标签:二维 hide str val 默认 ram 技术 open data
Pandas是基于Numpy构建的库,在数据处理方面可以把它理解为numpy加强版,同时Pandas也是一项开源项目 。不同于numpy的是,pandas拥有种数据结构:Series和DataFrame:

Series是一种类似一维数组的数据结构,由一组数据和与之相关的index组成,这个结构一看似乎与dict字典差不多,我们知道字典是一种无序的数据结构,而pandas中的Series的数据结构不一样,它相当于定长有序的字典,并且它的index和value之间是独立的,两者的索引还是有区别的,Series的index是可变的,而dict字典的key值是不可变的。
Series的生成方式:

1 #没有指定index,生成默认的index 2 data = Series([9527,‘btch‘,2345,‘efos‘]) 3 #指定index 4 data = Series([9,5,2,7],index = [‘aa‘,‘bb‘,‘cc‘,‘dd‘])
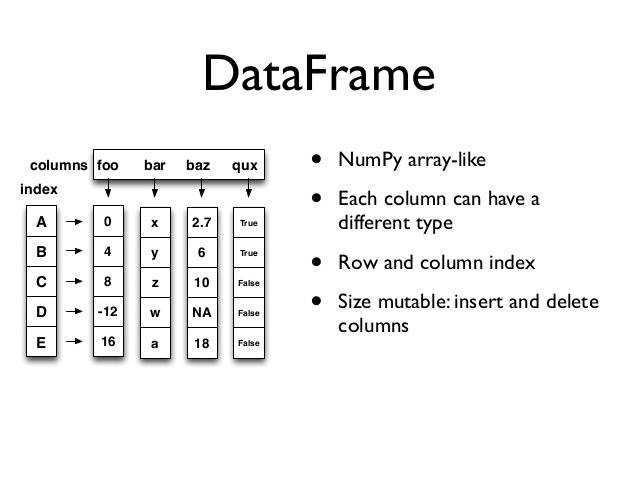
DataFrame这种数据结构我们可以把它看作是一张二维表,DataFrame长得跟我们平时使用的Excel表格差不多,DataFrame的横行称为columns,竖列和Series一样称为index,DataFrame每一列可以是不同类型的值集合,所以DataFrame你也可以把它视为不同数据类型同一index的Series集合。
DataFrame的生成与Series差不多,你可以自己指定index,也可不指定,DataFrame会自动帮你补上。
#Series的两种生成方式
标签:二维 hide str val 默认 ram 技术 open data
原文地址:https://www.cnblogs.com/shareinfo/p/12161748.html
