标签:颜色 组织 二手车 可视化 利用 调用 amp 生成 单元格
一, 缺失值的处理
处理缺失值的方法:需要理解数据,察觉到哪些数据是必要的哪些不必要
1, 删除法:
(1) 删整个列
(2) 删整行(丢弃此记录)
2, 填补法
(1) 用平均值来填补缺失值
(2) 均值,中位数填补
二,特征编码
——机器学习的核心是建模,基础是数据,且输入一定是数值类型的,因此要把字符串转为字符类型,向量或矩阵类型
——这个转换的过程叫类别特征
——最常用的编码技术叫 独热编码
对于标签编码,用0,1,2表示特征的取值,但数字之间有大小区别,影响较大
因此用向量来表示,
——在标签特征的基础上需要创建一个向量。这个向量的长度跟类别种类的个数相同。除了一个位置是1,其他位置均为0, 1的位置对应的是相应类别出现的位置。
三,数值型变量
——数值间有大小的区别,大小关系也是程度上的好坏
——常见的处理方式是直接看作数值型变量处理
四,KNN解决回归
首先明白什么是KNN的分类和回归
KNN(K近邻法)
输入为实例的特征向量,计算新数据与训练数据之间的距离,选取K个距离最近的数据进行分类或回归判断
对于分类问题:输出为实例的类别。分类时,对于新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。(计算该输入属于哪一类)
对于回归问题:输出为实例的值。回归时,对于新的实例,取其k个最近邻的训练实例的平均值为预测值。(已知该输入属于哪一类,根据它的类判断它的预测结果)
数据
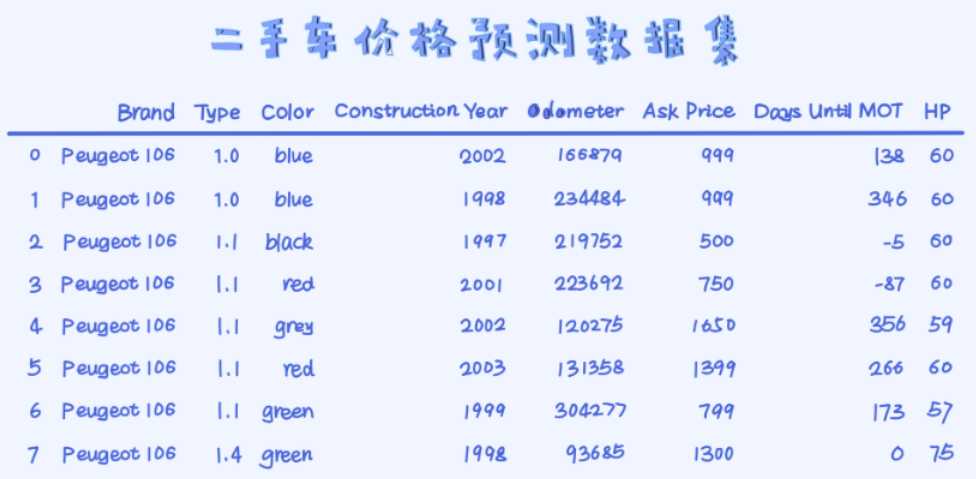
下面探讨如何用KNN来预测
1, 用read_csv(pd的)来读取数据
2, 进行特征处理,把特征型的两个个特征(颜色,类型)用独热编码进行转换
3, 用corr( )函数(独热编码sf.dummies()里的)来计算特征之间(包括全部数据)的相关性,并通过sns模块的heatmap来可视化相关性
4, 因为某些数据之间单位差的比较大(比如Odometer是5位数的,HP是两位数的)所以要对于数据进行特征的归一化,用StandardScaler来进行。
训练集是数值类型特征
测试集是我们要预测的ASK Price
5, 训练KNN模型,并用KNN模型做预测
训练KNN模型用的是训练集(X和y)
测试KNN模型用的是测试集(X和y)
#用X_test来预测(X是自变量)
y_pred = knn.predict(X_test)#作为X轴
y_test作为Y轴
因为X_test,y_test都经过了归一化,所以要化回来才能画图
如果预测值和实际值一样,所有的点会落在坐标轴上
1 #训练模型 2 knn=KNeighborsRegressor(n_neighbors=2)##训练出了模型 3 knn.fit(X_train,y_train.ravel())##把训练集带入? 4 #预测模型 5 #Now we can predict prices: 6 y_pred = knn.predict(X_test) 7 y_pred_inv=y_normalizer.inverse_transform(y_pred)#将标准化后的数据转换为原始数据 8 y_test_inv=y_normalizer.inverse_transform(y_test)# 9 #用KNN算法计算距离的时候要归一化,画图的时候回来
6, 打印最终的结果,即预测值 y_pred_inv
五,KD树
——优化 测试训练集和样本之间的距离 过程
提高KNN搜索的过程:
1, 根源在样本数量太多,所以从每一个类里选取有代表性的样本
2, 使用一种近似KNN的方法https://www.cs.umd.edu/~mount/ANN/
3, 使用KD树来加速搜索过程,一般使用在低维空间
KD树:
——肉眼可以看出哪些点离得比较近,如何使机器也能看出?
——根据它们的位置划分区域,每个区域的点很大可能会离得比较近
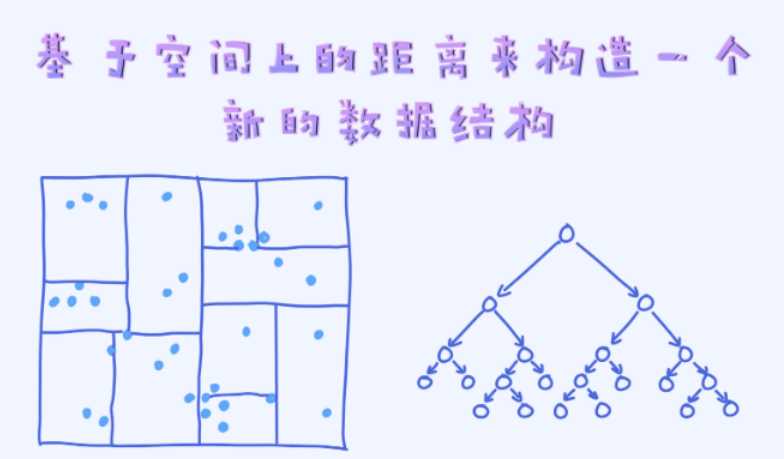
可以把KD树看做一种数据结构,每一个区域在KD树里是一个节点
如何基于样本来构造一棵KD树? https://blog.csdn.net/app_12062011/article/details/51986805
KD树小结: 1、通过KD树这样的数据结构尽可能减小搜索空间,从而提升效率。
2、一般只在低维(2、3维)的空间里才会试着使用KD树来提升搜索效率。因为随着特征维度的增加,搜索的时间复杂度会指数级增加。
KD树的经典应用场景:在地图上的搜索。如搜索离当前点最近的加油站、餐馆,等等。
---------------------------------------------------------------------------------------------------------------------------------------------
(1) 打开文件可以用open()函数,open函数有8个参数,不用全部输入也可,较重要的是fileName指定了要打开的文件名称,fileName的数据类型为字符串(单引号),fileName也包含了文件所在的存储路径,存储路径可以是相对路径,也可以是绝对路径。
encoding用于指定文件的编码方式,默认采用utf-8,编码方式主要是指文件中的字符编码。我们经常会碰到这样的情况,当打开一个文件时,内容全部是乱码,这是因为创建文件时采用的编码方式,和打开文件时的编码方式不一样,就会造成字符显示错误,看上去就是乱码。
f=open(‘D:\python3\Lib\二手车价格.csv‘,encoding=‘UTF-8‘)
(2) 独热编码用法:
https://blog.csdn.net/qq_43404784/article/details/89486442
独热编码就是将一列值为字符串的,变为值为0,1之类的数值,从标题为颜色,到标题为是否为红色/绿色
(3) pandas数据合并与重塑(pd.concat篇)
result = pd.concat([df1, df4], axis=1)
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
(4) df 发现不用print,直接列出变量名就可以得到值,比如给一个变量赋值,然后输入变量名,就可以显示变量的内容
但只能输出最后的一句
(5) matplotlib 中设置图形大小的语句如下:
fig = plt.figure(figsize=(a, b), dpi=dpi)
其中:
figsize 设置图形的大小,a 为图形的宽, b 为图形的高,单位为英寸
dpi 为设置图形每英寸的点数
则此时图形的像素为:
px, py = a*dpi, b*dpi # pixels
(6) 热图是数据的图形表示,也就是说,它使用颜色来向读者传达价值。
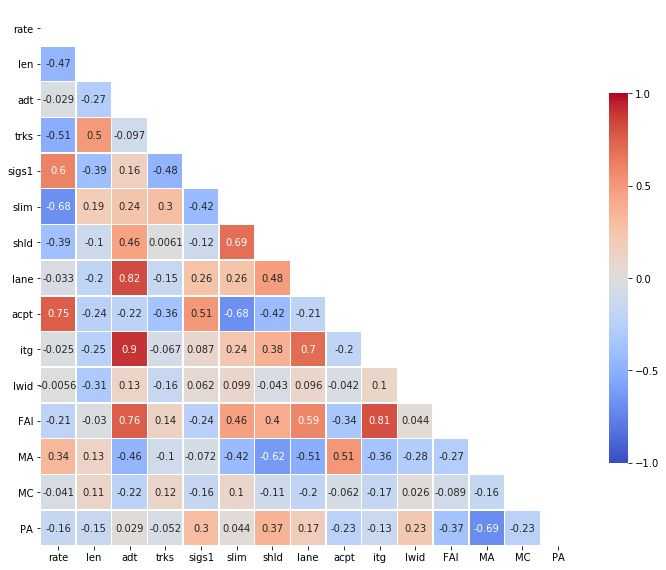
用df.corr()函数计算df文件的相关性,范围在-1-1间
使每个单元格成方形
square = True,
##通过sns模块来可视化相关性,颜色越深的代表相关性越大。
sns.heatmap(matrix,square=True)
(7) 特征的归一化,把原始特征转换成均值为0方差为1的高斯分布
## 注意:特征的归一化的标准一定要来自于训练数据,之后再把它应用在测试数据上。因为实际情况下,测试数据是我们看不到的,也就是统计不到均值和方差。
(8) 当直接使用df后接一个中括号时,表示取其一列,类型为Series,接2个中括号时,也是取一列,但类型为DataFrame(带有列名)
(9) shape是查看数据有多少行多少列
reshape()是数组array中的方法,作用是将数据重新组织
Reshape(-1,1)#行任意,列为1的数组

(10) X->自变量
y->因变量
train->训练集
test->测试集
从 sklearn.model_selection 中调用train_test_split 函数
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
X_train,X_test, y_train, y_test =sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.4, random_state=0,stratify=y_train)
# train_data:所要划分的样本特征集
# train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子。
# 随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
(11) StandardScaler----计算训练集的平均值和标准差,以便测试数据集使用相同的变换
(12) fit() 预处理的数据,计算矩阵列均值和列标准差
我们在训练集上调用fit_transform(),其实找到了均值μ和方差σ^2,即我们已经找到了转换规则,我们把这个规则利用在训练集上,同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据
(13)
因为在训练集已经找到转换规则,所以直接用到测试集上
X_train = X_normalizer.fit_transform(X_train)
X_test = X_normalizer.transform(X_test)
(14) k近邻分类
k-NN 算法最简单的版本是只考虑一个最近邻,即被预测的新的数据点离训练的数据集中的哪个点最近,它将被归类为哪个类别。
五角星为被预测的数据点,根据其离得最近的训练数据集,通过设置参数n_neighbors=1来设定“最近邻”的个数。
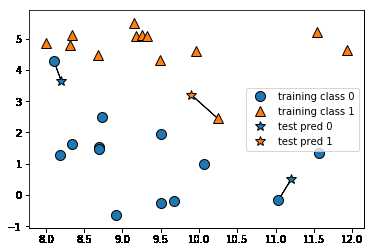
从上图我们就能明白,新数据离得谁最近,他就会被归类为哪一类。
左上角的五角星其实应该属于三角星一类,为了提高准确率,这里可以提高“最近邻”个数,即n_neighbors值。再来看一下当n_neighbors=3时的情况:
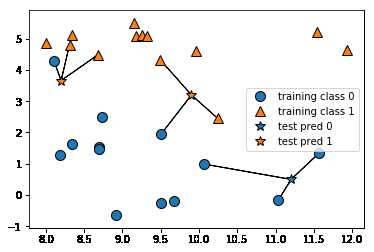
当提高“最近邻”的个数后,可以看到,对于新数据的预测更准确了,左上角的五角星近相近的是一个圆和两个三角星,因此它被归类于三角一类。
KNN分类树的类是KNeighborsClassifier,KNN回归树的类是KNeighborsRegressor
|
参数 |
KNeighborsClassifier |
KNeighborsRegressor |
|
KNN中的K值n_neighbors |
K值的选择与样本分布有关,一般选择一个较小的K值,可以通过交叉验证来选择一个比较优的K值,默认值是5。如果数据是三维一下的,如果数据是三维或者三维以下的,可以通过可视化观察来调参。 |
|
K近邻(回归)模型同样是无参数模型,只是借助K个最近训练样本的目标数值,对待测样本的回归值进行决策。即根据样本的相似度预测回归值(标准线)。
衡量样本待测样本回归值的不同方式:(1)对K个近邻目标数值使用普通的算术平均算法(2)对K个近邻目标数值考虑距离的差异进行加权平均。
KNN算法思想
1 计算已知类别中数据集的点与当前点的距离。[即计算所有样本点跟待分类样本之间的距离]
2 按照距离递增次序排序。[计算完样本距离进行排序]
3 选取与当前点距离最小的k个点。[选取距离样本最近的k个点]
4 确定前k个点所在类别的出现频率。[针对这k个点,统计下各个类别分别有多少个]
5 返回前k个点出现频率最高的类别作为当前点的预测分类。[k个点中某个类别最多,就将样本划归改点]
KNN工作原理
1 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
2 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
3 计算新数据与样本数据集中每条数据的距离。
4 对求得的所有距离进行排序(从小到大,越小表示越相似)。
5 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
6 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN算法的实现可以参考
https://www.cnblogs.com/xiaotan-code/p/6680438.html
knn =
KNeighborsClassifier()
#定义一个knn分类器对象
knn.fit(iris_x_train, iris_y_train)
#调用该对象的训练方法,主要接收两个参数:训练数据集及其样本标签
iris_y_predict = knn.predict(iris_x_test)
#调用该对象的测试方法,主要接收一个参数:测试数据集
probility=knn.predict_proba(iris_x_test)
#计算各测试样本基于概率的预测
neighborpoint=knn.kneighbors(iris_x_test[-1],5,False)
#计算与最后一个测试样本距离在最近的5个点,返回的是这些样本的序号组成的数组
score=knn.score(iris_x_test,iris_y_test,sample_weight=None)
#调用该对象的打分方法,计算出准确率
print(‘iris_y_predict = ‘)
print(iris_y_predict)
#输出测试的结果
(1) plt.scatter(x,y)#绘制散点图
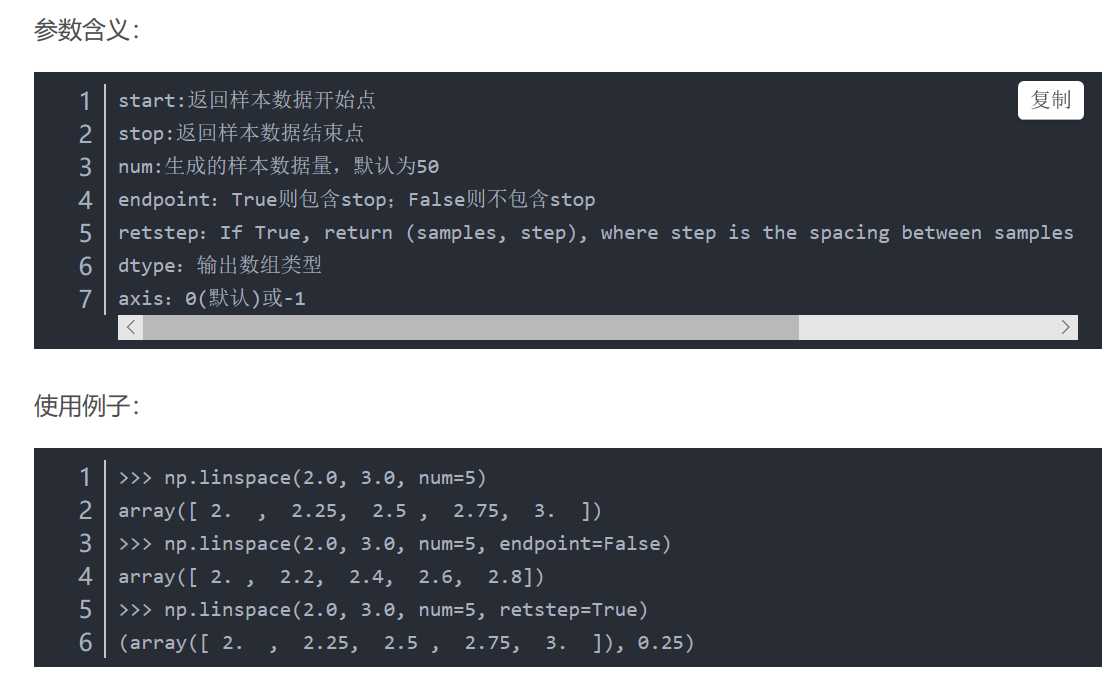
(2) np.linspace主要用来创建等差数列。
(17) plt.plot()函数的本质就是根据点连接线。根据x(数组或者列表) 和 y(数组或者列表)组成点,然后连接成线。
颜色控制符
要想使用丰富,炫酷的图标,我们可以使用更复杂的格式设置,主要颜色,线的样式,点的样式。
默认的情况下,只有一条线,是蓝色实线。多条线的情况下,生成不同颜色的实线。
|
字符 |
颜色 |
|
‘b‘ |
blue |
|
‘g‘ |
green |
|
‘r‘ |
red |
|
‘c‘ |
cyan 青色 |
|
‘m‘ |
magenta平红 |
|
‘y‘ |
yellow |
|
‘k‘ |
black |
|
‘w‘ |
white |
线形控制符
|
字符 |
类型 |
|
‘-‘ |
实线 |
|
‘--‘ |
虚线 |
|
‘-.‘ |
虚点线 |
|
‘:‘ |
点线 |
|
‘ ‘ |
空类型,不显示线 |
diagonal = np.linspace(500,1500,100)
plt.plot(diagonal,diagonal,‘-r‘)
---------------------------------------------------------------------------------------
总结:
可以一行一行来运行代码,更直观地了解每一行代码的作用
标签:颜色 组织 二手车 可视化 利用 调用 amp 生成 单元格
原文地址:https://www.cnblogs.com/tann/p/12173228.html