标签:长度 size twitter 需要 key image 它的 展示 turn
概念
布隆过滤器是概率型数据结构,由一个二进制向量和一系列随机映射函数组成。它可以用于检索一个元素是否在一个集合中。
实现过程
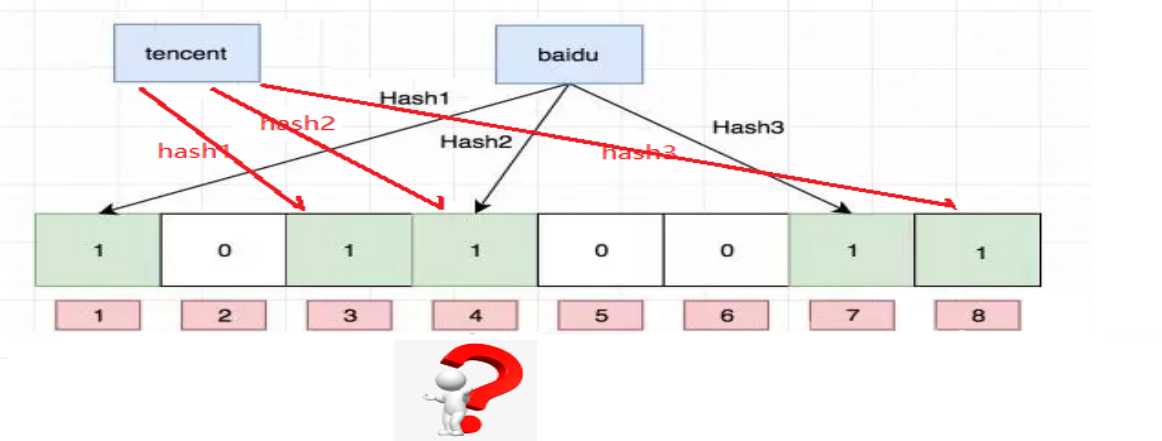
图例展示
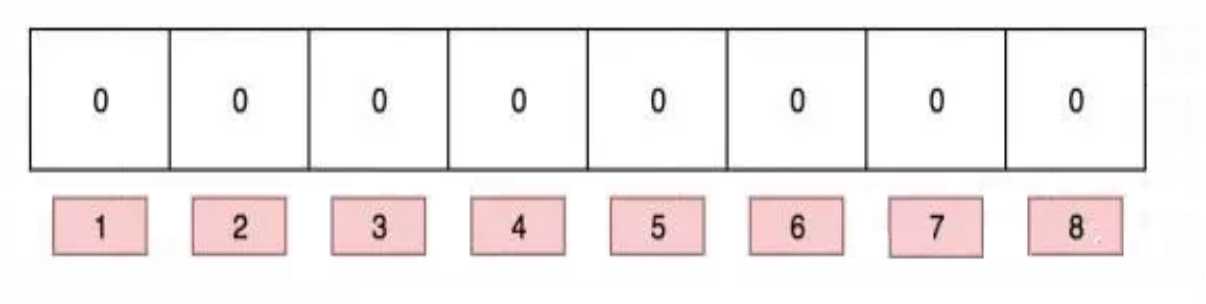
初始化向量,并赋予初值为0
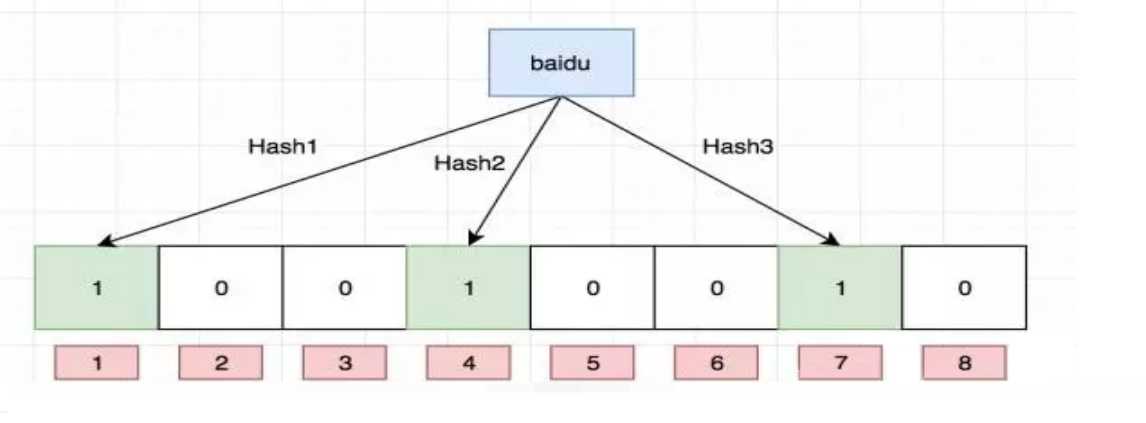
添加数据
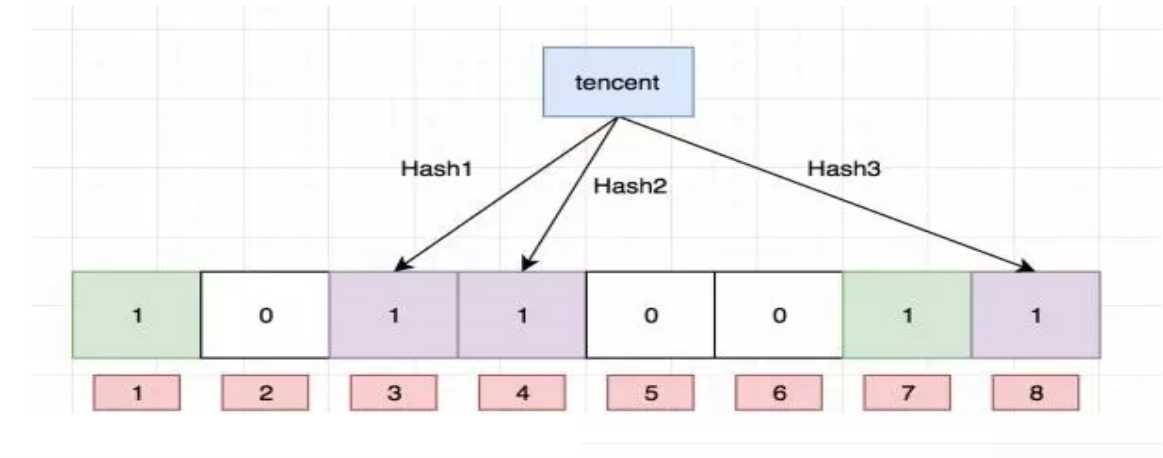
检查数据
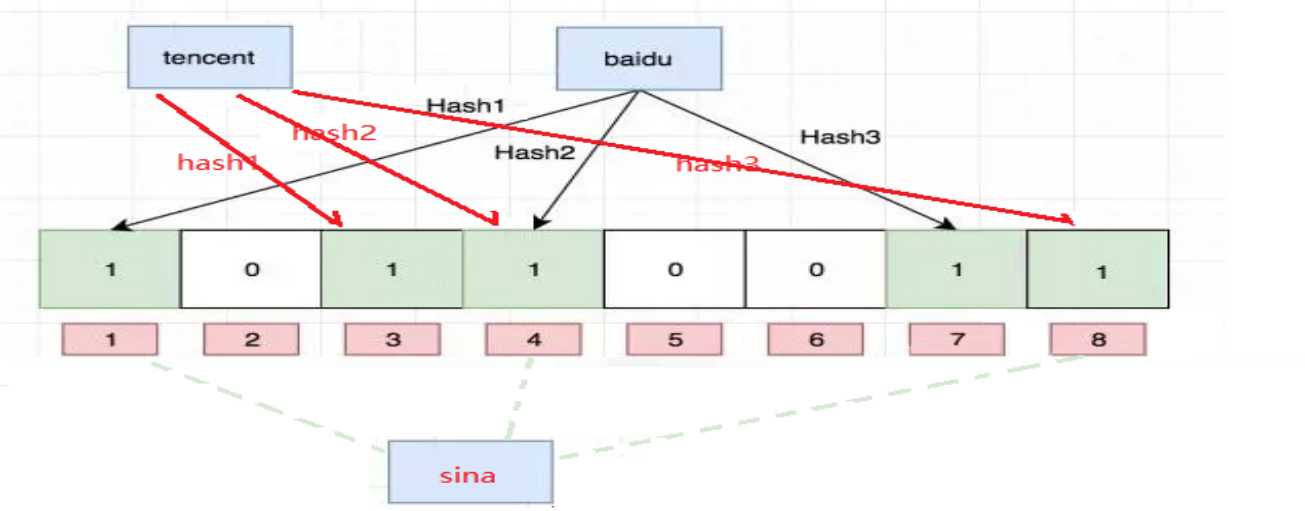
获取结论
只能判断这个数据完全不存在,但是不能完全判断其存在。
优势/劣势
代码实现
pip install mmh3pip install bitarrayfrom bitarray import bitarray
import mmh3
# 布隆过滤器实现类
class BloomFilter(set):
# 初始化函数,定义向量的长度,和hash的次数
def __init__(self, size, hash_count):
super(BloomFilter, self).__init__()
self.bit_array = bitarray(size)
self.bit_array.setall(0)
self.size = size
self.hash_count = hash_count
def __len__(self):
return self.size
def __iter__(self):
return iter(self.bit_array)
# 添加 数据到 布隆过滤器中
def add(self, item):
for ii in range(self.hash_count):
index = mmh3.hash(item, ii) % self.size
self.bit_array[index] = 1
return self
# 检查 hash值是否在向量中
def __contains__(self, item):
out = True
for ii in range(self.hash_count):
index = mmh3.hash(item, ii) % self.size
if self.bit_array[index] == 0:
out = False
return out
# 启动文件
if __name__ == '__main__':
bloom = BloomFilter(100, 10)
companys = ['sina','tencent','alibaba']
# 将数据添加到布隆过滤器中
for company in companys:
bloom.add(company)
# 查看你添加的公司是否都已已经添加到布隆过滤器中?
for company in companys:
if company in bloom:
print('{} 已添加'.format(company))
else:
print('{} 有问题'.format(company))
# 查看其他公司是否也在布隆过滤器里
other_companys = ['baidu','sina','facebook','twitter','microsoft','google','kingston','dajiang','douyu','momo','yy']
for other_company in other_companys:
if other_company in bloom:
print('{} 可能在布隆过滤器里'.format(other_company))
else:
print('{} 一定不在布隆过滤器里'.format(other_company))标签:长度 size twitter 需要 key image 它的 展示 turn
原文地址:https://www.cnblogs.com/wuxiaoshi/p/12170584.html