标签:spark 权重 误差 迭代 建模 规律 对话系统 笔记本 神经网络
主要应用领域: 自然语言处理, 图像识别
回想一波, 其实机器学习的本质, 是 构造一个函数.
具体一点是, 通过算法使得机器能够从大量历史数据中学习规律, 从而对新的样本做预测
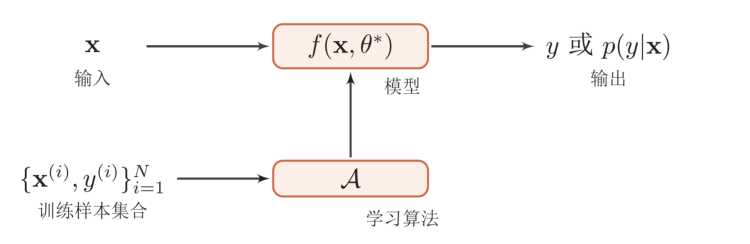
\(train: 输入: \{X^i, y^i\}_{i=1}^N \rightarrow \ 训练出算法模型 \ f(X, \theta*)\)
\(use: 输入: X_{new} \rightarrow \ 模型\ f(X, \theta*) \rightarrow y 或 p(y|x)\)
语音识别: \(f(一段声波) = \ "小陈同学好帅哦, 嗯嗯嗯..,"\)
对话系统: \(f("小陈同学能成为数据领域内的大咖嘛?") = "当然, 毕竟也积累多年了, 耐心, 恒心, 总会获得回报的.\)
传统 Machine Learning VS Deep Learning 的输入差异
传统 ML 的输入, 就是以多特征值这样的"表格"形式输入, 每行是一个样本. 属于结构化数据
图像,声音的输入, 必须将其作为一个整体, 这其实才是符合自然界的真实样本
另外, 从历史来看, 深度学习也已经有 80年 了. 从1940年的用铜丝, 电阻器件等来实现"学习", 到 50年代 提出 Perception 这样的普通学习算法, 到 1970年 提出 能解决异或问题 XOR ..再到1995年的 SVM, 也算火了10多年, 直到2010年以后, 深度学习才又回到ML的中心位置, 当然, 我感觉更多是硬件技术的发展.
1958年的感知机, 其实就是这样的一个计算过程:
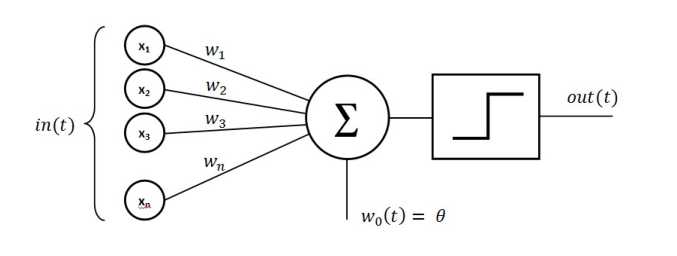
输入: x1, x2, x3, x5 x_n...
权重: w1, w2, w3...w_n
节点: \(\sum \limits _{i=1}^n w_ix_i\)
激活函数 : \(f(\sum \limits _{i=1}^n w_ix_i)\)
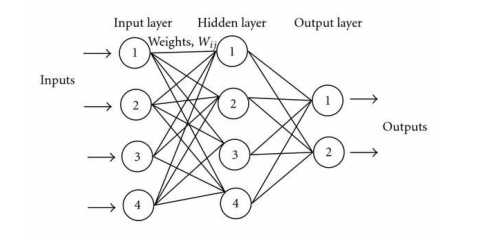
学界上已经证明了, 只要有一个隐含层 (Hidden layer) 的 3层神经网络, 可以拟合任意的函数
3层: 输入层, 隐函层, 输出层
为啥3层能模拟任何, 我们却还要搞什么深度神经网络, 卷积神经网络, 递归神经网络这些莫名的东西 ?
原因在是: 如果一个隐含层来模拟,则可能需要无数多个节点, 这样的时间, 空间负责度是不可想象的.
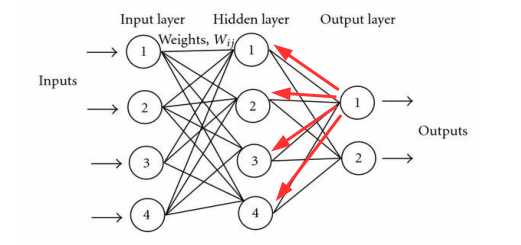
虽然通过3层, 可以去拟合任意函数, 增加节点就好了嘛, 但权值如何确定, 当时可能更多是靠经验, 不能通过机器自动去学习, 1982年产生的误差向后传递来, 自动调整权值的大小.
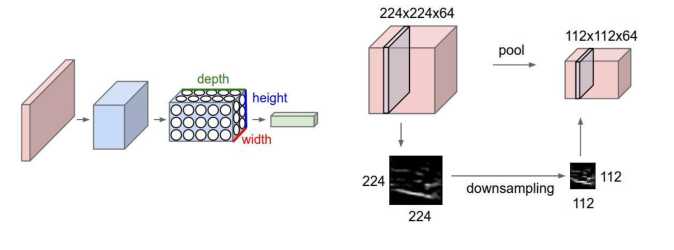
这两个词, 听着其实蛮奇怪的, 嗯, 卷积的本质工作呢, 其实就类似于 特征提取. 目的是 要用使用比普通全连接层的参数要少很多的一种网络, 即让网络相对简单, 同时也容易训练
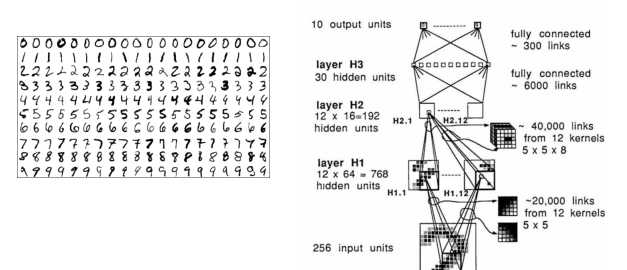
就是一个识别邮件信封的手写数字, 嗯,想想看, 这种识别, 在40年前就已经30年前就已经做出来了呀. 厉害了. 当时大概是有做30次迭代计算, 然后其准确率能都达到 92%, 相当可以的, 这可不减少了大量的人工操作了呀.
2010年以后, 就已经开始火爆了, 感觉我还上初中呢, 时代的潮流, 怕是赶不上了, 不对, 是不知道潮流的存在呀.
这真的是好多好深的技术哦, 很多都可以研究的, 虽然我只是想等大佬们开发好, 然后我 调API
之前有自己搭建 Hadoop平台的东西, 如HDFS, SPARK, HIVE ..这些, 体验了一把打分布式计算, 当时是整一个精准营销嘛, 结果计算了太慢了, 一个自己写的小算法, 我笔记本跑了一个星期, 感觉, 时间成本太高, 尤其对 算力 要求也大, 搞着搞着就没兴趣而, 写完核心算法的代码, 就不想搞了呀.
虽然我一直对深度学习, 没啥兴趣. 原因在于, 首先我感觉理论部分, 不太能学会, 就像,手推BP算法, 手撸BP代码 我感觉目前我还是有搞不定, 几度想要要放弃, 但有总想尝试, 这个过程挺煎熬的.
除了学习难度大, 不好debug外, 其解释性 不是很好, 里面的神经元节点到底发生了什么, 其实不可控的哦, 最直接的问题是, 跟老板汇报工作有点麻烦.
说个我真实感悟栗子, 我的理论背景其实是 营销学+统计学 大学毕业前,几段实习都是做 营销相关的, 市场调研, 商业数据统计, 建模, 活动执行, 策划这些... 其实理论和营销和统计这些, 后来工作才更偏向技术栈, 写代码这样子. 但凡只要学过统计的小伙伴都清楚, 其实从 机器学习的角度来看统计理论, 就是在做 过拟合, 因而大多统计理论, 并不太适合做商业分析推广, 然而统计学跟经济学有一个非常重要的特点就是 非常重视参数的可解释性, 哇, 这个真的太重要了, 主要是因为老板会觉得很重要, 而且能通过这些参数来分析业务指标, 是其价值的体现, 但如果用 深度学习这样的模型来整, 我感觉很多场景, 并不太适合. 咋说呢, 还是看应用场景哦.
这篇就大概说说神经网络是的小小历史, 后面, 当然是推导公式啦....这两天也回顾了一波 逻辑学的笔记, 这次不一样了, 请了帮手, 跟随Jerry大佬来推导, 嗯, 希望接下来看能推导清楚BP. 立个 Flag.
标签:spark 权重 误差 迭代 建模 规律 对话系统 笔记本 神经网络
原文地址:https://www.cnblogs.com/chenjieyouge/p/12169262.html