标签:tco zed rap windows win idt 依次 lua 识别
一、数据集介绍
数据来源:今日头条客户端
数据格式如下:
6551700932705387022_!_101_!_news_culture_!_京城最值得你来场文化之旅的博物馆_!_保利集团,马未都,中国科学技术馆,博物馆,新中国
6552368441838272771_!_101_!_news_culture_!_发酵床的垫料种类有哪些?哪种更好?_!_
6552407965343678723_!_101_!_news_culture_!_上联:黄山黄河黄皮肤黄土高原。怎么对下联?_!_
6552332417753940238_!_101_!_news_culture_!_林徽因什么理由拒绝了徐志摩而选择梁思成为终身伴侣?_!_
6552475601595269390_!_101_!_news_culture_!_黄杨木是什么树?_!_每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词
分类code与名称:
100 民生 故事 news_story
101 文化 文化 news_culture
102 娱乐 娱乐 news_entertainment
103 体育 体育 news_sports
104 财经 财经 news_finance
106 房产 房产 news_house
107 汽车 汽车 news_car
108 教育 教育 news_edu
109 科技 科技 news_tech
110 军事 军事 news_military
112 旅游 旅游 news_travel
113 国际 国际 news_world
114 证券 股票 stock
115 农业 三农 news_agriculture
116 电竞 游戏 news_gamegithub地址:https://github.com/fate233/toutiao-text-classfication-dataset
数据资源中给出了分类的实验结果:
Test Loss: 0.57, Test Acc: 83.81%
precision recall f1-score support
news_story 0.66 0.75 0.70 848
news_culture 0.57 0.83 0.68 1531
news_entertainment 0.86 0.86 0.86 8078
news_sports 0.94 0.91 0.92 7338
news_finance 0.59 0.67 0.63 1594
news_house 0.84 0.89 0.87 1478
news_car 0.92 0.90 0.91 6481
news_edu 0.71 0.86 0.77 1425
news_tech 0.85 0.84 0.85 6944
news_military 0.90 0.78 0.84 6174
news_travel 0.58 0.76 0.66 1287
news_world 0.72 0.69 0.70 3823
stock 0.00 0.00 0.00 53
news_agriculture 0.80 0.88 0.84 1701
news_game 0.92 0.87 0.89 6244
avg / total 0.85 0.84 0.84 54999
下面我们就来用deeplearning4j来实现一个卷积结构对该数据集进行分类,看能不能得到更好的结果。
二、卷积网络可以用于文本处理的原因
CNN非常适合处理图像数据,前面一篇文章《deeplearning4j——卷积神经网络对验证码进行识别》介绍了CNN对验证码进行识别。本篇博客将利用CNN对文本进行分类,在开始之前我们先来直观的说说卷积运算在做的本质事情是什么。卷积运算,本质上可以看做两个向量的点积,两个向量越同向,点积就越大,经过relu和MaxPooling之后,本质上是提取了与卷积核最同向的结构,这个“结构”实际上是图片上的一些线条。
那么文本可以用CNN来处理吗?答案是肯定的,文本每个词用向量表示之后,依次排开,就变成了一张二维图,如下图,沿着红色箭头的方向(也就是文本的方向)看,两个句子用一幅图表示之后,会出现相同的单元,也就可以用CNN来处理。
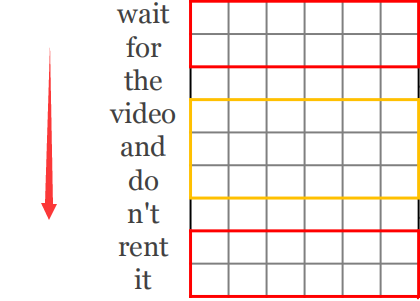
三、文本处理的卷积结构
那么,怎么设计这个CNN网络结构呢?如下图:(论文地址:https://arxiv.org/abs/1408.5882)
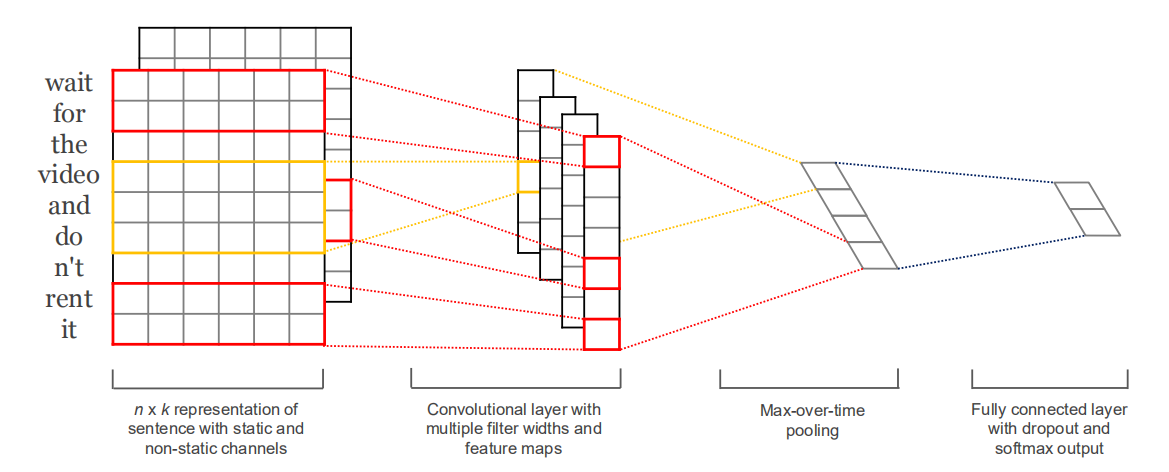
注意点:
1、卷积核移动的方向必须为句子的方向
2、每个卷积核提取的特征为N行1列的向量
3、MaxPooling的操作的对象是每一个Feature Map,也就是从每一个N行1列的向量中选择一个最大值
4、把选择的所有最大值接起来,经过几个Fully Connected 层,进行分类
四、数据的预处理与词向量
1、分词工具:HanLP
2、处理后的数据格式如下:(类别code_!_词,其中,词与词之间用空格隔开,_!_为分割符)

数据预处理代码如下:
public static void main(String[] args) throws Exception {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(
new FileInputStream(new File("/toutiao_cat_data/toutiao_cat_data.txt")), "UTF-8"));
OutputStreamWriter writerStream = new OutputStreamWriter(
new FileOutputStream("/toutiao_cat_data/toutiao_data_type_word.txt"), "UTF-8");
BufferedWriter writer = new BufferedWriter(writerStream);
String line = null;
long startTime = System.currentTimeMillis();
while ((line = bufferedReader.readLine()) != null) {
String[] array = line.split("_!_");
StringBuilder stringBuilder = new StringBuilder();
for (Term term : HanLP.segment(array[3])) {
if (stringBuilder.length() > 0) {
stringBuilder.append(" ");
}
stringBuilder.append(term.word.trim());
}
writer.write(Integer.parseInt(array[1].trim()) + "_!_" + stringBuilder.toString() + "\n");
}
writer.flush();
writer.close();
System.out.println(System.currentTimeMillis() - startTime);
bufferedReader.close();
}五、词的向量表示
1、one-hot
用正交的向量来表示每一个词,这样表示无法反应词与词之间的关系,那么两句话中,要想复用同一个卷积核,那么必须出现一模一样的词才可以,实际上,我们要求模型可以举一反三,连相似的结构也可以提取,那么word2vec可以解决这个问题。
2、word2vec
word2vec可以充分考虑词与词之间的关系,相似的词,肯定有某些维度靠的比较近。那么也就考虑了词的语句之间的关系,训练word2vec有两种,skipgram和cbow,下面我们用cbow来训练词向量,结果会持久化下来,就得到了toutiao.vec的文件,下次变可重新加载该文件获得词的向量表示,代码如下:
String filePath = new ClassPathResource("toutiao_data_word.txt").getFile().getAbsolutePath();
SentenceIterator iter = new BasicLineIterator(filePath);
TokenizerFactory t = new DefaultTokenizerFactory();
t.setTokenPreProcessor(new CommonPreprocessor());
VocabCache<VocabWord> cache = new AbstractCache<>();
WeightLookupTable<VocabWord> table = new InMemoryLookupTable.Builder<VocabWord>().vectorLength(100)
.useAdaGrad(false).cache(cache).build();
log.info("Building model....");
Word2Vec vec = new Word2Vec.Builder()
.elementsLearningAlgorithm("org.deeplearning4j.models.embeddings.learning.impl.elements.CBOW")
.minWordFrequency(0).iterations(1).epochs(20).layerSize(100).seed(42).windowSize(8).iterate(iter)
.tokenizerFactory(t).lookupTable(table).vocabCache(cache).build();
vec.fit();
WordVectorSerializer.writeWord2VecModel(vec, "/toutiao_cat_data/toutiao.vec");六、CNN网络结构
CNN网络结构如下:
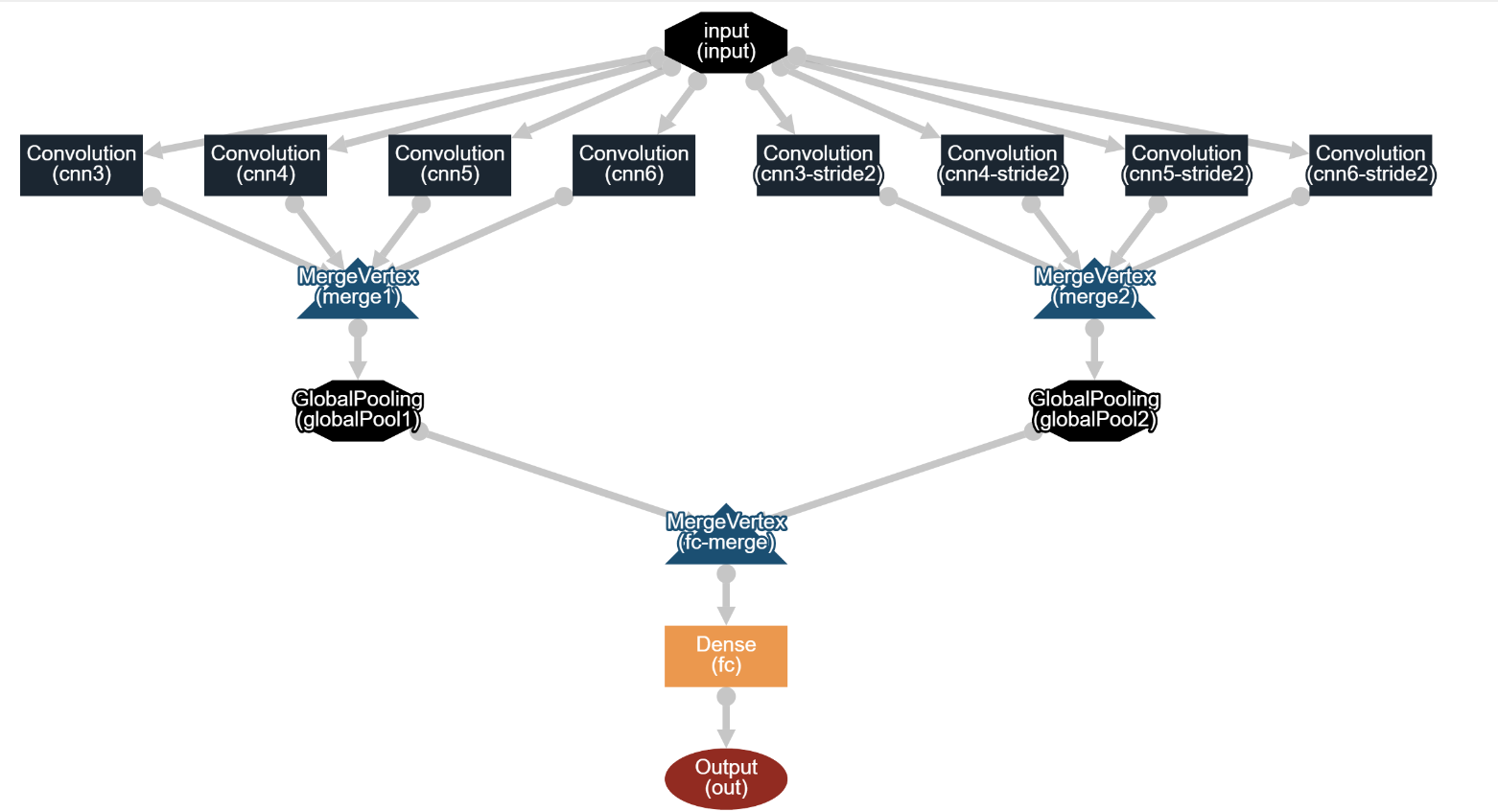
说明:
1、cnn3、cnn4、cnn5、cnn6卷积核大小为(3,vectorSize)、(4,vectorSize)、(5,vectorSize)、(6,vectorSize),步幅为1,也就是分别读取3、4、5、6个词,提取特征
2、cnn3-stride2、cnn4-stride2、cnn5-stride2、cnn6-stride2卷积核大小为(3,vectorSize)、(4,vectorSize)、(5,vectorSize)、(6,vectorSize),步幅为2
3、两组卷积核卷积的结果合并,分别得到merge1和merge2,都是4维张量,形状分别为(batchSize,depth1+depth2+depth3,height/1,1),(batchSize,depth1+depth2+depth3,height/2,1),特别说明:这里的卷积模式为ConvolutionMode.Same
4、merge1、2分别经过MaxPooling,这里用的是GlobalPoolingLayer,和平台的Pooling层不同,这里会从指定维度中,取一个最大值,所以经过GlobalPoolingLayer之后,merge1、2分别变成2维张量,形状为(batchSize,depth1+depth2+depth3),那么GlobalPoolingLayer是如何求Max的呢?源码如下:
private INDArray activateHelperFullArray(INDArray inputArray, int[] poolDim) {
switch (poolingType) {
case MAX:
return inputArray.max(poolDim);
case AVG:
return inputArray.mean(poolDim);
case SUM:
return inputArray.sum(poolDim);
case PNORM:
//P norm: https://arxiv.org/pdf/1311.1780.pdf
//out = (1/N * sum( |in| ^ p) ) ^ (1/p)
int pnorm = layerConf().getPnorm();
INDArray abs = Transforms.abs(inputArray, true);
Transforms.pow(abs, pnorm, false);
INDArray pNorm = abs.sum(poolDim);
return Transforms.pow(pNorm, 1.0 / pnorm, false);
default:
throw new RuntimeException("Unknown or not supported pooling type: " + poolingType + " " + layerId());
}
}5、两边GlobalPoolingLayer结果再接起来,丢给全连接网络,经过softmax分类器进行分类
6、fc层,用了0.5的dropout防止过拟合,在下面的代码中可以看到。
完整代码如下:
public class CnnSentenceClassificationTouTiao {
public static void main(String[] args) throws Exception {
List<String> trainLabelList = new ArrayList<>();// 训练集label
List<String> trainSentences = new ArrayList<>();// 训练集文本集合
List<String> testLabelList = new ArrayList<>();// 测试集label
List<String> testSentences = new ArrayList<>();//// 测试集文本集合
Map<String, List<String>> map = new HashMap<>();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(
new FileInputStream(new File("/toutiao_cat_data/toutiao_data_type_word.txt")), "UTF-8"));
String line = null;
int truncateReviewsToLength = 0;
Random random = new Random(123);
while ((line = bufferedReader.readLine()) != null) {
String[] array = line.split("_!_");
if (map.get(array[0]) == null) {
map.put(array[0], new ArrayList<String>());
}
map.get(array[0]).add(array[1]);// 将样本中所有数据,按照类别归类
int length = array[1].split(" ").length;
if (length > truncateReviewsToLength) {
truncateReviewsToLength = length;// 求样本中,句子的最大长度
}
}
bufferedReader.close();
for (Map.Entry<String, List<String>> entry : map.entrySet()) {
for (String sentence : entry.getValue()) {
if (random.nextInt() % 5 == 0) {// 每个类别抽取20%作为test集
testLabelList.add(entry.getKey());
testSentences.add(sentence);
} else {
trainLabelList.add(entry.getKey());
trainSentences.add(sentence);
}
}
}
int batchSize = 64;
int vectorSize = 100;
int nEpochs = 10;
int cnnLayerFeatureMaps = 50;
PoolingType globalPoolingType = PoolingType.MAX;
Random rng = new Random(12345);
Nd4j.getMemoryManager().setAutoGcWindow(5000);
ComputationGraphConfiguration config = new NeuralNetConfiguration.Builder().weightInit(WeightInit.RELU)
.activation(Activation.LEAKYRELU).updater(new Nesterovs(0.01, 0.9))
.convolutionMode(ConvolutionMode.Same).l2(0.0001).graphBuilder().addInputs("input")
.addLayer("cnn3",
new ConvolutionLayer.Builder().kernelSize(3, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn4",
new ConvolutionLayer.Builder().kernelSize(4, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn5",
new ConvolutionLayer.Builder().kernelSize(5, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn6",
new ConvolutionLayer.Builder().kernelSize(6, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn3-stride2",
new ConvolutionLayer.Builder().kernelSize(3, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn4-stride2",
new ConvolutionLayer.Builder().kernelSize(4, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn5-stride2",
new ConvolutionLayer.Builder().kernelSize(5, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn6-stride2",
new ConvolutionLayer.Builder().kernelSize(6, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addVertex("merge1", new MergeVertex(), "cnn3", "cnn4", "cnn5", "cnn6")
.addLayer("globalPool1", new GlobalPoolingLayer.Builder().poolingType(globalPoolingType).build(),
"merge1")
.addVertex("merge2", new MergeVertex(), "cnn3-stride2", "cnn4-stride2", "cnn5-stride2", "cnn6-stride2")
.addLayer("globalPool2", new GlobalPoolingLayer.Builder().poolingType(globalPoolingType).build(),
"merge2")
.addLayer("fc",
new DenseLayer.Builder().nOut(200).dropOut(0.5).activation(Activation.LEAKYRELU).build(),
"globalPool1", "globalPool2")
.addLayer("out",
new OutputLayer.Builder().lossFunction(LossFunctions.LossFunction.MCXENT)
.activation(Activation.SOFTMAX).nOut(15).build(),
"fc")
.setOutputs("out").setInputTypes(InputType.convolutional(truncateReviewsToLength, vectorSize, 1))
.build();
ComputationGraph net = new ComputationGraph(config);
net.init();
System.out.println(net.summary());
Word2Vec word2Vec = WordVectorSerializer.readWord2VecModel("/toutiao_cat_data/toutiao.vec");
System.out.println("Loading word vectors and creating DataSetIterators");
DataSetIterator trainIter = getDataSetIterator(word2Vec, batchSize, truncateReviewsToLength, trainLabelList,
trainSentences, rng);
DataSetIterator testIter = getDataSetIterator(word2Vec, batchSize, truncateReviewsToLength, testLabelList,
testSentences, rng);
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
net.setListeners(new ScoreIterationListener(100), new StatsListener(statsStorage, 20),
new EvaluativeListener(testIter, 1, InvocationType.EPOCH_END));
// net.setListeners(new ScoreIterationListener(100),
// new EvaluativeListener(testIter, 1, InvocationType.EPOCH_END));
net.fit(trainIter, nEpochs);
}
private static DataSetIterator getDataSetIterator(WordVectors wordVectors, int minibatchSize, int maxSentenceLength,
List<String> lableList, List<String> sentences, Random rng) {
LabeledSentenceProvider sentenceProvider = new CollectionLabeledSentenceProvider(sentences, lableList, rng);
return new CnnSentenceDataSetIterator.Builder().sentenceProvider(sentenceProvider).wordVectors(wordVectors)
.minibatchSize(minibatchSize).maxSentenceLength(maxSentenceLength).useNormalizedWordVectors(false)
.build();
}
}
代码说明:
1、代码分两部分,第一部分是数据预处理,分出20%测试集、80%作为训练集
2、第二部分为网络的基本结构代码
网络参数详细如下:
===============================================================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
===============================================================================================================================================
input (InputVertex) -,- - - -
cnn3 (ConvolutionLayer) 1,50 15050 W:{50,1,3,100}, b:{1,50} [input]
cnn4 (ConvolutionLayer) 1,50 20050 W:{50,1,4,100}, b:{1,50} [input]
cnn5 (ConvolutionLayer) 1,50 25050 W:{50,1,5,100}, b:{1,50} [input]
cnn6 (ConvolutionLayer) 1,50 30050 W:{50,1,6,100}, b:{1,50} [input]
cnn3-stride2 (ConvolutionLayer) 1,50 15050 W:{50,1,3,100}, b:{1,50} [input]
cnn4-stride2 (ConvolutionLayer) 1,50 20050 W:{50,1,4,100}, b:{1,50} [input]
cnn5-stride2 (ConvolutionLayer) 1,50 25050 W:{50,1,5,100}, b:{1,50} [input]
cnn6-stride2 (ConvolutionLayer) 1,50 30050 W:{50,1,6,100}, b:{1,50} [input]
merge1 (MergeVertex) -,- - - [cnn3, cnn4, cnn5, cnn6]
merge2 (MergeVertex) -,- - - [cnn3-stride2, cnn4-stride2, cnn5-stride2, cnn6-stride2]
globalPool1 (GlobalPoolingLayer) -,- 0 - [merge1]
globalPool2 (GlobalPoolingLayer) -,- 0 - [merge2]
fc-merge (MergeVertex) -,- - - [globalPool1, globalPool2]
fc (DenseLayer) 400,200 80200 W:{400,200}, b:{1,200} [fc-merge]
out (OutputLayer) 200,15 3015 W:{200,15}, b:{1,15} [fc]
-----------------------------------------------------------------------------------------------------------------------------------------------
Total Parameters: 263615
Trainable Parameters: 263615
Frozen Parameters: 0
===============================================================================================================================================
DL4J的UIServer界面如下,这里我给定的端口号为9001,打开web界面可以看到平均loss的详情,梯度更新的详情等
http://localhost:9001/train/overview
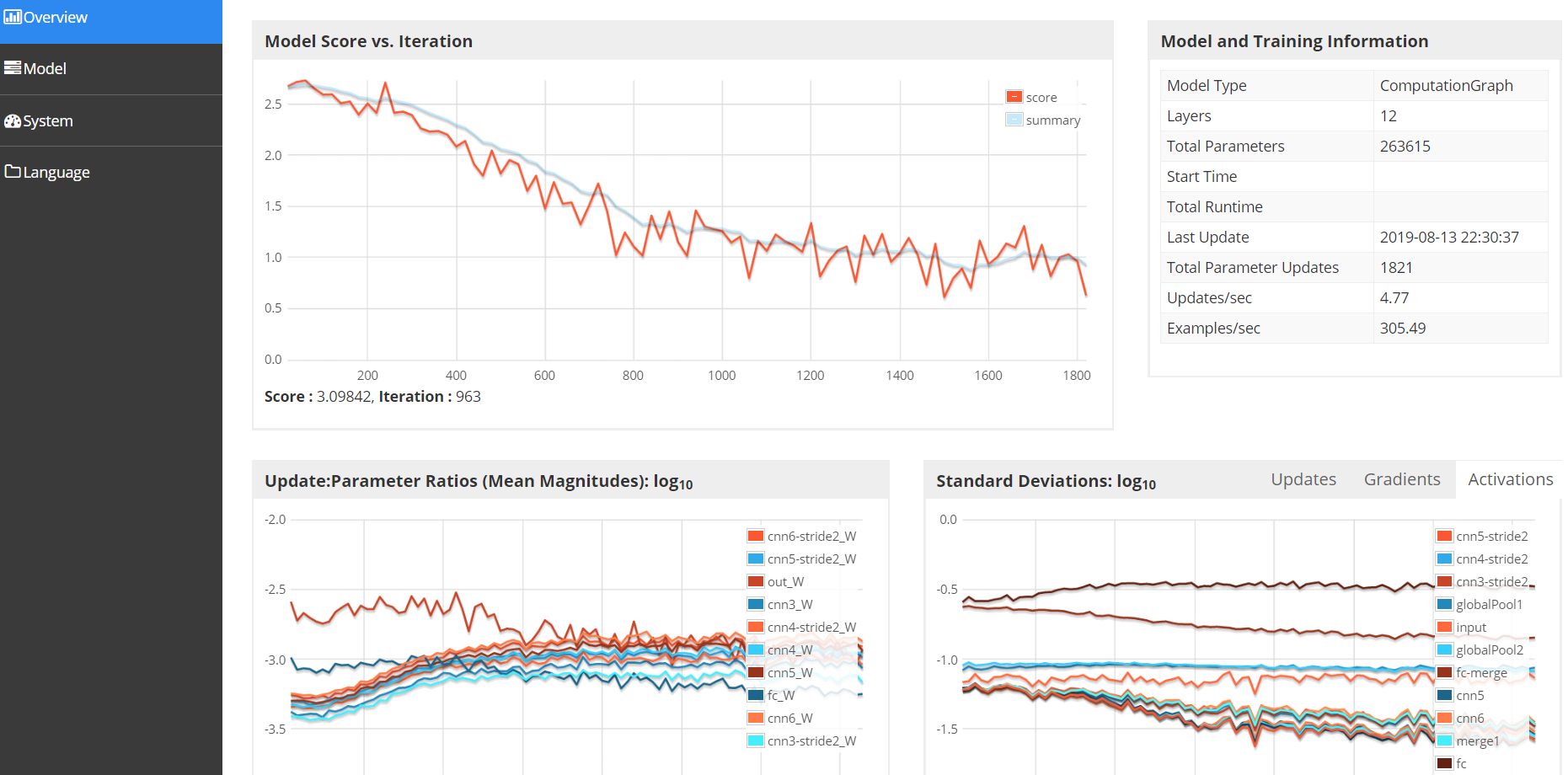
七、掩模
句子有长有短,CNN将如何处理呢?
处理的办法其实很暴力,将一个minibatch中的最长句子找到,new出最大长度的张量,多余值用掩模掩掉即可,废话不多说,直接上代码
if(sentencesAlongHeight){
featuresMask = Nd4j.create(currMinibatchSize, 1, maxLength, 1);
for (int i = 0; i < currMinibatchSize; i++) {
int sentenceLength = tokenizedSentences.get(i).getFirst().size();
if (sentenceLength >= maxLength) {
featuresMask.slice(i).assign(1.0);
} else {
featuresMask.get(NDArrayIndex.point(i), NDArrayIndex.point(0), NDArrayIndex.interval(0, sentenceLength), NDArrayIndex.point(0)).assign(1.0);
}
}
} else {
featuresMask = Nd4j.create(currMinibatchSize, 1, 1, maxLength);
for (int i = 0; i < currMinibatchSize; i++) {
int sentenceLength = tokenizedSentences.get(i).getFirst().size();
if (sentenceLength >= maxLength) {
featuresMask.slice(i).assign(1.0);
} else {
featuresMask.get(NDArrayIndex.point(i), NDArrayIndex.point(0), NDArrayIndex.point(0), NDArrayIndex.interval(0, sentenceLength)).assign(1.0);
}
}
}这里为什么有个if呢?生成句子张量的时候,可以任意指定句子的方向,可以沿着矩阵中height的方向,也可以是width的方向,方向不同,填掩模的那一维也就不同。
八、结果
运行了10个Epoch结果如下:
========================Evaluation Metrics========================
# of classes: 15
Accuracy: 0.8420
Precision: 0.8362 (1 class excluded from average)
Recall: 0.7783
F1 Score: 0.8346 (1 class excluded from average)
Precision, recall & F1: macro-averaged (equally weighted avg. of 15 classes)
Warning: 1 class was never predicted by the model and was excluded from average precision
Classes excluded from average precision: [12]
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
----------------------------------------------------------------------------
973 35 114 2 9 8 11 19 14 6 19 11 0 22 13 | 0 = 0
17 4636 250 37 51 16 14 151 47 29 232 36 0 82 44 | 1 = 1
103 176 6980 108 16 8 31 62 83 41 53 77 0 36 163 | 2 = 2
9 78 244 6692 37 9 52 59 33 27 57 54 0 10 96 | 3 = 3
7 52 36 31 4072 96 101 107 581 20 64 108 0 135 37 | 4 = 4
12 18 22 8 150 3061 27 36 53 2 100 16 0 56 2 | 5 = 5
17 38 71 26 94 13 6443 43 174 31 121 39 0 32 34 | 6 = 6
17 157 93 49 62 20 34 4793 85 14 58 36 0 49 31 | 7 = 7
1 45 71 21 436 30 195 138 7018 48 54 49 0 45 148 | 8 = 8
24 74 84 47 24 1 57 50 68 3963 45 431 0 9 65 | 9 = 9
9 165 90 21 40 37 61 40 42 21 3428 111 0 78 30 | 10 = 10
47 78 173 52 114 20 48 67 93 320 140 4097 0 48 29 | 11 = 11
0 0 0 0 60 0 1 0 5 0 0 0 0 0 0 | 12 = 12
35 105 31 6 139 37 34 61 79 11 153 35 0 3187 12 | 13 = 13
14 36 210 128 31 2 19 20 164 44 38 15 0 19 5183 | 14 = 14平均准确率0.8420,比原资源中给定的结果略好,F1 score要略差一点,混淆矩阵中,有一个类别,无法被预测到,是因为样本中改类别数据量本身很少,难以抓到共性特征。这里参数如果精心调节一番,迭代更多次数,理论上会有更好的表现。
九、后记
读Deeplearning4j是一种享受,优雅的架构,清晰的逻辑,多种设计模式,扩展性强,将有后续博客,对dl4j源码进行剖析。
快乐源于分享。
此博客乃作者原创, 转载请注明出处
标签:tco zed rap windows win idt 依次 lua 识别
原文地址:https://www.cnblogs.com/dongshenjun/p/12154434.html