标签:value 统计 nose 字符 int test float numpy 需求
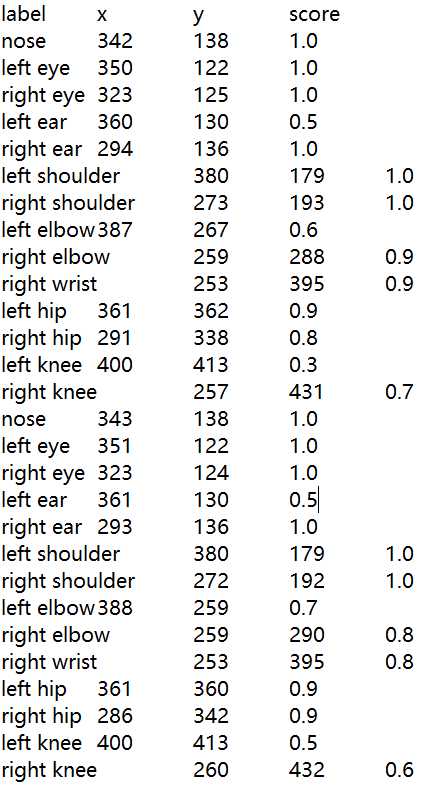
根据label求分别求x,y,score列的平均值,并保存
import pandas as pd
import json
import numpy as np
#将pose数据x y label保存到list中
pose = []
def save_to_json(file,output_path):
jsObj = json.dumps(file)
fileObject = open(output_path + ‘pose.json‘, ‘w‘)
fileObject.write(jsObj)
fileObject.close()
def data_average(value_pose_x):
sum = 0
b = len(value_pose_x)
for i in value_pose_x:
sum = sum + i
average = str(sum / b)
# print(average)
return average
def pose(filename_pose):
data_pose = pd.read_table(filename_pose,sep=‘\t‘) #low_memory=False
label_pose = data_pose.values[:,0] #[‘nose‘ ‘left eye‘ ‘right eye‘ ... ‘right hip‘ ‘left knee‘ ‘right knee‘]
# print(label_pose)
value_cnt = {} # 将结果用一个字典存储
for value in label_pose: # 统计结果
value_cnt[value] = value_cnt.get(value, 0) + 1 # get(value, num)函数的作用是获取字典中value对应的键值, num=0指示初始值大小。
tmp_save = {}
# print(value_cnt.keys()) #17个
for key in value_cnt.keys():
if key != "label":
pose_label = data_pose.loc[data_pose[‘label‘]==key,:] #DataFrame
value_pose_x = pose_label.loc[:, ‘x‘]
value_pose_y = pose_label.loc[:, ‘y‘]
value_pose_score = pose_label.loc[:, ‘score‘]
value_pose_x =list(map(int,value_pose_x)) #字符串数组转成int数组
value_pose_y =list(map(int,value_pose_y)) #字符串数组转成int数组
value_pose_score =list(map(float,value_pose_score)) #字符串数组转成float数组
value_x = data_average(value_pose_x) #获取平均值
value_y = data_average(value_pose_y) #获取平均值
value_score = data_average(value_pose_score) #获取平均值
tmp_save.setdefault(key,[]).append(value_x) #保存到字典中
tmp_save.setdefault(key,[]).append(value_y) #保存到字典中
tmp_save.setdefault(key,[]).append(value_score) #保存到字典中
save_to_json(tmp_save,output_path) #保存到本地
if __name__ == ‘__main__‘:
data_path = r"E:\1Test\pose.txt" #数据存储路径
output_path = r‘E:\1Test\\‘ #数据输出保存路径
pose(data_path)

共有17个label,并把各个label的x,y,score均值按label存放在字典中。
标签:value 统计 nose 字符 int test float numpy 需求
原文地址:https://www.cnblogs.com/jackie-lzou/p/12163294.html