标签:开源 个数 交互 节点 namenode 机器学习 自身 文件 hive
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)
硬件上;
而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX
的要求,
可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如C++。
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,
对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)
发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里
Hadoop是什么?
Hadoop: 适合大数据的分布式存储和计算平台
Hadoop不是指具体一个框架或者组件,它是Apache软件基金会下用Java语言开发的一个开源分布式计算平台。实现在大量计算机组成的集群中对海量数据进行
分布式计算。适合大数据的分布式存储和计算平台。
Hadoop1.x中包括两个核心组件:MapReduce和Hadoop Distributed File System(HDFS)
其中HDFS负责将海量数据进行分布式存储,而MapReduce负责提供对数据的计算结果的汇总
Hadoop的核心架构
Hadoop的核心,说白了,就是HDFS和MapReduce。HDFS为海量数据提供了存储,而MapReduce为海量数据提供了计算框架。
整个HDFS有三个重要角色:NameNode(名称节点)、DataNode(数据节点)和Client(客户机)。
MapReduce其实是一种编程模型。这个模型的核心步骤主要分两部分:Map(映射)和Reduce(归约)。
当你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,
当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
Hadoop的生态圈 经过时间的累积,Hadoop已经从最开始的两三个组件,发展成一个拥有20多个部件的生态系统。 在整个Hadoop架构中,计算框架起到承上启下的作用,一方面可以操作HDFS中的数据,另一方面可以被封装,提供Hive、Pig这样的上层组件的调用。 HBase:来源于Google的BigTable;是一个高可靠性、高性能、面向列、可伸缩的分布式数据库。 Hive:是一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,
十分适合数据仓库的统计分析。 Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的
MapReduce运算。 ZooKeeper:来源于Google的Chubby;它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度。 Ambari:Hadoop管理工具,可以快捷地监控、部署、管理集群。 Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。 Mahout:一个可扩展的机器学习和数据挖掘库。
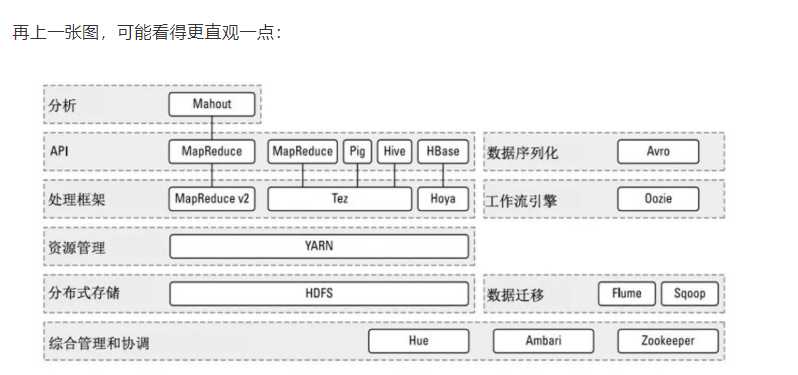
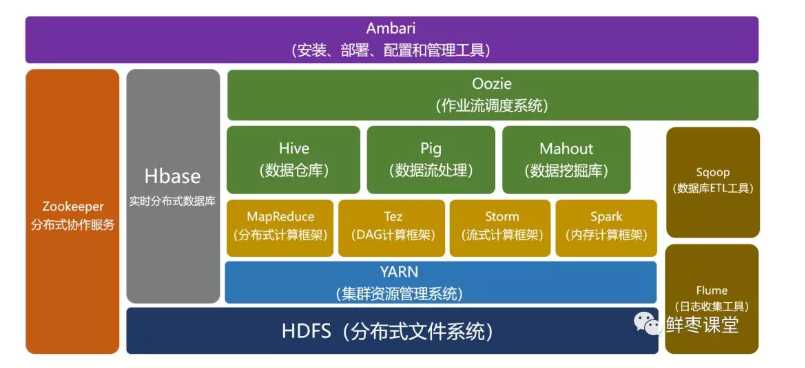
Hadoop的优点和应用
高可靠性:这个是由它的基因决定的。它的基因来自Google。Google最擅长的事情,就是“垃圾利用”。Google起家的时候就是穷,买不起高端服务器,所以,
特别喜欢在普通电脑上部署这种大型系统。虽然硬件不可靠,但是系统非常可靠。
高扩展性:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可以方便地进行扩展。说白了,想变大很容易。
高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。这个其实也算是高可靠性。
低成本:Hadoop是开源的,依赖于社区服务,使用成本比较低。
基于这些优点,Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量。
Hadoop的应用非常广泛,包括:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等,都可以使用它进行部署。
Hadoop和Spark
Spark同样是Apache软件基金会的顶级项目。它可以理解为在Hadoop基础上的一种改进。
它是加州大学伯克利分校AMP实验室所开源的类Hadoop MapReduce的通用并行框架。相对比Hadoop,它可以说是青出于蓝而胜于蓝。
前面我们说了,MapReduce是面向磁盘的。因此,受限于磁盘读写性能的约束,MapReduce在处理迭代计算、实时计算、交互式数据查询等方面并不高效。但是,
这些计算却在图计算、数据挖掘和机器学习等相关应用领域中非常常见。
而Spark是面向内存的。这使得Spark能够为多个不同数据源的数据提供近乎实时的处理性能,适用于需要多次操作特定数据集的应用场景。
在相同的实验环境下处理相同的数据,若在内存中运行,那么Spark要比MapReduce快100倍。其它方面,例如处理迭代运算、计算数据分析类报表、排序等,
Spark都比MapReduce快很多。
此外,Spark在易用性、通用性等方面,也比Hadoop更强。
所以,Spark的风头,已经盖过了Hadoop。
结语
相比于云计算技术来说,大数据的应用范围比较有限,并不是所有的公司都适用,也不是所有的业务场景都适用,没有必要跟风追捧,更不能盲目上马。
対于个人来说,大数据系统的架构非常庞大,内容也非常复杂,入门起来会比较吃力(实践练习倒是门槛很低,几台电脑足矣)。所以,如果不是特别渴望朝这个
方向发展,可以不必急于学习它。或者说,可以先进行初步的了解,后续如果真的要从事相关的工作,再进行深入学习也不迟。
标签:开源 个数 交互 节点 namenode 机器学习 自身 文件 hive
原文地址:https://www.cnblogs.com/654321cc/p/12169109.html