标签:heap 解码 不用 视频合成 inf ffmpeg 大小 个人 缓冲
目录
时间转瞬即逝,转眼间19年已经过去了,人愈来愈来老,却不见人心和物质的提升,期望2020年能有一个崭新的自己。
今年因为发展原因,从嵌入式跳槽做互联网后端了,干了一年突然转行,自己也很纠结这么做对不对,但归根结底我只是选择了做自己想做的事情,从事自己想做的工作罢了。
虽然过来后发现也不并算真正意义上的后端工作,用到的后端技术并不多,主要时间挣扎在了流媒体的开发,音视频的编解码,滤波、硬件加速、rtp、音视频格式(aac、pcm、h264)、另外主管选择了开源的ffmpeg库、这些七七八八的东西够你折磨了。。
基于公司项目需求设计流媒体服务器,考虑到扩展性,采用了主流的多进程模型便于后期做分布式,同时解耦业务层与音视频处理层,便于更替音视频处理方案。
基于公共协议栈,管理用户登录、连接音视频服务、用户数据缓存、用户出入音视频服务动态等、迎合docker特点、单独用户数据缓存存储用户数据。
主要包括音视频相关内容的开发,也是开发投入时间最长的服务,主要经历了以下过程。
1)、最初基于ffmpeg的h264软解实现服务demo.
2)、然后尝试基于英特尔vaapi硬件加速驱动做h264硬解,对解码视频帧做软件overlay滤波进行音视频合成,再做vaapi硬编码。
优点是此流程软件实现上会更为简洁快速,也比较稳定。
但是后面发现系统会时不时crash。从系统日志上没有找到相关日志,于是进行了长期的软件模块排除法检查问题原因,做了解码、解码+滤波、滤波+编码等单元模块组挂机测试,仍然无法找到系统crash问题原因。
同时也在微软的github仓库提交了bug/issue,但是回复较慢。
3)、起初怀疑是vaapi驱动问题,于是尝试使用英特尔qsv硬件加速驱动硬解,对解码视频帧做硬件overlay_qsv滤波进行音视频合成,再做qsv硬编码。
优点是音视频处理全交付于gpu处理,省下大片cpu时间。缺点是硬件帧上下文关系密切,做视频自动切换上,需要做更多软件处理,编码上略微复杂。
可惜系统crash问题依然存在。
4)、ffmpeg原生工具命令行测试系统crash问题,发现确实有这个问题,而且更换很多个ffmpeg版本都会出现,只是概率可能会有浮动:快的几分钟到几小时crash、慢的一星期可能不会出现,但是不改任何参数再次尝试依然可能crash.
5)、移植音视频服务从linux到windows系统下、经过长期测试windows下运行intel加速方案确实没有系统宕机问题了、同时因为登录服基于muduo库实现,移植复杂,改将登录服打包进docker容器运行。
6)、完善及优化音视频服务框架及功能。包括:添加适当rtp缓存解决公网环境udp包波动问题、添加音视频同步机制、增加相应业务功能接口。
7)、移植到微服务框架,进一步增强程序扩展性。
1、创建房间:单机能创建的房间数量是有限的,但是要控制画质流畅不丢帧,瓶颈在于视频合成流数量和硬件性能(核心数越多可以适当降低丢帧率,intel驱动性能瓶颈)、
可以堆音视频服务机器解决这个问题,但是体感性价比并不高。
2、直播房间的增、删、改、查。
3、多路流输入下、可指定流合成数量、或者、自动根据流数量合成。
4、 去除音频回音、单条流的音频开关。
5、 配置视频profile level、 获取帧率、丢包率等。
6、其他。
rtp完全是自己解的,没有用ffmpeg的avformat库,这样我更便于管理网络处理部分。

需要注意的是udp在公网上可能存在网络抖动问题,服务端接收到的udp包不一定能按序到达,也可能存在丢包等问题,你需要开一块rtp缓存,按seq做最小堆。我直接用的golang的heap包实现的。
然后实际上也可以按相对时间戳来heap的compare,这样也方便你做音视频同步,记录第一个到达的rtp包时间戳、后续rtp的时间戳按timestamp的增量做时钟的换算,换算成一个浮点时间来排序。
例如 h264 90000的时钟 、 30的帧率 、 : 那么 3000时间戳增量 代表 3000 / 90000 = 33.33333ms
然后就是rtp时间的同步 : av_rtp_handler所有rtp包都带了我一个换算出来的相对时间戳的、 我只需要将音视频的包做一次最小堆插入、每次去取堆顶时间戳最小的rtp包即可、 是音频包就丢进音频解码器、视频包就丢进视频解码器。
我想了很久音视频进行合成结构后发现有一个很重要的东西、那就是音视频帧的缓冲区、而且这个缓冲区真的很重要、它能做到以下效果:
1、控制帧率
2、解决多路流的音视频帧抖动问题
1、 通过一个定时器、你能很方便的控制帧率、例如隔33ms往合成器发送一组音视频帧进行合成即可。修改帧率你只需要更改定时器的种子值。
2、消抖、每路流到达的时间肯定是不稳定的、可能通道3一下子除了了5包数据、一下子来了10帧数据、而其他路还只有1到2帧或者没有、但是你要保持实时性肯定不能把所有帧全部保存下来、所以你必须控制每路的缓冲大小得把挤出来的非I帧删掉、注意是非I帧不然可能会花屏。
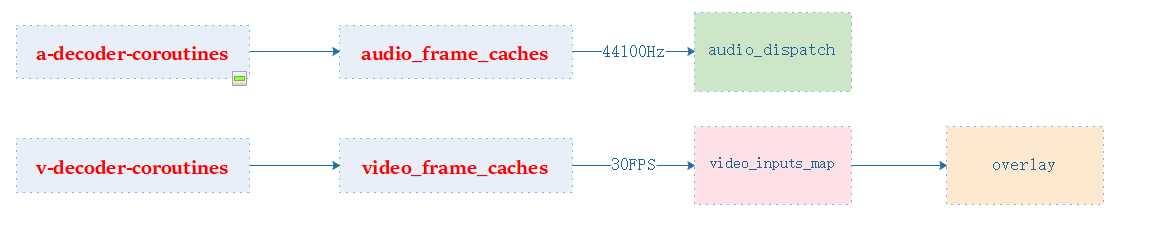
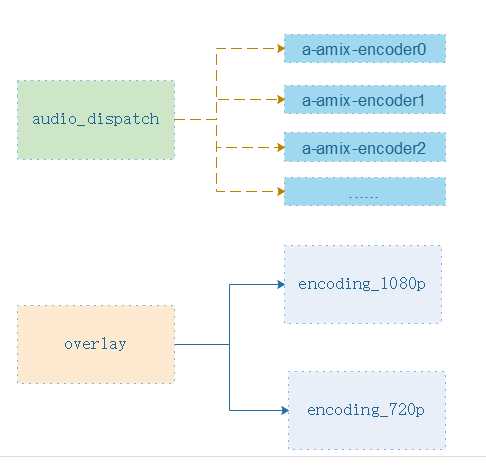
然后就是音视频合成、音频用amix、视频用overlay、
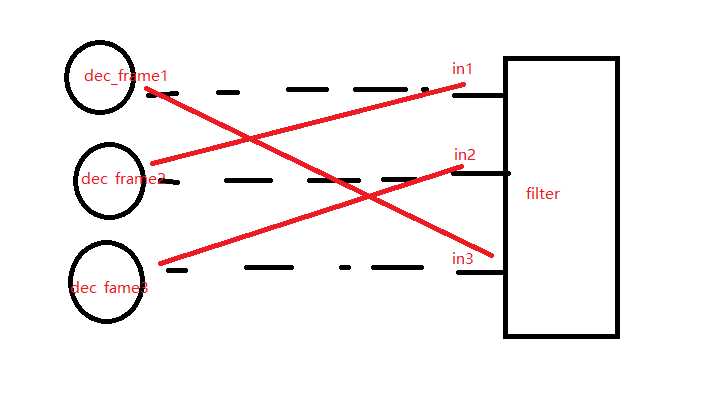
视频帧合成麻烦在qsv有一个硬件帧上下文、qsvframecontext每次做屏幕的自动切换、或者屏幕位置交换、需要重新生成filter、而你就需要费工夫去更新这个qsvframecontext 极为麻烦、后面想到的方法是设计一张ffmpeg filter输入的映射
就是在不该ffmpeg滤波器描述符的情况下、而是直接交换filter的输入位置。
一个草图将就下: 相当于 就是打乱正当的输入顺序、做一张映射、这样子不用更改filter的描述符即可做滤波器的切换,要便利极多!
音频合成没什么好说的、就是每路的输出可能不能包含自己的通道声音、不然可能存在回音、你只需要弄个set记录需要合成的流输入id的集合、合成的时候把自己的id去掉再合成就行了。
编码好像没什么重点东西、打包的时候打上个合适的时间戳即可。
今年其实挺累的、第一次一个人从零写了一整套流媒体服务、以及整个系统框架的搭建、最后也学习了主流后端框架、移植到了微服务框架上。虽然做了很多事但是收获也多多。希望未来能有更好的发展。
标签:heap 解码 不用 视频合成 inf ffmpeg 大小 个人 缓冲
原文地址:https://www.cnblogs.com/ailumiyana/p/12159065.html