标签:raise col 网页 ODB mongodb 字节 模拟 重要 表达
HTTP,Hypertext Transfer Protocol 超文本传输协议
HTTP是一个基于"请求与响应"模式的,无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识。
URL格式:http://host[:post]\[path]
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
host:合法的Internet主机域名或者IP地址
port:端口号,缺省端口为80(默认为80)
path:请求资源的路径
HTTP协议对资源的操作



网络链接有风险,异常处理很重要:
#检测代码是否可以爬取
import requests
def getHTMLTEXT(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status() #如果状态码不是200,会出错
r.encoding = r.apparent_encoding
return r.text # 获取头部
except Exception as e:
return e
if __name__ == '__main__':
url = "http://baidu.com"
print(getHTMLTEXT(url))
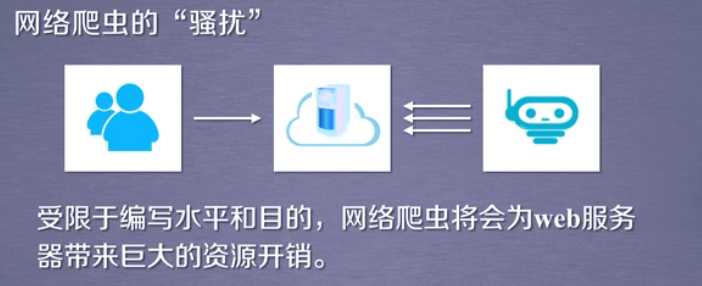




网络爬虫的流程:
获取网页:获取网页就是给一个网页发送请求,该网页会返回整个网页的数据,类似在浏览器中键入网站并且按回车键,然后就可以看到网站的整个内容。
解析网页(提取所需要的信息):就是从整个网页的数据中提取想要的数据,类似在浏览去中看到网站的整个网页,但是你需要提取你需要的信息
存储信息:一般可以存储在csv或者数据库中。
网络爬虫的技术实现:
掌握定向网络数据爬取和网页解析的基本能力
将网站当成API
自动爬取html页面,自动网络请求提交
最优秀的爬虫库
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| request.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| request.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| request.patch() | 向HTML网页提交局部修改请求,对应HTTP的PATCH |
| requests.delete() | 向THTML网页提交删除请求,对应HTTP的DELETE |
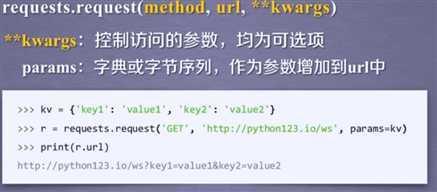
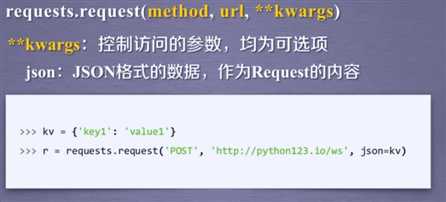
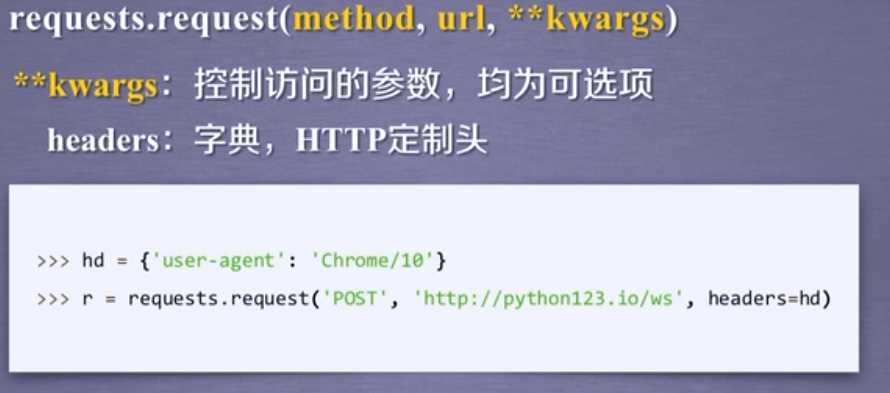
Requests库的2的重要对象
r = requests.get(url)
Response(包含了爬虫返回的所有内容)
| Response对象的属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示链接成功,404表示失败(一般来说除了200,其余都是失败的) |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTPheader中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出响应内容的编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式(主要是用于图片等) |
Request
r.status_code 状态码,如果为200,证明能爬虫成功,其余失败
r.headers 返回get请求获得页面的头部信息
如果r.header中不存在charset,可以认为编码方式维ISO-8859-1(这个可以通过r.encoding获得)
如果出现乱码,可以用r.apparent_encoding获得备用编码,然后用r.encoding = ‘获得的编码‘,也可以直接尝试r.encoding = ‘utf-8‘
Requests异常

| 异常 | 说明 |
|---|---|
| r.raise_for_status() | 如果不是200,产生异常requests.HTTPError |
#检测代码是否可以爬取
import requests
def getHTMLTEXT(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status() #如果状态码不是200,会出错
r.encoding = r.apparent_encoding
return r.text # 获取头部
except Exception as e:
return e
if __name__ == '__main__':
url = "http://baidu.com"
print(getHTMLTEXT(url))



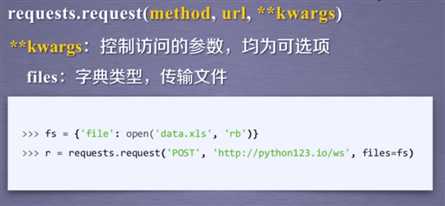

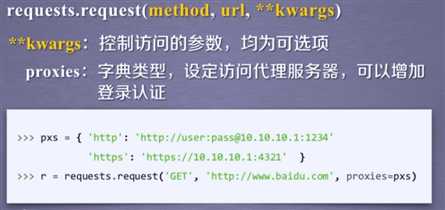








标签:raise col 网页 ODB mongodb 字节 模拟 重要 表达
原文地址:https://www.cnblogs.com/SkyOceanchen/p/12168174.html