标签:变化 连续 新闻 自己的 部门 for 地方 预测分析 basic
机器学习的专业术语非常多,不需要一开始理解所有的专业术语,这些术语会随着对机器学习的深入,会慢慢理解,水到渠成。
不过在学习的过程中,有一些概念必须要了解,有助于后续的学习与理解,需要了解的核心概念有:监督学习、无监督学习、模型、策略、算法等。
监督学习,指的是学习的数据与后续测试的数据,都有答案(标签)。
比如说,我们自己的相片集,里面每个人我们都知道是谁并可以标识出来,给机器学习时,我们将每个单人照和对应的名字提交给机器学习模型,机器学习模型完成学习以后,我们继续提交新的相片(单人或多人的),模型直接输出照片中每个人的名字。而对这类有标准答案的数据集的学习,就是有监督学习。
监督学习主要用来处理分类与回归两类问题。
监督学习常用算法包括:K最近邻算法、朴素贝叶斯算法、线性回归算法、逻辑回归算法、决策树算法、神经网络算法、支持向量机算法、因子分解机算法等
无监督学习,指的是通过对数据的统计、分析、分类等方法处理后,从中发现数据本身的自有规律,从而提取出对应的类别、知识或模型的学习方法。可以简单理解为,数据没有标准答案,甚至我们都不知道里面的答案,只知道有一堆数据,需要运行算法自动对这些数据进行各种分类处理,帮助我们找出规律(分类类别)的过程。
无监督学习主要概念:
比如DNA,每个个体都有相似与独特的地方,想要了解DNA中每个基因的作用,就可以使用无监督学习进行学习与分析,将具有不同类型或特特征的人聚集到一块,然后根据通过对这些人的共同点进行分析,从而得出特定基因的作用。同样,无监督学习可以应用到广告系统、推荐系统、新闻分类等各类系统中,面对海量的数据,从中找出不同的类型特征,帮助我们更快速的找到数据的特征与共性,从而让数据发挥更多更重要的作用。
无监督学习常用算法包括:K均值算法、最大期望算法、感知机算法、主成分分析算法、奇异值分解算法等。
半监督学习是监督学习与监督学习结合的一种方法,指的是将有标签数据和无标签数据一起提供模型学习的方法。
我们都知道人力成本是最贵的,如果需要对数据都打上标签,所花费的人工成本与时间成本是很可观的,况且有些数据我们也不清楚它们的规律无法添加标签。而半监督学习,可以将已知的有价值的数据先打上标签,跟无标签数据一起给机器进行学习,机器训练并输出结果,我们可对结果打上新的签标后继续提供给机器训练,从而提升预测结果,当然,如果标签标记不准确,也可能会误导训练模型,得出错误的结论。
无监督学习常用算法包括:协同训练算法(Co-Training)和转导支持向量机算法。
机器学习由模型、策略和算法组成。模型用于作出决策,策略用于评价决策,算法用于修正模型。
模型
简单的理解,指的是模子。
百度百科有两个解释我觉得很贴切:
机器学习中的模型,就是为了预测和分析指定的目标,运行已知的策略和算法,所构建的学习统计模型,通过对数据的学习(统计分析和找出其概率分布规律),最终能对目标进行准确预测。
策略
在百度百科中解释为:
策略,指计策;谋略。一般是指可以实现目标的方案集合;根据形势发展而制定的行动方针和斗争方法.
在机器学习中的策略,指的是实现模型方案集合的最优解。要实现同一个目标(模型),有无数种解决方案,而不同的解决方案各有优劣,在监督学习中引入了损失函数,来找出最优化的模型。
算法
在百度百科中解释为:
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。
算法简单理解,就是计算方法。在机器学习中,用什么样的计算方法,来帮助机器学习模型和策略,快速、高效、准确的计算出结果。在海量的数据与几何级复杂度的数据中,找出数据分布规律和概率,也是相当困难的,而机器学习算法模型中,提供了梯度下降、降维等算法,来求解出最优解,减少过拟合等各种问题。
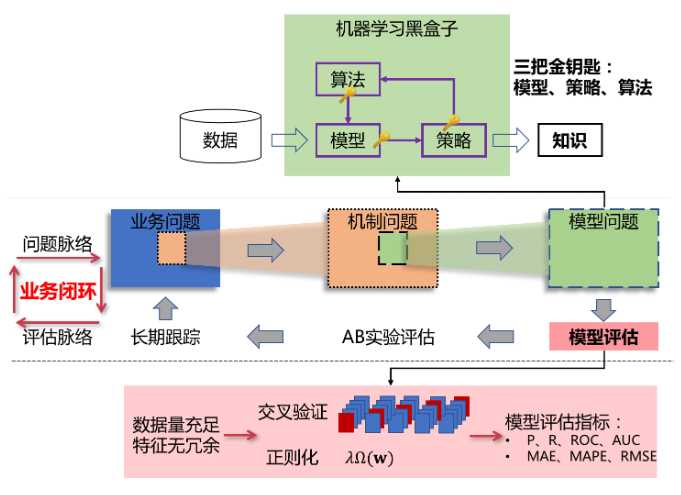
(图片来自:https://www.imooc.com/read/50/article/974)
问题线:业务问题 -> 机制问题 -> 模型问题
评估线:长期跟踪 <- AB实验 <- 模型评估
算法工程师对模型直接负责,对整个项目要有大局观
项目 -> 解决业务问题
例如:业务运营部门希望提升业务收入
业务问题 -> 分析拆解,找出关键指标 -> 得到解决方案(公式)-> 确定可控与不可控因素
指标1:提升新增用户量 = 渠道数 * 广告曝光量 * 用户转化比率 = 加大渠道投入
可控因素:渠道数量与广告曝光量(广告费)
不可控因素:用户转化比率
待分析问题:各渠道用户转化率差别?渠道推广投入的产出比盈亏状况?广告投放精准度与效果如何确认?相同渠道不同时间段投放广告,用户转化率变化?不同渠道同一时间段投放广告用户转化率有什么不同?视频广告与图文广告对用户转化率的影响?不同版本以及这些版本异常报告数量对用户转化率的影响?不同品牌用户转化率?不同机型用户转化率?是否存在刷量问题(新增用户的IP、机型、活跃变化、留存变化、在线时长、用户行为漏斗分析、充值转化比率……等问题的监控)?……
指标2:提升用户留存
指标3:提升用户充值比例
……
不可控因素 -> 如何变为可控?-> 建立机器学习预测分析模型 -> 什么算法模型适合当前问题?怎么设计和得出算法公式?为什么这个模型能对数据进行预测?
建立机器学习模型 -> 模型预测准确性?-> 算法层是否正确,对模型进行综合评估,确定预测模型正确率指标 -> 开展AB实验进行验证 -> 通过同比、环比等多项指标,评估推荐结果正确性 -> 全量推广,长期跟踪效果
https://github.com/apachecn/AiLearning/blob/master/docs/ml/1.机器学习基础.md
http://ai-start.com/ml2014/html/week1.html
https://feisky.xyz/machine-learning/basic.html
https://github.com/apachecn/scipycon-2018-sklearn-tut-zh/blob/master/1.md
https://github.com/apachecn/ml-for-humans-zh/blob/master/3.md
https://www.imooc.com/read/50/article/974
标签:变化 连续 新闻 自己的 部门 for 地方 预测分析 basic
原文地址:https://www.cnblogs.com/EmptyFS/p/12168425.html