标签:pat 语义 根据 学习 通过 ima tail 效果 get
来到了第四天了,今天看的部分实在有太多问题了...一些词找了好久也没有相关的解释,以及还有一些有意思的词也跟前面的文章串联在了一起,只不过换了一些比较新的词,但往后挖会发现在18年时有很多很好的模型出现了,创新和学习果然无止境呐。
扎扎实实地夯实基础。奥力给puq!
今日更博:论文3.4 3.5 3.6
纠正:
ReID DAY3 中关于欧氏距离和余弦距离的关系的推导,在最后一步化简错了,最后一步的AB,不能写成dist(A,B),这样就变成了欧氏距离和欧氏距离的一个奇妙的错误的转换。所以最后的一步1-dist(A,B)删去。感谢白同学纠正!!
正文:
(1)图像的特征向量:
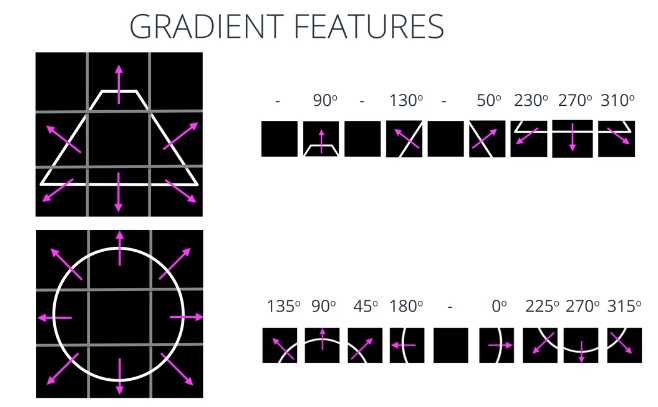
以这个梯形及其相应的梯度为例,这个图像已经检测好了边缘,以梯形中心为基准,观察每个单元的梯度方向,我们就可以将这个数据平面化,创建出一个一维数组,这就是特征向量;同样的,下面的圆的特征向量提取也是使用一样的方法。先检测出边缘,以圆心为基准,观察每个单元的梯度方向,然后创建出相应的特征向量(一维数组)。
(2)Spat Nets 与 Moti Nets 这两个网络暂无相关原理介绍
(3)分类损失:我自己之前使用的比较多的是交叉熵,我也没有注意过有这么多损失函数....总结一下就是在正负样本相差较大时,减少使用Exponential Loss,因为有可能在它作用的过程中给了距离群点较远的点较大的权重使这个点被惩罚,但可能是建立在牺牲了其他的正常数据点的预测效果为代价的,这会降低整体的一个分类的性能,使它不够鲁棒(robust)(指作用效果和稳定性没那么好)。
分类损失函数归结:https://blog.csdn.net/weixin_41065383/article/details/89413819
(4)利用深度学习提取深度特征:目前常使用的有Triplet loss以及改进的Quadruplet loss,即我们前面所说的三元组损失和四元组损失属于度量学习的两种方法。
同样的,还有学习哈希编码进行正则化约束的方法,这里不作探讨(因为我还不会,先不乱讲了...)
(5)自己今天的一个难以解决的问题:MSVF权重的设定是怎么设置的,为什么当一帧图像与平均特征距离越小则会给予该帧图像高的权重,但是在Exponential Loss中却是相差越多给予的权重越大,为什么呢?需要找到MSVF的相关资料再给出答案吧...挖个坑= =
(6)图片的注意力机制:注意力机制常用于NLP,我在没看这篇文章前我是不知道注意力机制能用于图片的.....
我找了一些文章,但感觉有点生涩,这个是我基于自己的理解来谈的,相关链接如下:
https://www.jianshu.com/p/9b922fb83d77
下面对于图片的注意力机制进行一个简要的概述:首先,注意力机制是什么呢,可以这么理解,当我们看到一副图像时是会高效分配有限的注意力资源的,举个栗子,当我们看到小狗是会注意小狗的鼻子、眼睛等,如图 ,那么同样的,在深度学习里面,注意力机制的核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
,那么同样的,在深度学习里面,注意力机制的核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
这里我们不讲注意力机制在NLP中的使用,我们讲在图像处理中的使用。
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
NLP的encoder-decoder是很经典的模型了,那么在图像处理(图像描述)中又是什么样的呢?如图: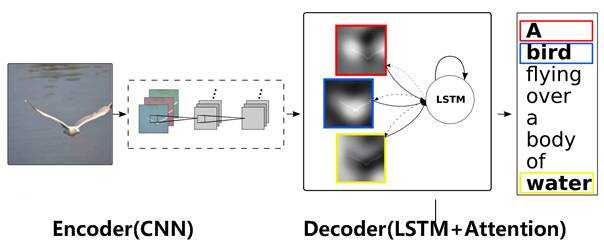
此时encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取,decoder部分使用RNN或者LSTM来输出自然语言句子
此时如果加入注意力(Attention)机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉(即我们上面所谈)选择性注意的机制,在输出某个单词的时候会将注意力焦点聚焦在图片中相应的区域上,在处理过程中的图片,如下:
会发现机器在进行图像处理的时候是把注意力集中放在不同位置的,即每个单词也有相应的注意力聚集区域。
这个是图像处理范围中的,没有找到给图像赋予权值的相关资料,但我们通过这种图像处理和之前的图像切块,也可以大致地猜测出,对每一帧图像赋予权重的过程实质上也是利用Attention机制对每张图的不同特点进行了一个分析,然后根据先前的模型(利用LSTM)赋予不同图片相应的权值。(仅个人理解,咳咳QWQ)
最小化判别损失:这个也就是我们前面所讲的GAN中所涉及的。判别(判别模型D)损失函数是一个与二元分类器(二元即两张不同出处的图片)相关的正则交叉熵损失函数。根据输入图像,损失函数中的一项或另一项将为0,结果将是模型预测图像被正确分类的概率的负对数。换句话说,对于真实图像,“y”将为“1”,对于假图像,“1-y”将为“1”。“p”是图像是真实图像的预测概率,“1-p”是图像是假图像的预测概率。式子如图: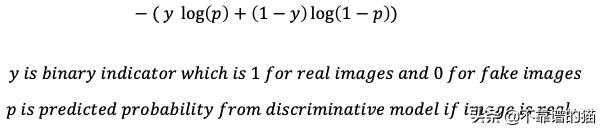
当然啦,在GAN中我们需要把p全部换成D(x),即判别图像正确的概率,或者你也可以把最后一个p换成D(G(x)), 这样的式子就是网上大多数GAN原理的表达式了。
(7)L2损失:既然谈到了L2损失,我们把L1损失和L2损失一起说了伐,放在一起好记emmm
首先,最容易想到的损失函数的定义,就是逐像素比较差异。但为了避免正值和负值相互抵消,我们可以对像素之差取绝对值或平方。
那么取绝对值则是L1损失: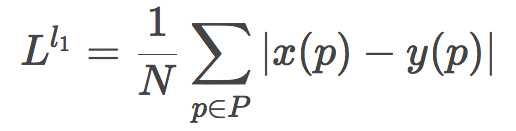
取平方则是L2损失: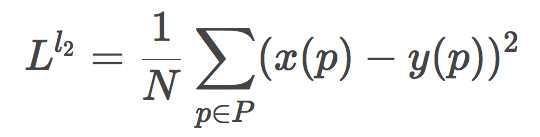
那么,它们有什么区别呢,为什么在损失中我们采用的是L2损失讷?
注意L2和L1有什么区别? 康!是不是L2多了一个平方,那么当误差较小(t<=1)时,这个平方是能容忍这个误差的,使它更小一点,而当(t>1)时,这个平方就会放大误差,使它收到更严重的惩罚,然后被out。那么,除此之外,它们也差不多hmmm....
而且,最近的文章也会发现L2损失会出现图像模糊等问题,开始了它的优化版SSIM、MS-SSIM损失函数,这个因为还不涉及,不往下探讨。
(8)孪生网络:这个网络有个很有意思的背景,理解起来也相对其他网络简单,这里直接放链接了,可以康康故事,故事挺有意思的,这篇回答也以问答式呈现,能更好的理解这个网络。
相关链接:https://www.jianshu.com/p/92d7f6eaacf5
(9)InfoGAN: 为什么没有用传统GAN讷?因为在传统GAN中generator(G)的输入是一个连续的噪声信号,并且没有任何约束,导致GAN将z的具体维度与输出(output)的语义特征对应起来,可解释性很差,所以引入了infoGAN。这个我接触的不多,怕引导错大家,自己找了一个比较好理解的
相关链接如:https://blog.csdn.net/wspba/article/details/54808833
今天的学习进度有点慢,有很多新知识和查不到的新知识hmmm...会努力找齐资料的!
标签:pat 语义 根据 学习 通过 ima tail 效果 get
原文地址:https://www.cnblogs.com/Warmchay/p/12173730.html