,这个就非常有意思,这是以后语义分割一个指向灯!
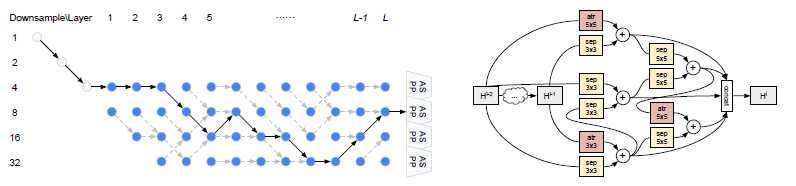
图3 AutoDeeplab语义分割网络(参考原作者论文)
5.实验总结
我们以开源的全地物分类为例,对这几种经典的网络进行对比说明:

图4 原始真彩色高分辨率影像

图5 使用Inceptionv3作为特征提取的DeepLabv3+语义分割结果
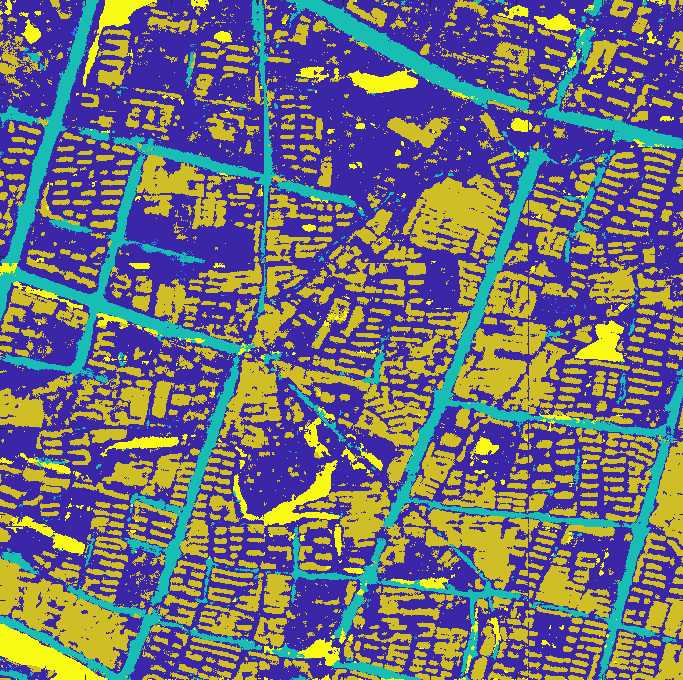
图6 使用mobilenetv2作为特征提取的DeepLabv3+语义分割结果
从上面三个结果来看,Inceptionv3作为特征提取器要好于mobilenetv2网络,分割效率方面,mobilenet是Inception的三倍左右,效率还是非常高的。当然了,对于精度与效率是看大家的各自需求了!
先写到这里,有空再持续更新,qq:1044625113,加qq时,请备注(语义分割交流)!
标签:本质 input inpu 持续更新 做了 四种 code ali class
原文地址:https://www.cnblogs.com/xiexiaokui/p/12151688.html