标签:列表 mat mamicode 运营商 扩容 整理 ons ali 在服务器
一、概述
二、CDN缓存
三、反向代理缓存
四、分布式缓存-memecache
五、分布式缓存-redis
六、memcache与redis对比
七、本地缓存
八、缓存架构示例
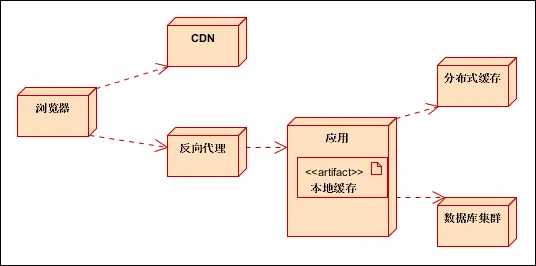
九、数据一致性(缓存属于持久化数据的一个副本,因此不可避免的会出现数据不一致问题)
十、缓存雪崩:雪崩是指当大量缓存失效时,导致大量的请求访问数据库,导致数据库服务器,无法抗住请求或挂掉的情况
十一、缓存穿透
标签:列表 mat mamicode 运营商 扩容 整理 ons ali 在服务器
原文地址:https://www.cnblogs.com/jayce9102/p/12170610.html