标签:cross span enc beta 合并 mic loss backward cti
官方原理图
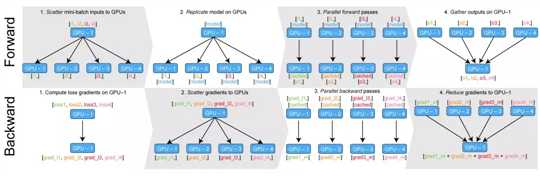
前向传播过程:将数据按照batch维度分发到各个GPU上(平均分配),而后将模型拷贝到GPU,各GPU并行前向传播,将各个输出(o1、02、03、04)汇总到总的GPU。
后向传播过程:在总GPU上并行计算得到损失,并得到初始梯度;将各梯度分发到各GPU;并行计算梯度;汇总梯度,更新网络参数。
参考代码如下
import os import torch import torch.nn as nn import Encoder os.environ[‘CUDA_VISIBLE_DEVICES‘]=‘0,1,2‘# 这里的0 就是主gpu, 1、2的模型和数据由主gpu分发 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") encoder=Encoder() encoder = encoder.to(device) # 这里将模型复制到gpu ,默认是cuda(‘0‘),即转到第一个GPU 2 decoder_optimizer = torch.optim.Adam(params=encoder.parameters(),lr=encoder_lr, betas = (0.8,0.999)) #定义优化器 criterion = nn.CrossEntropyLoss() if torch.cuda.device_count() > 1: encoder = torch.nn.DataParallel(encoder) # 前提是model已经在cuda上了 # 前向传播时数据也要放到GPU中,即复制到主gpu里 for batch_idx, (data, label) in train_data: data=data.to(device) label=label.to(device) prediction = encoder(data) # 这里的prediction 预测结果是由两个gpu合并过的,并行计算只存在在前向传播里 # 前向传播每个gpu计算量为 batch_size/torch.cuda.device_count() ,等前向传播完了将结果合到主gpu loss = criterion(prediction, label) # 计算loss optimizer.zero_grad() loss.backward()
标签:cross span enc beta 合并 mic loss backward cti
原文地址:https://www.cnblogs.com/AntonioSu/p/12178478.html