标签:func 拷贝 jetty var some 密码 wget admin prompt
一、 VM虚拟环境搭建(详细讲解)说明:在windos10上使用VmWare Workstation创建3节点Hadoop虚拟环境
创建虚拟机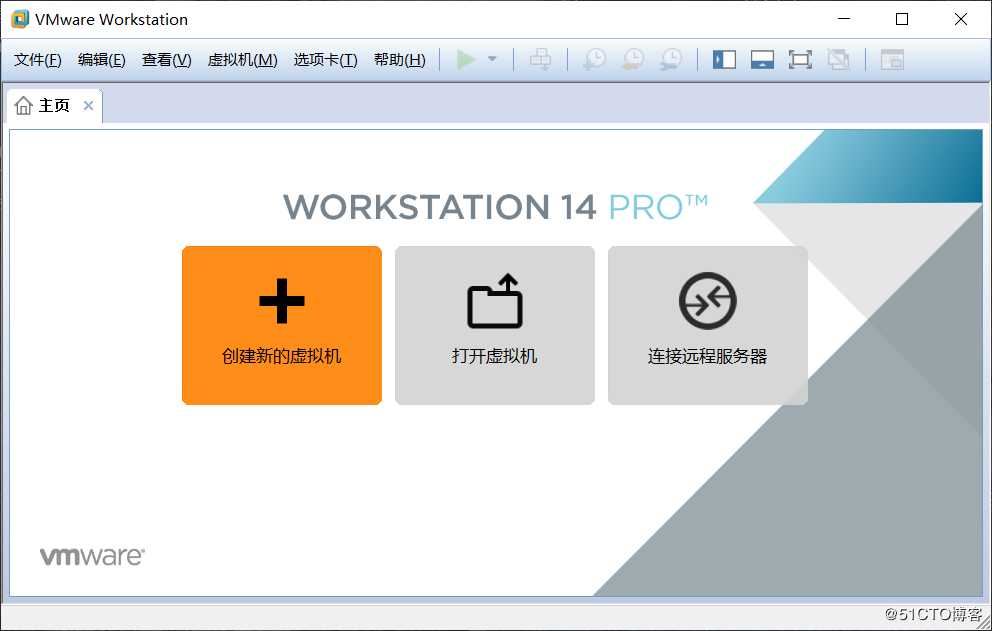
下一步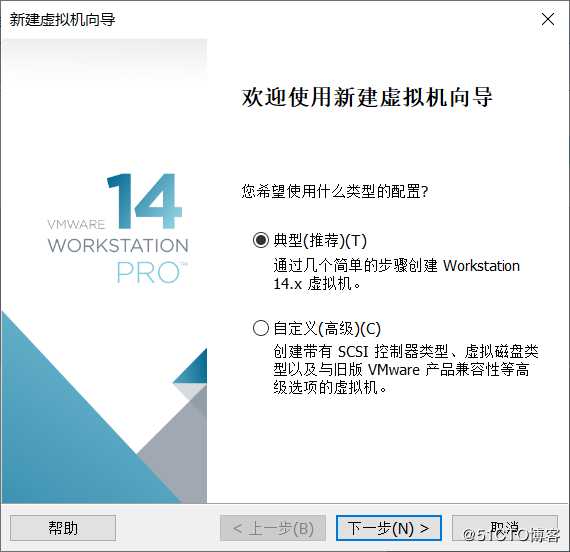
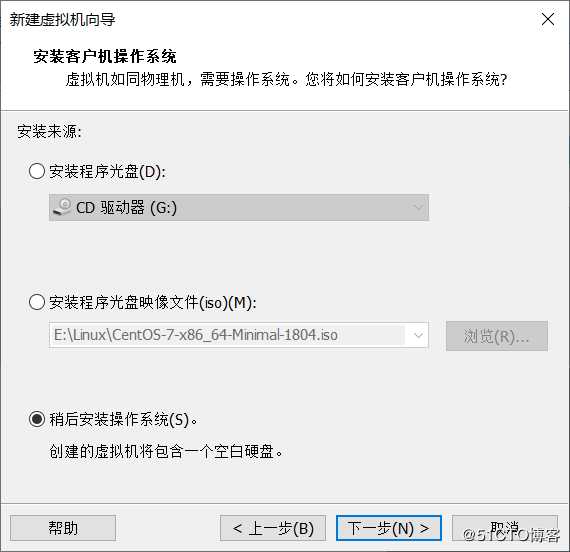
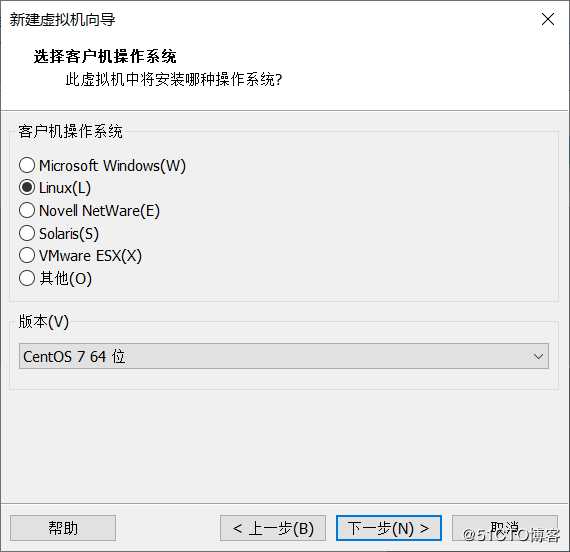
设置虚拟机主机名和介质存放路径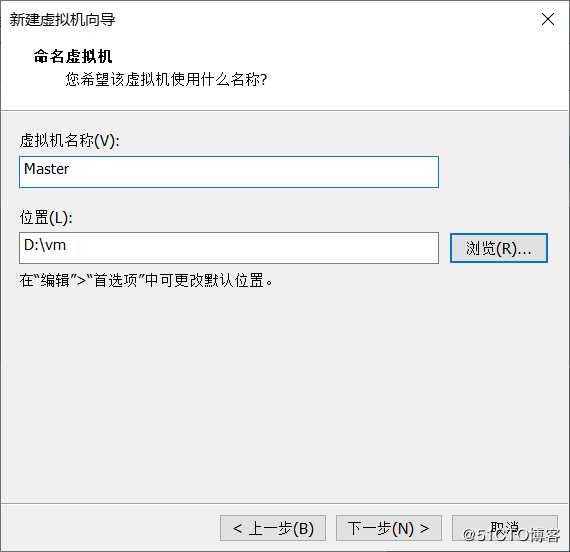
设置20G磁盘大小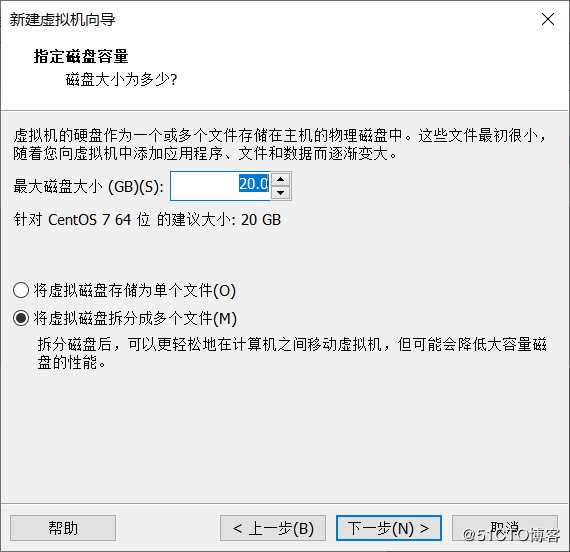
选择“自定义硬件”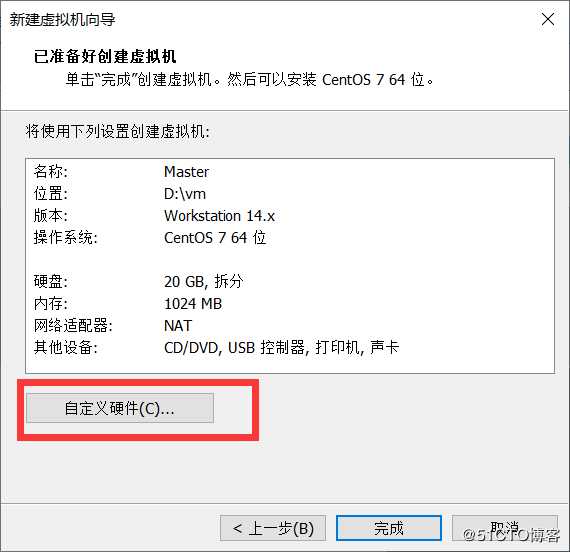
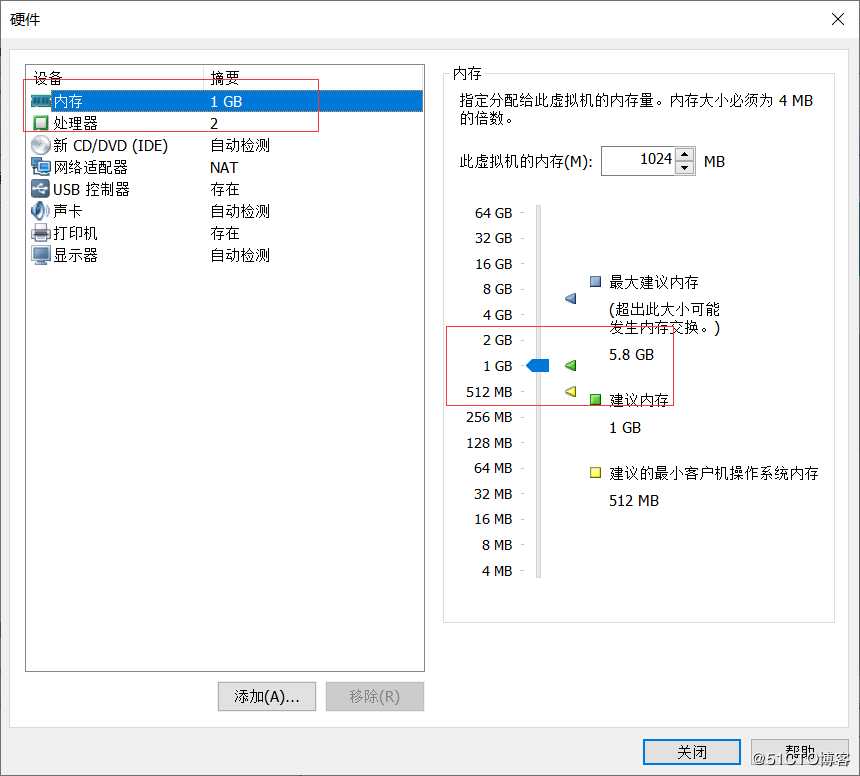
配置网络模式为NAT模式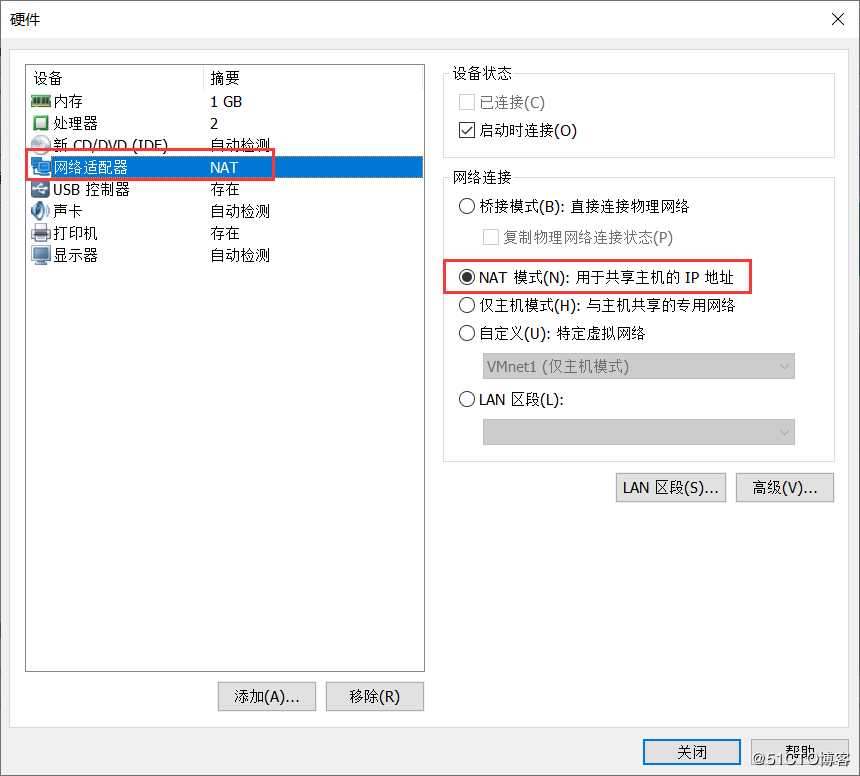
配置虚拟机启动镜像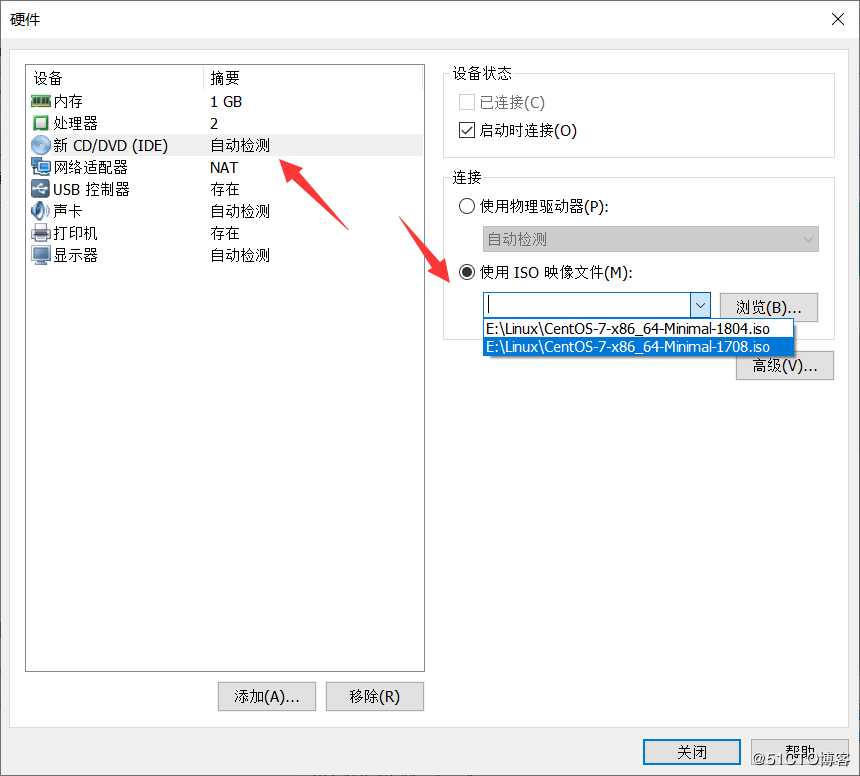
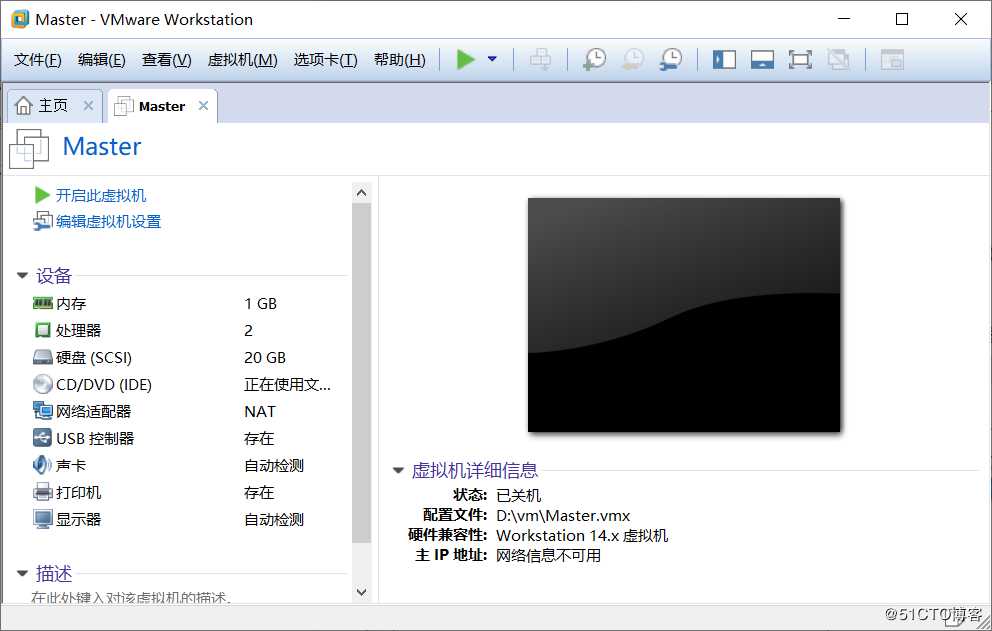
到这里,使用虚拟机克隆技术配置另外两台slave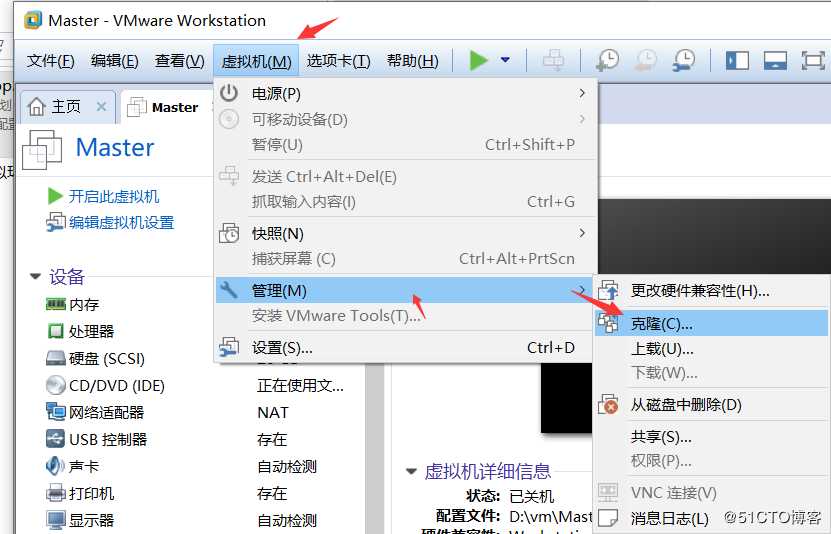
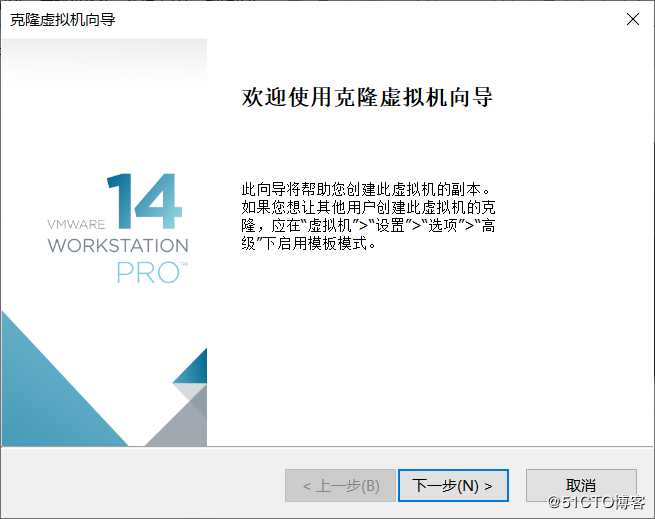
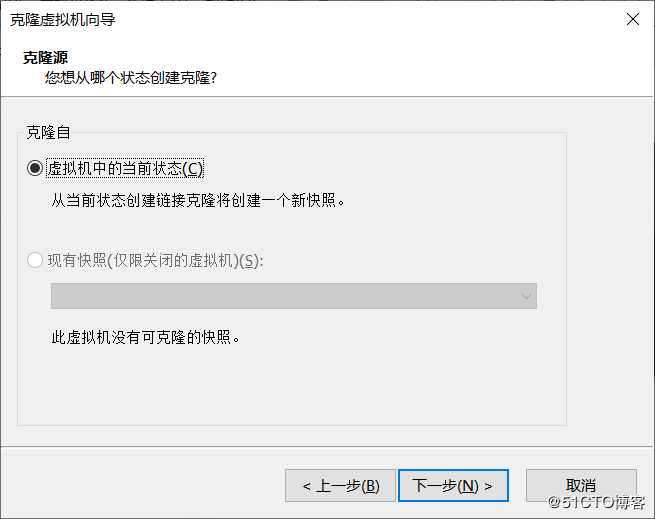
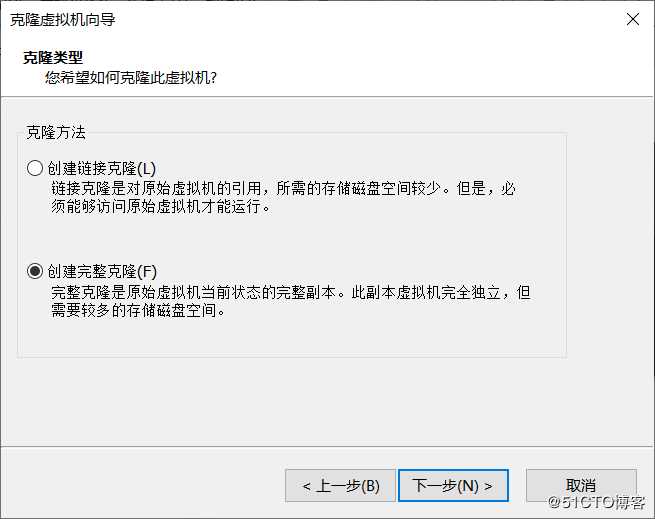
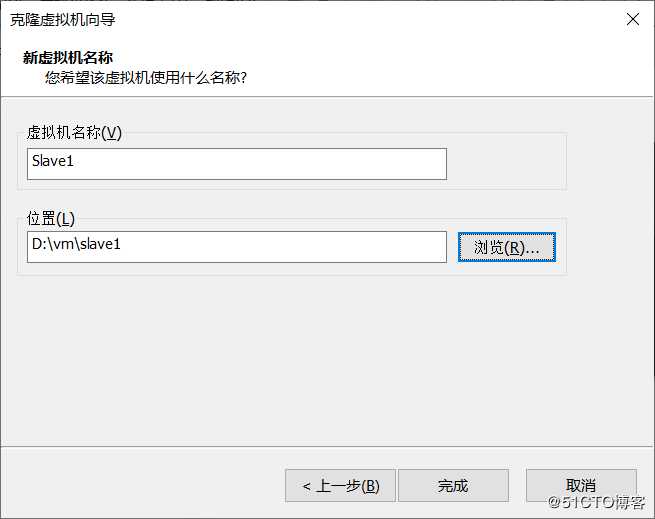
同理克隆slave2, 步骤省略
此时windos网络连接里面会出现两张虚拟网卡
接下来就是给虚拟机配置IP网络
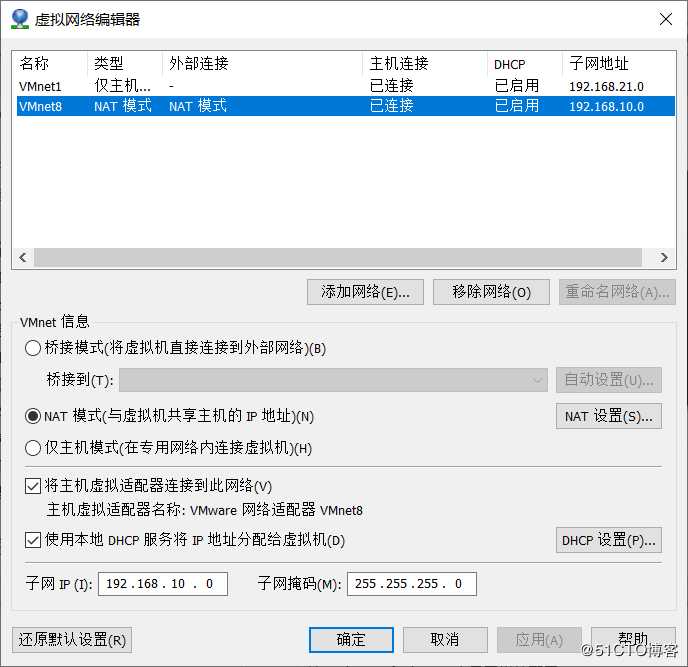
虚拟机网卡IP要和NAT模式的IP是在同一个段,虚拟机才能通过windos笔记的VMnet8网卡与互联网通信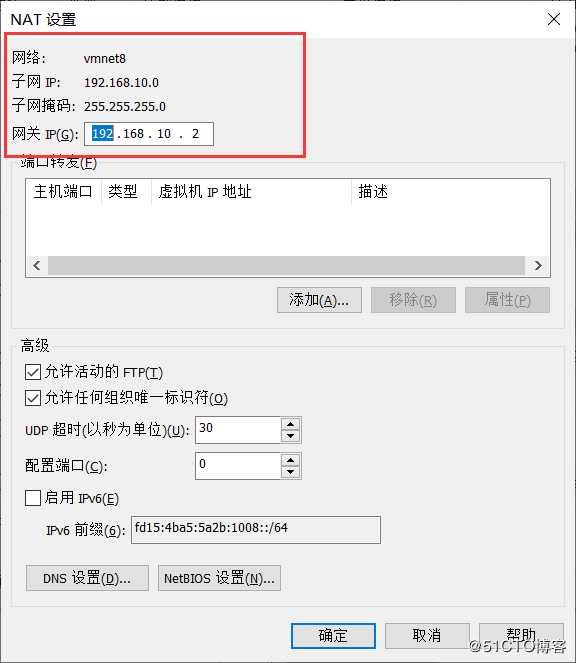
接下来启动虚拟机配置操作系统IP网络(具体配置过程省略)
1、环境规划
Hadoop2.6.5+centos7.5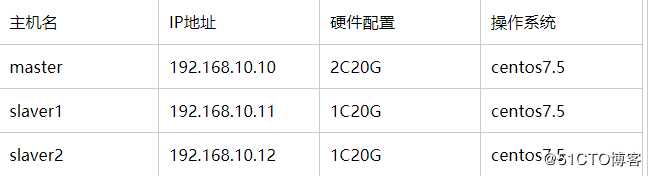
2、配置集群中主机域名访问解析
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.11.10 master
192.168.11.11 slave1
192.168.11.12 slave2注:slaver1和slaver2也是同样的配置
3.配置节点jdk环境
[root@master src]# pwd
/usr/local/src
[root@master src]# wget http://download.oracle.com/otn-pub/java/jdk/8u172-b11/a58eab1ec242421181065cdc37240b08/jdk-8u172-linux-x64.tar.gz
[root@master src]#tar -zxvf jdk-8u172-linux-x64.tar.gz
[root@master src]# ls
192.168.10.11 192.168.10.12 hadoop-2.6.5 hadoop-2.6.5.tar.gz jdk1.8.0_172 jdk-8u172-linux-x64.tar.gz
[root@master src]# cd ./jdk1.8.0_172/
[root@master jdk1.8.0_172]# pwd
/usr/local/src/jdk1.8.0_172在/etc/profile文件末尾添加
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH使用/etc/profile文件立即生效
[root@master jdk1.8.0_172]# source /etc/profile验证jdk环境是否安装成功
[root@master jdk1.8.0_172]# java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
备注:slaver1、slaver2节点同样的配置
[root@slave1 src]# java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
[root@slave2 ~]# java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)4.关闭系统防火墙和内核防火墙(master、slaver1、slaver2均需要以下操作)
1>清空系统防火墙
iptables -F
iptables -X
iptables -Z2>临时关闭内核防火墙
setenforce 0
getenforce ##查看防火墙状态3>永久性关闭内核防火墙
vim /etc/sysconfig/selinux 把SELINUX状态改为disabled
SELINUX=disabled5.配置集群节点ssh户型
说明:执行以下操作,完成集群中的节点两两免密登陆
[root@master jdk1.8.0_172]# ssh-keygen -t rsa ##如果环境没有配置过秘钥,一路回车就行
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y ##说明:因为之前配置过秘钥,所以才提示这一步
Enter passphrase (empty for no passphrase):
Enter same passphrase again: ##回车
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:TogQfLv56boAaUDkQbtff0TEyYLS/qERnYU5wuVRRAw root@master
The key‘s randomart image is:
+---[RSA 2048]----+
|o*. o +E&*. |
|o +o.*.Bo= |
|.o..o.o.o. |
|.....+ o. |
|oo .+= S. |
|... +..+. |
| .. . o.. |
| . o . |
| o+. |
+----[SHA256]-----+
[root@master jdk1.8.0_172]# ssh-copy-id master
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host ‘master (192.168.10.10)‘ can‘t be established.
ECDSA key fingerprint is SHA256:Ibqy6UOiZGGsuF285qc/Q7nwyW88CpdVk2HcfbDTmzg.
ECDSA key fingerprint is MD5:a6:cd:4a:ad:a1:1c:83:b6:20:c5:5b:13:32:78:34:98.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@master‘s password: ##输入root的密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ‘master‘"
and check to make sure that only the key(s) you wanted were added.
[root@master jdk1.8.0_172]# ssh-copy-id slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1‘s password: ##输入root的登陆密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ‘slave1‘"
and check to make sure that only the key(s) you wanted were added.
[root@master jdk1.8.0_172]# ssh-copy-id slave2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave2‘s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ‘slave2‘"
and check to make sure that only the key(s) you wanted were added.
说明:slave1和slave2节点也需要执行上面同样的操作
安装Hadoop集群(master、slave1、slave2节点配置)
6.下载hadoop二进制安装包并安装(master、slave1、slave2节点执行)
[root@master ~]# cd /usr/local/src/
[root@master src]# wget http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
[root@master src]# tar -zxvf hadoop-2.6.5.tar.gz
[root@master src]# pwd
/usr/local/src
[root@master src]# ls
hadoop-2.6.5 jdk1.8.0_172
hadoop-2.6.5.tar.gz jdk-8u172-linux-x64.tar.gz7.设置master节点的JAVA_HOME环境变量
[root@master src]# ls
hadoop-2.6.5 hadoop-2.6.5.tar.gz jdk1.8.0_172 jdk-8u172-linux-x64.tar.gz
[root@master src]# cd hadoop-2.6.5/etc/hadoop/
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties ssl-client.xml.example
configuration.xsl hdfs-site.xml kms-site.xml ssl-server.xml.example
container-executor.cfg httpfs-env.sh log4j.properties yarn-env.cmd
core-site.xml httpfs-log4j.properties mapred-env.cmd yarn-env.sh
hadoop-env.cmd httpfs-signature.secret mapred-env.sh yarn-site.xml
hadoop-env.sh httpfs-site.xml mapred-queues.xml.template
hadoop-metrics2.properties kms-acls.xml mapred-site.xml.template
hadoop-metrics.properties kms-env.sh slaves
[root@master hadoop]# echo $JAVA_HOME
/usr/local/src/jdk1.8.0_172
[root@master hadoop]# vi hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
[root@master hadoop]# vi yarn-env.sh
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
# resolve links - $0 may be a softlink
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
# some Java parameters
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java
-- INSERT --
同理配置slave1和slave2节点的JAVA_HOME环境变量
配置hadoop集群master节点slaves文件主机名
[root@master hadoop]# pwd
/usr/local/src/hadoop-2.6.5/etc/hadoop
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties slaves
configuration.xsl hdfs-site.xml kms-site.xml ssl-client.xml.example
container-executor.cfg httpfs-env.sh log4j.properties ssl-server.xml.example
core-site.xml httpfs-log4j.properties mapred-env.cmd yarn-env.cmd
hadoop-env.cmd httpfs-signature.secret mapred-env.sh yarn-env.sh
hadoop-env.sh httpfs-site.xml mapred-queues.xml.template yarn-site.xml
hadoop-metrics2.properties kms-acls.xml mapred-site.xml
hadoop-metrics.properties kms-env.sh mapred-site.xml.template
[root@master hadoop]# vim slaves
slave1
slave2
##master节点
[root@master hadoop]# pwd
/usr/local/src/hadoop-2.6.5/etc/hadoop
[root@master hadoop]# vi core-site.xml
11 distributed under the License is distributed on an "AS IS" BASIS ,
12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 See the License for the specific language governing permissions and
14 limitations under the License. See accompanying LICENSE file.
15 -->
16
17 <!-- Put site-specific property overrides in this file. -->
18
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://master:9000</value>
23 </property>
24 <property>
25 <name>hadoop.tmp.dir</name>
26 <value>file:/usr/local/src/hadoop-2.8.2/tmp/</value>
27 </property>
28 </configuration>
[root@master hadoop]# vi hdfs-site.xml
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
14 limitations under the License. See accompanying LICENSE file.
15 -->
16
17 <!-- Put site-specific property overrides in this file. -->
18
19 <configuration>
20 <property>
21 <name>dfs.namenode.secondary.http-address</name>
22 <value>master:9001</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name>
26 <value>file:/usr/local/src/hadoop-2.8.2/dfs/name</value>
27 </property>
28 <property>
29 <name>dfs.datanode.data.dir</name>
30 <value>file:/usr/local/src/hadoop-2.8.2/dfs/data</value>
31 </property>
32 <property>
33 <name>dfs.replication</name>
34 <value>2</value>
35 </property>
36 </configuration>
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties ssl-client.xml.example
configuration.xsl hdfs-site.xml kms-site.xml ssl-server.xml.example
container-executor.cfg httpfs-env.sh log4j.properties yarn-env.cmd
core-site.xml httpfs-log4j.properties mapred-env.cmd yarn-env.sh
hadoop-env.cmd httpfs-signature.secret mapred-env.sh yarn-site.xml
hadoop-env.sh httpfs-site.xml mapred-queues.xml.template
hadoop-metrics2.properties kms-acls.xml mapred-site.xml.template
hadoop-metrics.properties kms-env.sh slaves
[root@master hadoop]# vim mapred-
mapred-env.cmd mapred-env.sh mapred-queues.xml.template mapred-site.xml.template
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
7
8 http://www.apache.org/licenses/LICENSE-2.0
9
10 Unless required by applicable law or agreed to in writing, softw are
11 distributed under the License is distributed on an "AS IS" BASIS ,
12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 See the License for the specific language governing permissions and
14 limitations under the License. See accompanying LICENSE file.
15 -->
16
17 <!-- Put site-specific property overrides in this file. -->
18
19 <configuration>
20 <property>
21 <name>mapreduce.framework.name</name>
22 <value>yarn</value>
23 </property>
24 </configuration>
[root@master hadoop]# vi yarn-site.xml
[root@master hadoop]# cat !$
cat yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- 关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>8.创建临时目录和文件目录
[root@master hadoop]# mkdir /usr/local/src/hadoop-2.6.5/tmp
[root@master hadoop]# mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
[root@master hadoop]# mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data9.配置master、slave1、slave2节点的环境变量,编辑~/.bashrc文件,增加如下环境变量
vim ~/.bashrc
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
#刷新环境变量
source ~/.bashrc10.从master节点拷贝安装包至slave1、slave2节点
scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5
scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.511.在master节点初始化Namenode
[root@master hadoop-2.6.5]# pwd
/usr/local/src/hadoop-2.6.5
[root@master hadoop-2.6.5]# ./bin/hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
19/08/27 07:05:34 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.11.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
STARTUP_MSG: classpath = /usr/local/src/hadoop-2.6.5/etc/hadoop:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/activation-1.1.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/guava-11.0.2.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/commons-net-3.1.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/servlet-api-2.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/httpclient-4.2.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/xz-1.0.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/slf4j-api-1.7.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/jersey-2.6.5/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.5-tests.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.6.5.jar:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.6.5.jar:/usr/local/src/hadoop-2.6.5/contrib/capacity-scheduler/*.jar:/usr/local/src/hadoop-2.6.5/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997; compiled by ‘sjlee‘ on 2016-10-02T23:43Z
STARTUP_MSG: java = 1.8.0_172
************************************************************/
19/08/27 07:05:34 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
19/08/27 07:05:34 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-7c5bbf4c-ea11-4088-8d8c-0f69117e3272
19/08/27 07:05:35 INFO namenode.FSNamesystem: No KeyProvider found.
19/08/27 07:05:35 INFO namenode.FSNamesystem: fsLock is fair:true
19/08/27 07:05:36 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
19/08/27 07:05:36 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
19/08/27 07:05:36 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
19/08/27 07:05:36 INFO blockmanagement.BlockManager: The block deletion will start around 2019 Aug 27 07:05:36
19/08/27 07:05:36 INFO util.GSet: Computing capacity for map BlocksMap
19/08/27 07:05:36 INFO util.GSet: VM type = 64-bit
19/08/27 07:05:36 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
19/08/27 07:05:36 INFO util.GSet: capacity = 2^21 = 2097152 entries
19/08/27 07:05:36 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
19/08/27 07:05:36 INFO blockmanagement.BlockManager: defaultReplication = 2
19/08/27 07:05:36 INFO blockmanagement.BlockManager: maxReplication = 512
19/08/27 07:05:36 INFO blockmanagement.BlockManager: minReplication = 1
19/08/27 07:05:36 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
19/08/27 07:05:36 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
19/08/27 07:05:36 INFO blockmanagement.BlockManager: encryptDataTransfer = false
19/08/27 07:05:36 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
19/08/27 07:05:36 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
19/08/27 07:05:36 INFO namenode.FSNamesystem: supergroup = supergroup
19/08/27 07:05:36 INFO namenode.FSNamesystem: isPermissionEnabled = true
19/08/27 07:05:36 INFO namenode.FSNamesystem: HA Enabled: false
19/08/27 07:05:36 INFO namenode.FSNamesystem: Append Enabled: true
19/08/27 07:05:36 INFO util.GSet: Computing capacity for map INodeMap
19/08/27 07:05:36 INFO util.GSet: VM type = 64-bit
19/08/27 07:05:36 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
19/08/27 07:05:36 INFO util.GSet: capacity = 2^20 = 1048576 entries
19/08/27 07:05:36 INFO namenode.NameNode: Caching file names occuring more than 10 times
19/08/27 07:05:37 INFO util.GSet: Computing capacity for map cachedBlocks
19/08/27 07:05:37 INFO util.GSet: VM type = 64-bit
19/08/27 07:05:37 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
19/08/27 07:05:37 INFO util.GSet: capacity = 2^18 = 262144 entries
19/08/27 07:05:37 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
19/08/27 07:05:37 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
19/08/27 07:05:37 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
19/08/27 07:05:37 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
19/08/27 07:05:37 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
19/08/27 07:05:37 INFO util.GSet: Computing capacity for map NameNodeRetryCache
19/08/27 07:05:37 INFO util.GSet: VM type = 64-bit
19/08/27 07:05:37 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
19/08/27 07:05:37 INFO util.GSet: capacity = 2^15 = 32768 entries
19/08/27 07:05:37 INFO namenode.NNConf: ACLs enabled? false
19/08/27 07:05:37 INFO namenode.NNConf: XAttrs enabled? true
19/08/27 07:05:37 INFO namenode.NNConf: Maximum size of an xattr: 16384
19/08/27 07:05:37 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1415755876-192.168.11.10-1566903937075
19/08/27 07:05:37 INFO common.Storage: Storage directory /usr/local/src/hadoop-2.8.2/dfs/name has been successfully formatted.
19/08/27 07:05:37 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/src/hadoop-2.8.2/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
19/08/27 07:05:37 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/src/hadoop-2.8.2/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
19/08/27 07:05:37 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/08/27 07:05:37 INFO util.ExitUtil: Exiting with status 0
19/08/27 07:05:37 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.11.10
************************************************************/12.启动集群
[root@master hadoop-2.6.5]# ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
resourcemanager running as process 7671. Stop it first.
slave1: starting nodemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-nodemanager-slave2.out13.查看hadoop集群状态
##master
[root@master hadoop-2.6.5]# jps
7671 ResourceManager
8584 Jps
8409 SecondaryNameNode
8234 NameNode
7758 NodeManager
##slave1
[root@slave1 hadoop]# jps
1379 DataNode
1460 NodeManager
1578 Jps
##slave2
[root@slave2 hadoop-2.6.5]# jps
1298 DataNode
1379 NodeManager
1476 Jps14.启动历史服务器
[root@master hadoop-2.6.5]# pwd
/usr/local/src/hadoop-2.6.5
[root@master hadoop-2.6.5]# ./sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/src/hadoop-2.6.5/logs/mapred-root-historyserver-master.out
此时注意查看selinux是否关闭且执行下面清楚防火墙iptables规则,否则在浏览器无法访问hadoop的监控Web界面
[root@master hadoop-2.6.5]# iptables -F
[root@master hadoop-2.6.5]# iptables -X
[root@master hadoop-2.6.5]# iptables -Z15.hadoop集群监控界面
[root@master hadoop-2.6.5]# curl -I http://master:8088
HTTP/1.1 302 Found
Cache-Control: no-cache
Expires: Tue, 27 Aug 2019 11:17:43 GMT
Date: Tue, 27 Aug 2019 11:17:43 GMT
Pragma: no-cache
Expires: Tue, 27 Aug 2019 11:17:43 GMT
Date: Tue, 27 Aug 2019 11:17:43 GMT
Pragma: no-cache
Content-Type: text/plain; charset=UTF-8
[root@master hadoop-2.6.5]# curl -I http://192.168.11.10:8088/
HTTP/1.1 302 Found
Cache-Control: no-cache
Expires: Tue, 27 Aug 2019 11:31:19 GMT
Date: Tue, 27 Aug 2019 11:31:19 GMT
Pragma: no-cache
Expires: Tue, 27 Aug 2019 11:31:19 GMT
Date: Tue, 27 Aug 2019 11:31:19 GMT
Pragma: no-cache
Content-Type: text/plain; charset=UTF-8
Location: http://192.168.11.10:8088/cluster
Content-Length: 0
Server: Jetty(6.1.26)
说明:
1.使用curl 命令测试web界面访问返回状态码是302
2.实际测试,在IE浏览器无法访问,只有在谷歌浏览器才能访问
192.168.11.10:8080/cluster二、Spark安装
1.下载软件包
地址:http://archive.apache.org/dist/spark/spark-2.0.2/spark-2.0.2-bin-hadoop2.6.tgz
把spark软件包上传至/usr/local/src2.下载scala软件包,下载地址:https://www.scala-lang.org/download/2.11.12.html
[root@master src]# pwd
/usr/local/src
[root@master src]# ll
total 590548
drwxrwxr-x 12 1000 1000 197 Sep 19 11:32 hadoop-2.6.5
-rw-r--r--. 1 root root 199635269 Jul 3 19:09 hadoop-2.6.5.tar.gz
drwxr-xr-x. 8 10 143 255 Mar 29 2018 jdk1.8.0_172
-rw-r--r--. 1 root root 190921804 Jul 3 19:09 jdk-8u172-linux-x64.tar.gz
drwxrwxr-x 6 1001 1001 50 Nov 9 2017 scala-2.11.12
-rw-r--r-- 1 root root 29114457 Oct 23 19:17 scala-2.11.12.tgz
drwxr-xr-x 12 500 500 193 Nov 7 2016 spark-2.0.2-bin-hadoop2.6
-rw-r--r-- 1 root root 185040619 Oct 23 18:50 spark-2.0.2-b3.分别解压spark和scala
[root@master src]#tar -xvf spark-2.0.2-bin-hadoop2.6.tgz
[root@master src]#tar -xvf scala-2.11.12.tgz4.配置服务的环境变量
[root@master conf]# pwd
/usr/local/src/spark-2.0.2-bin-hadoop2.6/conf
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vim spark-env.sh
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
export SCALA_HOME=/usr/local/src/scala-2.11.12
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/src/spark-2.0.2-bin-hadoop2.6
SPARK_DRIVER_MEMORY=1G
修改slaves文件,配置从节点主机名
[root@master conf]# ll
total 40
-rw-r--r-- 1 500 500 987 Nov 7 2016 docker.properties.template
-rw-r--r-- 1 500 500 1105 Nov 7 2016 fairscheduler.xml.template
-rw-r--r-- 1 500 500 2025 Nov 7 2016 log4j.properties.template
-rw-r--r-- 1 500 500 7239 Nov 7 2016 metrics.properties.template
-rw-r--r-- 1 500 500 865 Nov 7 2016 slaves.template
-rw-r--r-- 1 500 500 1292 Nov 7 2016 spark-defaults.conf.template
-rwxr-xr-x 1 root root 4160 Nov 18 02:50 spark-env.sh
-rwxr-xr-x 1 500 500 3861 Nov 7 2016 spark-env.sh.template
[root@master conf]# cp slaves.template slaves
[root@master conf]# vi slaves
# A Spark Worker will be started on each of the machines listed below.
slave1
slave2配置服务系统环境变量
[root@master conf]# vim ~/.bashrc
# .bashrc
# User specific aliases and functions
alias rm=‘rm -i‘
alias cp=‘cp -i‘
alias mv=‘mv -i‘
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
####在文件底部增加spark和scala系统环境变量###
#scale_path
export SCALA_HOME=/usr/local/src/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
#sparK_path
export SPARK_HOME=/usr/local/src/spark-2.0.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
复制环境变量到其他节点
scp -r ~/.bashrc root@slave1:~/
scp -r ~/.bashrc root@slave2:~/复制Scala包到从节点
[root@master conf]# scp -r /usr/local/src/scala-2.11.12 root@slave1:/usr/local/src/
[root@master conf]# scp -r /usr/local/src/scala-2.11.12 root@slave2:/usr/local/src/
复制Spark包到从节点
[root@master conf]# scp -r /usr/local/src/spark-2.0.2-bin-hadoop2.6 root@slave1:/usr/local/src/
[root@master conf]# scp -r /usr/local/src/spark-2.0.2-bin-hadoop2.6 root@slave2:/usr/local/src/
#重新加载环境变量
source ~/.bashrc启动spark集群
[root@master conf]# /usr/local/src/spark-2.0.2-bin-hadoop2.6/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark-2.0.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-2.0.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-2.0.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out查看服务进程
#Master: Master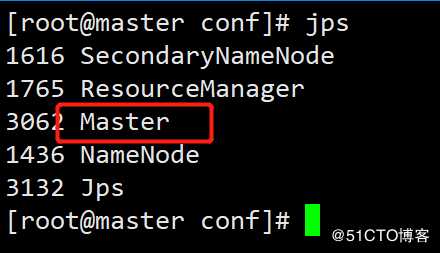
#Slave1: Worker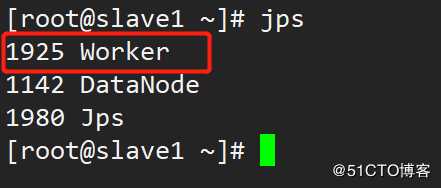
#Slave2: Worker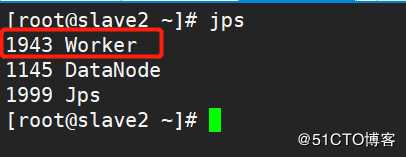
登陆网页控制台 http://master:8080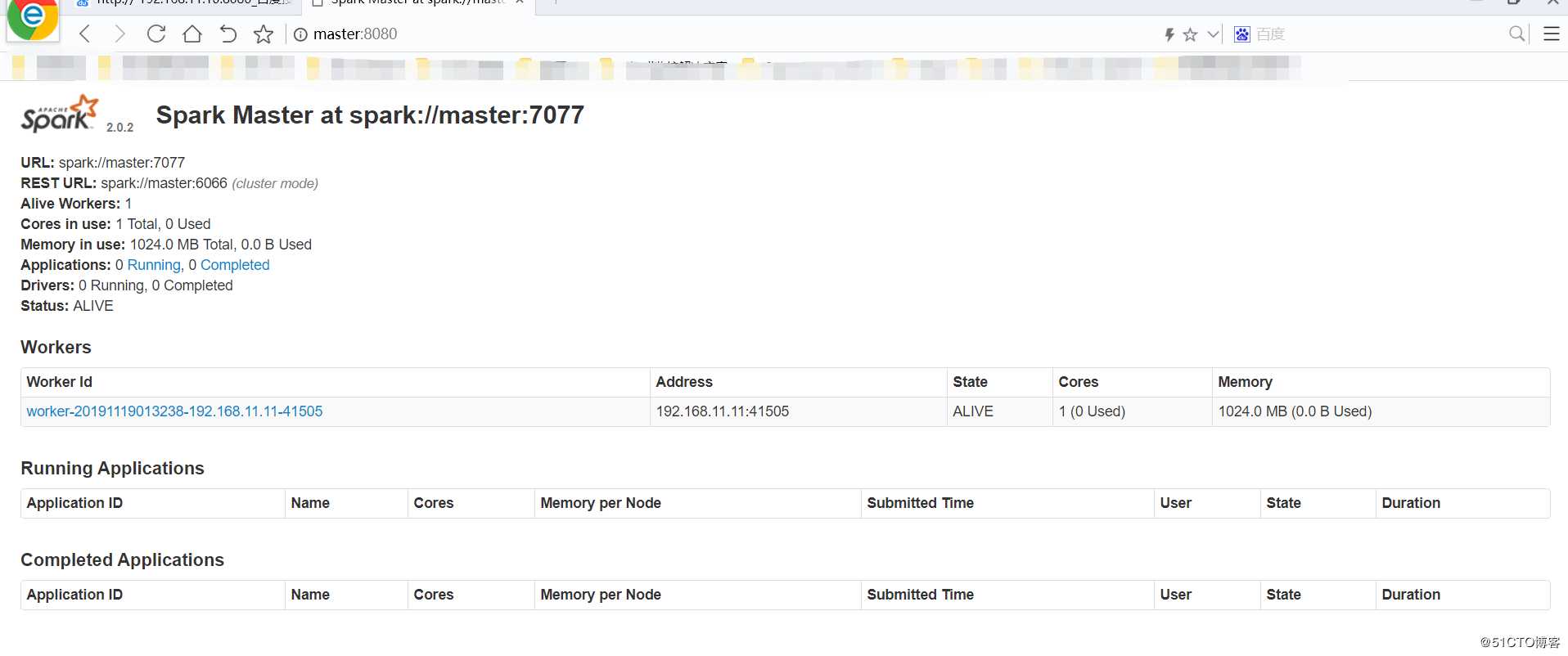
大数据之一:Hadoop2.6.5+centos7.5三节点大数据集群部署搭建
标签:func 拷贝 jetty var some 密码 wget admin prompt
原文地址:https://blog.51cto.com/liuleis/2465127