标签:ide info image cte 例子 etl 整合 cli led
上一讲深入的讲解了Ribbon的初始化过程及Ribbon与Eureka的整合代码,与Eureka整合的类就是DiscoveryEnableNIWSServerList,同时在DynamicServerListLoadBalancer中会调用PollingServerListUpdater 进行定时更新Eureka注册表信息到BaseLoadBalancer中,默认30s调度一次。
我们知道Ribbon主要是由3个组件组成的:
其中ILoadBalancer前面我们已经分析过了,接下来我们一起看看IRule和IPing中的具体实现。
目录如下:
原创不易,如若转载 请标明来源!
博客地址:一枝花算不算浪漫
微信公众号:壹枝花算不算浪漫
还记得我们上一讲说过,在Ribbon初始化过程中,默认的IRule为ZoneAvoidanceRule,这里我们可以通过debug看看,从RibbonLoadBalancerClient.getServer() 一路往下跟,这里直接看debug结果:
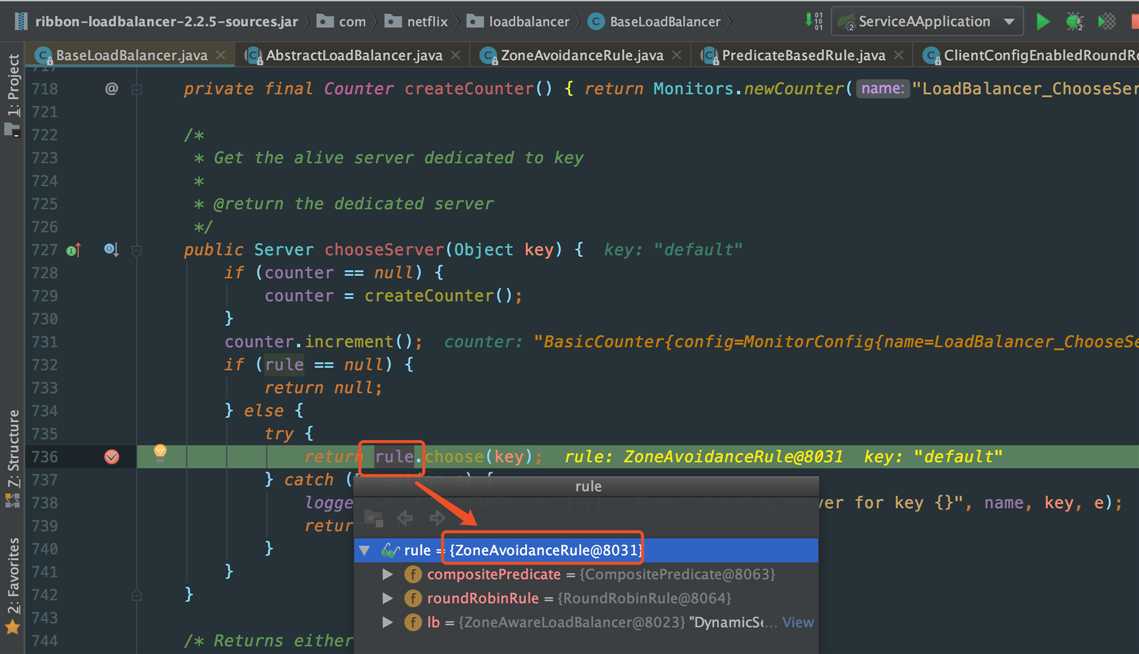
然后我们继续跟ZoneAvoidanceRule.choose() 方法:
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule {
/**
* Method that provides an instance of {@link AbstractServerPredicate} to be used by this class.
*
*/
public abstract AbstractServerPredicate getPredicate();
/**
* Get a server by calling {@link AbstractServerPredicate#chooseRandomlyAfterFiltering(java.util.List, Object)}.
* The performance for this method is O(n) where n is number of servers to be filtered.
*/
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
}这里是调用的ZoneAvoidanceRule的父类中的choose()方法,首先是拿到对应的ILoadBalancer,然后拿到对应的serverList数据,接着调用chooseRoundRobinAfterFiltering()方法,继续往后跟:
public abstract class AbstractServerPredicate implements Predicate<PredicateKey> {
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextIndex.get();
int next = (current + 1) % modulo;
if (nextIndex.compareAndSet(current, next) && current < modulo)
return current;
}
}
}到了这里可以看到incrementAndGetModulo()方法就是处理serverList轮询的算法,这个和RoudRobinRule中采用的是一样的算法,这个算法大家可以品一品,我这里也会画个图来说明下:
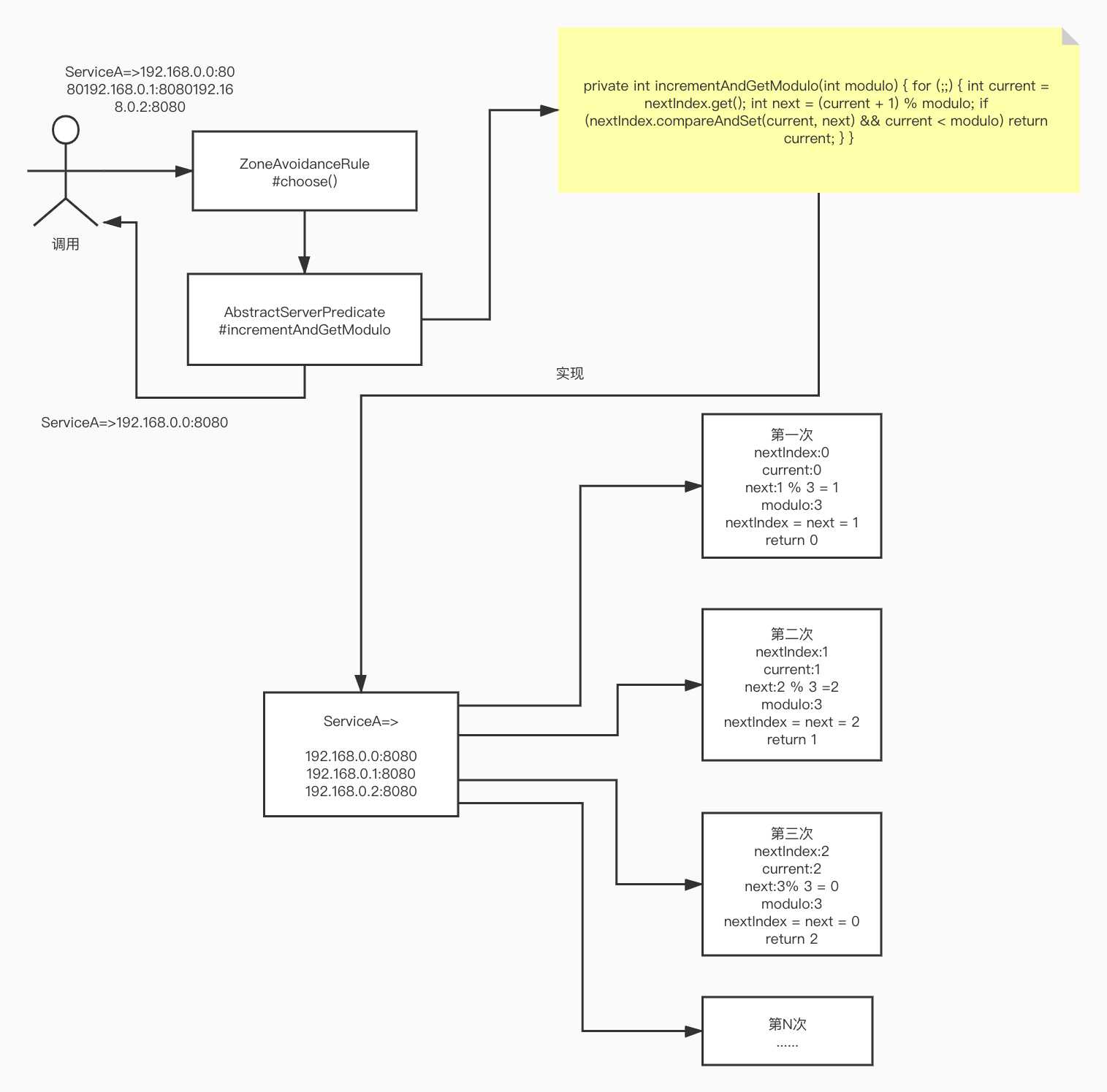
看了图=中的例子估计大家都会明白了,这个算法就是依次轮询。这个算法写的很精简。
我们上面知道,我们按照轮询的方式从serverList取到一个server后,那么怎么把之前原有的类似于:http://ServerA/sayHello/wangmeng中的ServerA给替换成请求的ip数据呢?
接着我们继续看RibbonLoadBalancerClient.execute()方法,这个里面request.apply()会做一个serverName的替换逻辑。
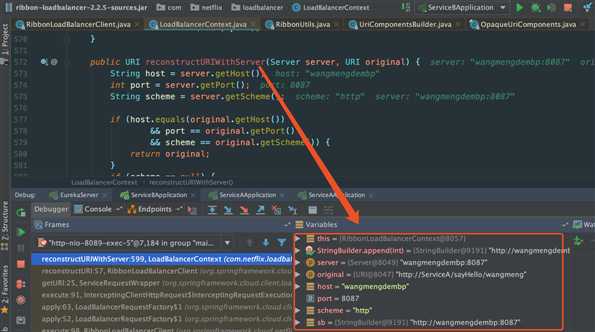
最后可以一步步跟到RibbonLoadBalancerClient.reconstructURI(),这个方法是把请求自带的getURI方法给替换了,我们最后查看context.reconstructURIWithServer() 方法,debug结果如图,这个里面会一步步把对应的请求url给拼接起来:
我们知道 Ribbon还有一个重要的组件就是ping机制,通过上一讲Ribbon的初始化我们知道,默认的IPing实现类为:NIWSDiscoveryPing,我们可以查看其中的isAlive()方法:
public class NIWSDiscoveryPing extends AbstractLoadBalancerPing {
BaseLoadBalancer lb = null;
public NIWSDiscoveryPing() {
}
public BaseLoadBalancer getLb() {
return lb;
}
/**
* Non IPing interface method - only set this if you care about the "newServers Feature"
* @param lb
*/
public void setLb(BaseLoadBalancer lb) {
this.lb = lb;
}
public boolean isAlive(Server server) {
boolean isAlive = true;
if (server!=null && server instanceof DiscoveryEnabledServer){
DiscoveryEnabledServer dServer = (DiscoveryEnabledServer)server;
InstanceInfo instanceInfo = dServer.getInstanceInfo();
if (instanceInfo!=null){
InstanceStatus status = instanceInfo.getStatus();
if (status!=null){
isAlive = status.equals(InstanceStatus.UP);
}
}
}
return isAlive;
}
@Override
public void initWithNiwsConfig(
IClientConfig clientConfig) {
}
}这里就是获取到DiscoveryEnabledServer对应的注册信息是否为UP状态。那么 既然有个ping的方法,肯定会有方法进行调度的。
我们可以查看isAlive()调用即可以找到调度的地方。
在BaseLoadBalancer构造函数中会调用setupPingTask()方法,进行调度:
protected int pingIntervalSeconds = 10;
void setupPingTask() {
if (canSkipPing()) {
return;
}
if (lbTimer != null) {
lbTimer.cancel();
}
lbTimer = new ShutdownEnabledTimer("NFLoadBalancer-PingTimer-" + name,
true);
lbTimer.schedule(new PingTask(), 0, pingIntervalSeconds * 1000);
forceQuickPing();
}这里pingIntervalSeconds在BaseLoadBalancer中定义的是10s,但是在initWithConfig()方法中,通过传入的时间覆盖了原本的10s,这里实际的默认时间是30s。如下代码:
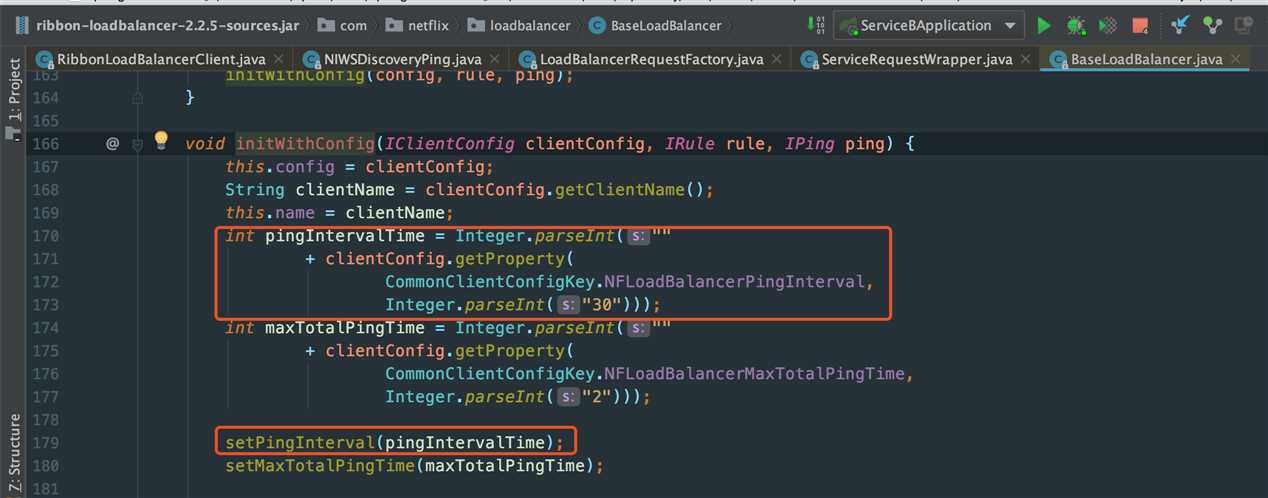
我们也可以通过debug来看看:
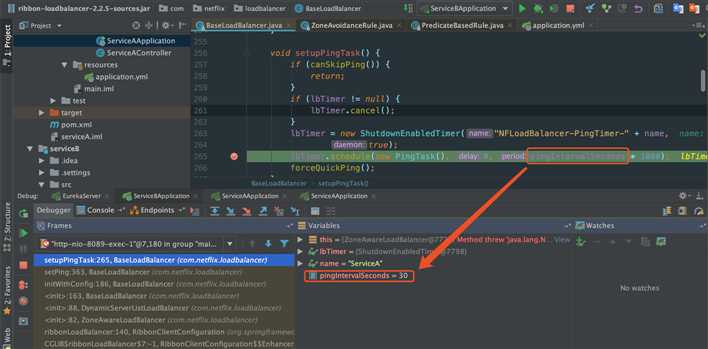
可能大家好奇为什么要单独截图来说这个事,其实是因为网上好多博客讲解都是错的,都写的是ping默认调度时间为10s,想必他们都是没有真正debug过吧。
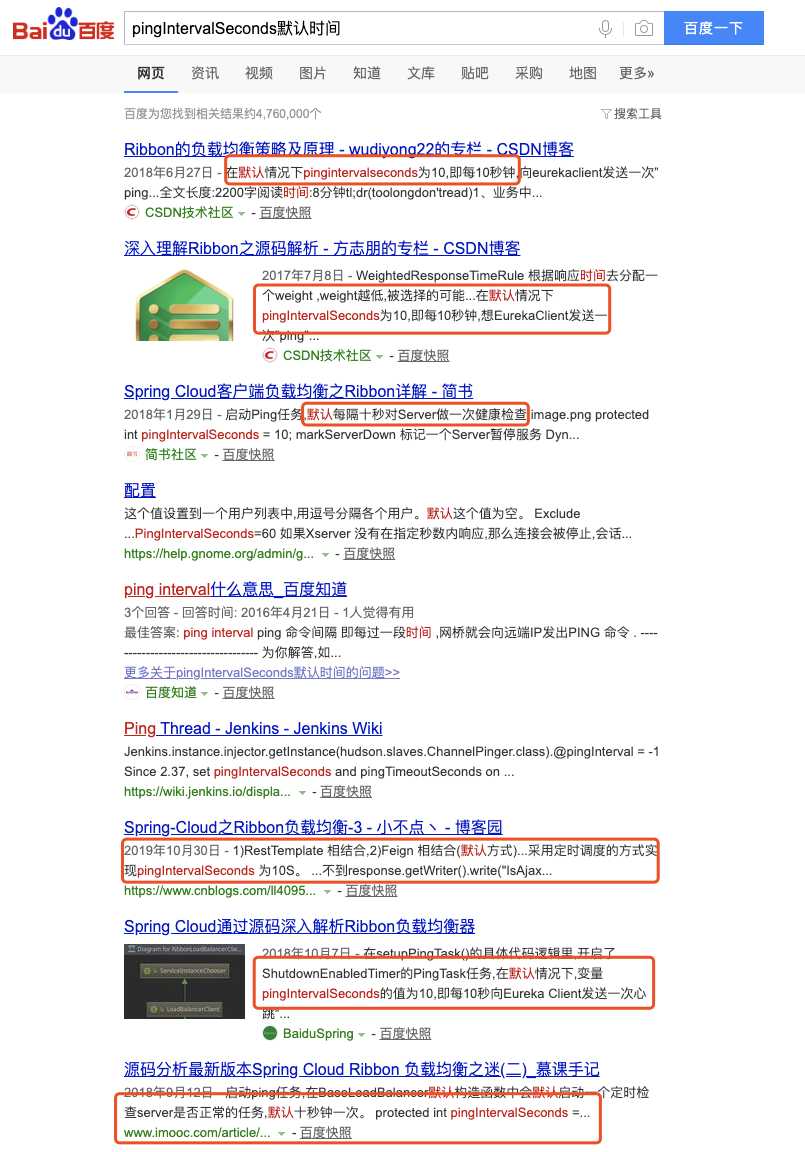
还是那句话,源码出真知。
RoundRobinRule:系统内置的默认负载均衡规范,直接round robin轮询,从一堆server list中,不断的轮询选择出来一个server,每个server平摊到的这个请求,基本上是平均的
这个算法,说白了是轮询,就是一台接着一台去请求,是按照顺序来的
AvailabilityFilteringRule:这个rule就是会考察服务器的可用性
如果3次连接失败,就会等待30秒后再次访问;如果不断失败,那么等待时间会不断变长
如果某个服务器的并发请求太高了,那么会绕过去,不再访问
这里先用round robin算法,轮询依次选择一台server,如果判断这个server是存活的可用的,如果这台server是不可以访问的,那么就用round robin算法再次选择下一台server,依次循环往复,10次。
WeightedResponseTimeRule:带着权重的,每个服务器可以有权重,权重越高优先访问,如果某个服务器响应时间比较长,那么权重就会降低,减少访问
ZoneAvoidanceRule:根据机房和服务器来进行负载均衡,说白了,就是机房的意思,看了源码就是知道了,这个就是所谓的spring cloud ribbon环境中的默认的Rule
BestAvailableRule:忽略那些请求失败的服务器,然后尽量找并发比较低的服务器来请求
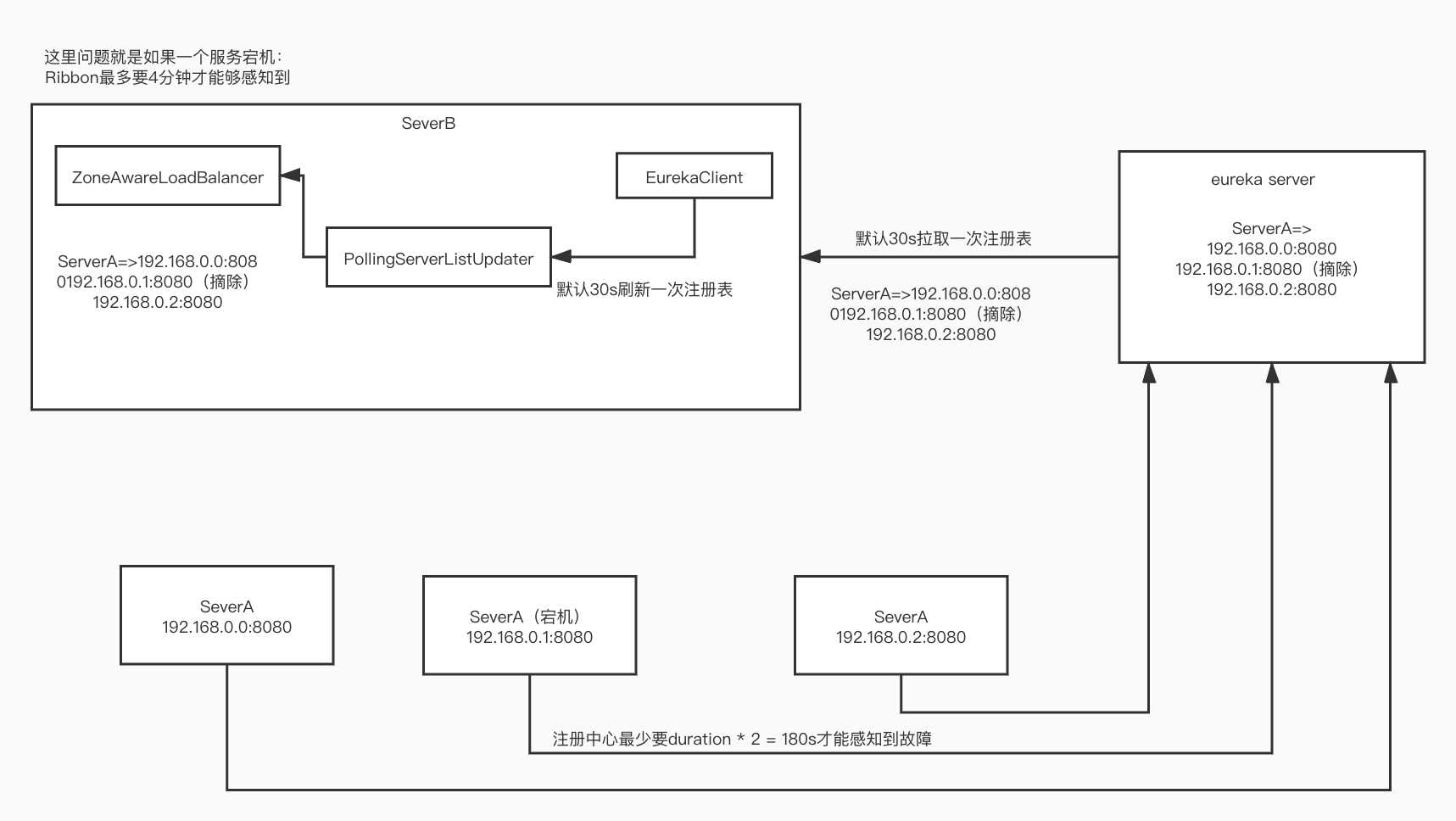
到了这里 Ribbon相关的就结束了,对于Ribbon注册表拉取及更新逻辑这里也梳理下,这里如果Ribbon保存的注册表信息有宕机的情况,这里最多4分钟才能感知到,所以spring cloud还有一个服务熔断的机制,这个后面也会讲到。
本文章首发自本人博客:https://www.cnblogs.com/wang-meng 和公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫

【一起学源码-微服务】Ribbon 源码四:进一步探究Ribbon的IRule和IPing
标签:ide info image cte 例子 etl 整合 cli led
原文地址:https://www.cnblogs.com/wang-meng/p/12166148.html