标签:lam shuffle 选择 ORC 复杂度 RKE nbsp 整合 etl
下面要说的基本都是《动手学深度学习》这本花书上的内容,图也采用的书上的
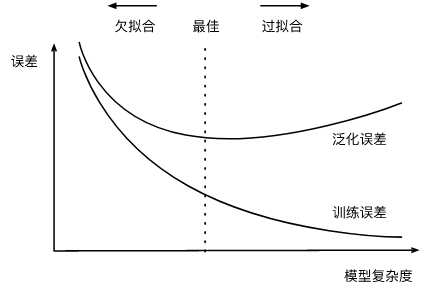
首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望)
模型选择
验证数据集(validation data set),又叫验证集(validation set),指用于模型选择的在train set和test set之外预留的一小部分数据集
若训练数据不够时,预留验证集也是一种luxury。常采用的方法为K折交叉验证。原理为:把train set分割成k个不重合的子数据集(SubDataset),然后做k次模型训练和验证。每次训练中,用一个SubDataset作为validation set,其余k-1个SubDataset作为train set。最后对k次训练误差和验证误差求平均(mean)
欠拟合:模型无法得到较低的训练误差,即训练误差降低不了
过拟合:模型训练误差远小于在测试集上的误差
解决欠拟合和过拟合的方法有二:其一,针对数据选择合适的复杂度模型(模型复杂度过高,易出现过拟合;否则易出现欠拟合)。其二,训练数据集大小(train set过少,则容易过拟合。没有否则)
torch.pow():求tensor的幂次(pow是power(有幂次的意思)的缩写),比如求tensor a的平方,则torch.pow(a,2)
torch.cat((A,B),dim):cat是concatenate(拼接,连接在一起)的缩写,参考博客 https://www.cnblogs.com/JeasonIsCoding/p/10162356.html 解释的很好,感谢博主。我多加一句:连接tensor A和B,就是扩增dim维,比如两个矩阵,dim=1,则扩增列,即横着拼接
torch.utils.data.TensorDataset(x,y):大概意思是整合x和y,使其对应。即x的每一行对应y的每一行。
torch.utils.data.DatasetLoader(dataset=dataset,batch_size=batch_size,shuffle=True,num_workers=2):dataset(通过TensorDataset整合的);batch_size(批量大小);shuffle(是否打乱);num_workers(线程数)
权重衰减(weight decay)
权重衰减又叫L2范数正则化,即在原损失函数基础上添加L2范数惩罚项。
范数公式$ ||x|| _{p}= (\sum_{i=1}^{n}|x_{i}|^{p})^{1/p} $ L2范数为:$ ||x||_{2} = (\sum_{i=1}^{n}|x_{i}|^{2})^{1/2} $
带L2范数惩罚项的新损失函数为:$ \iota (w_{1},w_{2},b) + \frac{\lambda }{2n}||x||^2 $ torch.norm(input, p=)求范数
丢弃法(dropout)
隐藏单元采用一定的概率进行丢弃。使用丢弃法重新计算新的隐藏单元公式为
$ h_{i}^{‘} = \frac{\xi _{i}}{1-p}h_{i} $
其中$ h_{i}$ 为隐藏单元$ h_{i} = \O (x_{1}w_{1i} + x_{2}w_{2i} + x_{3}w_{3i} + x_{4}w_{4i} + b_{i}) $,随机变量$\xi_{i}$取值为0(概率为p)和1(概率为1-p)
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1 #drop_prob的值必须在0-1之间,和数据库中的断言一个意思
#这种情况下把全部元素丢弃
if keep_prob == 0: #keep_prob=0等价于1-p=0,这是$\xi_{i}$值为1的概率为0
return torch.zeros_like(X)
mask = (torch.rand(X.shape) < keep_prob).float() #torch.rand()均匀分布,小于号<判别,若真,返回1,否则返回0
return mask * X / keep_prob # 重新计算新的隐藏单元的公式实现
model.train():启用BatchNormalization和Dropout
model.eval():禁用BatchNormalization和Dropout
正向传播和反向传播
在深度学习模型训练时,正向传播和反向传播之间相互依赖。下面1和2看不懂的可先看《动手学深度学习》3.14.1和3.14.2
1.正向传播的计算可能依赖模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的。
如正则化项$ s = ({\lambda }/{2})(\left \| W^{(1)} \right \|_{F}^{2} + \left \| W^{(2)} \right \|_{F}^{2}) $依赖模型参数$W^{(1)}$和$W^{(2)}$的当前值,而这些当前值是优化算法最近一次根据反向传播算出梯度后迭代得到的。
2.反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的。
如参数梯度$ \frac{\partial J}{\partial W^{(2))}} = (\frac{\partial J}{\partial o}h^{T} + \lambda W^{(2)}) $的计算需要依赖隐藏层变量的当前值h。这个当前值是通过从输入层到输出层的正向传播计算并存储得到的。
小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
标签:lam shuffle 选择 ORC 复杂度 RKE nbsp 整合 etl
原文地址:https://www.cnblogs.com/JadenFK3326/p/12142974.html