标签:分片 oss term 一个 schema 姓名 分区函数 运行 相同
目录
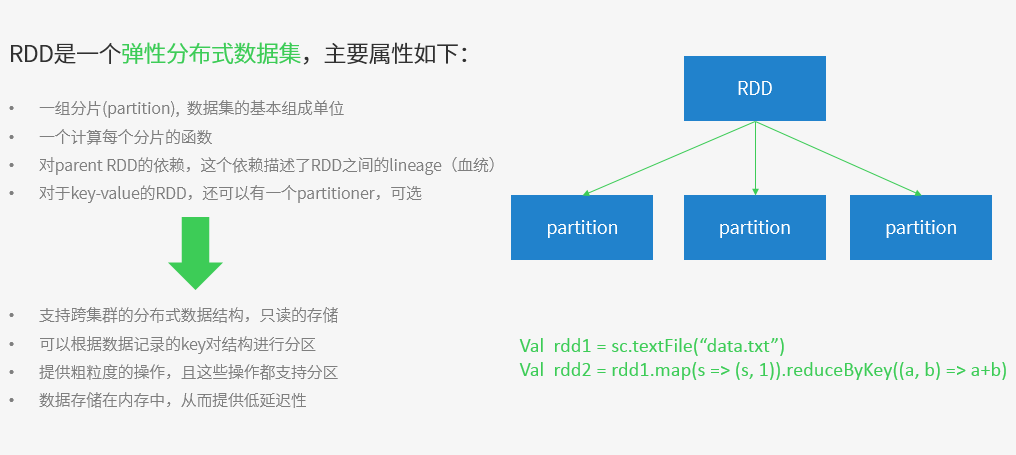
一、RDD概述
二、RDD实现
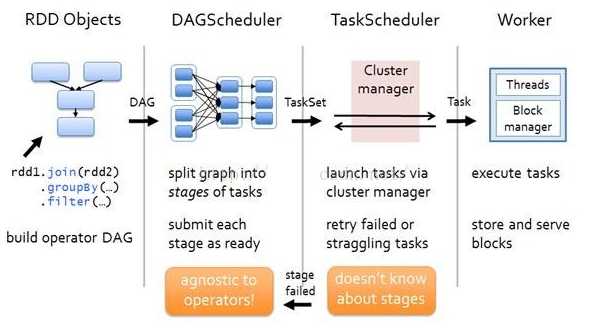
1、作业调度
A、当对RDD执行转换操作时,调度器会根据RDD的“血统”来构建由若干高度阶段(Stage)组成的有向无环图(DAG), 每个阶段包含尽可能多的连续“窄依赖”转换
B、另外,调度分配任务采用“延时调度”机制,并根据”数据本地性“来确定
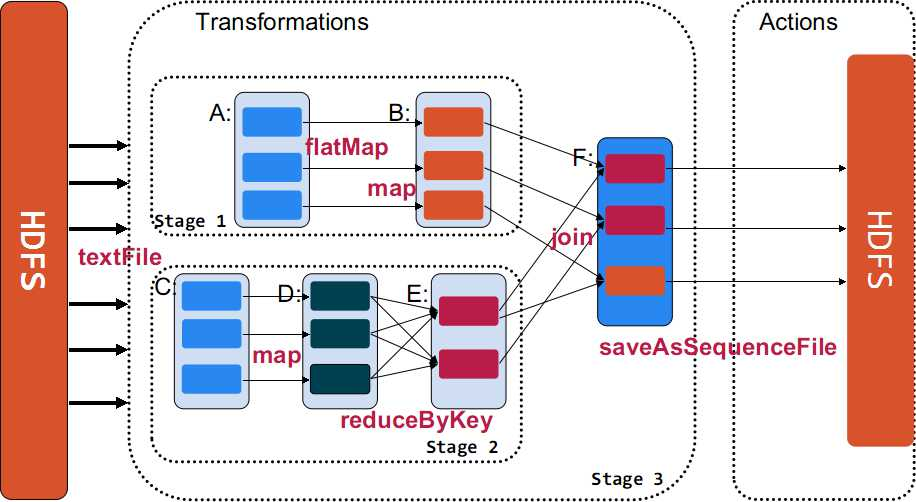
宽依赖与窄依赖:


2、解析器集成:三个步骤 A、用户每一行输入编译成一个类 B、类加载至JVM中 C、调用 类函数
3、内存管理:
4、检查点(Checkpoint)支持
5、多用户管理:提供公平调度算法、延迟调度、作业取消机制、细粒度资源共享、数据本地性
三、RDD运行流程
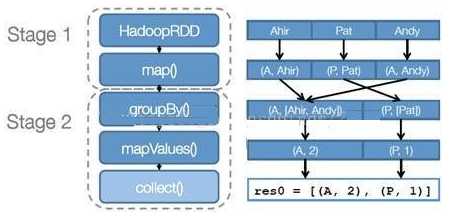
RDD在Spark中运行大概分为以下三步:
示例图如下:
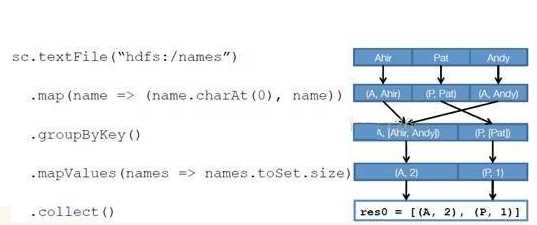
三、RDD分区
1、RDD分区计算
2、RDD分区函数,以及默认提供两种划分器:哈希分区划分器和范围分区划分器
四、RDD操作函数
Spark转换操作函数讲解: https://www.cnblogs.com/jinggangshan/p/8086492.html
https://blog.csdn.net/taokeblog/article/details/103796987
行动操作函数讲解:
五、RDD编程接口说明
Spark提供了通用接口来抽象每个RDD,包括
1、分区信息:数据集的最小分片
2、依赖关系
3、函数
4、划分策略和数据位置的元数据
标签:分片 oss term 一个 schema 姓名 分区函数 运行 相同
原文地址:https://www.cnblogs.com/zhanghy/p/12166150.html