/*
回溯法字符串匹配算法就是用一个循环来找出所有有效位移,
该循环对n-m+1个可能的位移中的每一个index值,检查条件为P[0…m-1]= S[index…index+m-1]
(因为模式串的长度是m,索引范围为0…m-1)。该算法思维比较简单(但也常被一些公司做为面试题),
很容易分析出本算法的时间复杂度为O(pattern_length*target_length)
int search(char const*, int, char const*, int)
查找出模式串patn在主串src中第一次出现的位置
plen为模式串的长度
返回patn在src中出现的位置,当src中并没有patn时,返回-1
*/
int search(char const* src, int slen, char const* patn, int plen)
{
int i = 0, j = 0;
while( i < slen && j < plen )
{
if( src[i] == patn[j] ) //如果相同,则两者++,继续比较
{
++i;
++j;
}
else
{
//否则,指针回溯,重新开始匹配
i = i - j + 1; //退回到最开始时比较的位置
j = 0;
}
}
if( j >= plen )
return i - plen; //如果字符串相同的长度大于模式串的长度,则匹配成功
else
return -1;
}
/*
KMP算法可以在O(n+m)的时间数量级上完成串的模式匹配操作。
其基本思想是:每当匹配过程中出现字符串比较不等时,不需回溯i指针,
而是利用已经得到的“部分匹配”结果将模式向右“滑动”尽可能远的一段距离后,继续进行比较。
算法的核心关键在于查找匹配串的码表(确定部分匹配后要滑动距离)
*/
#include <stdio.h>
#include <string.h>
int index_KMP(char *s,char *t,int pos);
void get_next(char *t,int *);
char s[10]="abcacbcba";
char t[4]="bca";
int next[4];
int pos=0;
int main()
{
int n;
get_next(t,next);
n=index_KMP(s,t,pos);
printf("%d",n);
return 0;
}
int index_KMP(char *s,char *t,int pos)
{
int i=pos,j=1;
while (i<=(int)strlen(s)&&j<=(int)strlen(t))
{
if (j==0||s[i]==t[j-1])
{
i++;
j++;
}
else j=next[j];
}
if (j>(int)strlen(t))
return i-strlen(t)+1;
else
return 0;
}
void get_next(char *t,int *next)
{
int i=1,j=0;
next[0]=next[1]=0;
while (i<(int)strlen(t))
{
if (j==0||t[i]==t[j])
{
i++;
j++;
next[i]=j;
}
else j=next[j];
}
}#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
int next[1000]; //记录跳转位置
int kmp_next(char *base)
{
int i,j;
i=0;
j=-1;
next[0]=-1; //记录第一个字符的跳转位置为-1
while(base[i]!='\0')
{
//如果跳转到-1,说明只能从头开始匹配;
//如果当前匹配点和跳转后的匹配点匹配
if(j==-1||(base[i]==base[j]))
{
//查看下一匹配点的情况
i++;
j++;
//如果下一匹配点还是匹配的,则下一跳地址一样
if(base[i]==base[j])
{
next[i]=next[j];
}
//如果一匹配点不匹配,则下一跳地址为当前前缀地址
else
{
next[i]=j;
}
}
else
{
j=next[j];
}
}
}
int kmp(char *b,char *base)
{
int i,j;
i=0;j=0;
//通过跳转数组,进行快速匹配
while(b[i]!='\0'&&base[j]!='\0')
{
if(b[i]==base[j])
{
i++;j++;
}
else
{
j=next[j];
if(j==-1)
{
i++;j++;
}
}
}
if(base[j]=='\0')
{
return i-j;
}
else
return -1;
}
int main()
{
char base[]="abacba";
char b[1000];
kmp_next(base);
for(int i=0;i<strlen(base);i++)
{
printf("%d ",next[i]);
}
printf("\n %s\n",base);
while(scanf("%s",b)!=EOF)
{
printf("%d \n",kmp(b,base));
}
system("pause");
}
本KMP原文最初写于2年多前的2011年12月,因当时初次接触KMP,思路混乱导致写也写得非常混乱,如此,留言也是“骂声”一片。所以一直想找机会重新写下KMP,但苦于一直以来对KMP的理解始终不够,故才迟迟没有修改本文。
然近期因在北京开了个算法班,专门讲解数据结构、面试、算法,才再次仔细回顾了这个KMP,在综合了一些网友的理解、以及跟我一起讲算法的两位讲师朋友曹博、邹博的理解之后,写了9张PPT,发在微博上。随后,一不做二不休,索性将PPT上的内容整理到了本文之中(后来文章越写越完整,所含内容早已不再是九张PPT 那样简单了)。
KMP本身不复杂,但网上绝大部分的文章(包括本文的2011年版本)把它讲混乱了。下面,咱们从暴力匹配算法讲起,随后阐述KMP的流程 步骤、next 数组的简单求解 递推原理 代码求解,接着基于next 数组匹配,谈到有限状态自动机,next 数组的优化,KMP的时间复杂度分析,最后简要介绍两个KMP的扩展算法。
全文力图给你一个最为完整最为清晰的KMP,希望更多的人不再被KMP折磨或纠缠,不再被一些混乱的文章所混乱,有何疑问,欢迎随时留言评论,thanks。
假设现在我们面临这样一个问题:有一个文本串S,和一个模式串P,现在要查找P在S中的位置,怎么查找呢?
如果用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置,则有:
int ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
}
举个例子,如果给定文本串S “BBC ABCDAB ABCDABCDABDE”,和模式串P “ABCDABD”,现在要拿模式串P去跟文本串S匹配,整个过程如下所示:
1. S[0]为B,P[0]为A,不匹配,执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[1]跟P[0]匹配,相当于模式串要往右移动一位(i=1,j=0)
2. S[1]跟P[0]还是不匹配,继续执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[2]跟P[0]匹配(i=2,j=0),从而模式串不断的向右移动一位(不断的执行“令i = i - (j - 1),j = 0”,i从2变到4,j一直为0)
3. 直到S[4]跟P[0]匹配成功(i=4,j=0),此时按照上面的暴力匹配算法的思路,转而执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,可得S[i]为S[5],P[j]为P[1],即接下来S[5]跟P[1]匹配(i=5,j=1)
4. S[5]跟P[1]匹配成功,继续执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,得到S[6]跟P[2]匹配(i=6,j=2),如此进行下去
5. 直到S[10]为空格字符,P[6]为字符D(i=10,j=6),因为不匹配,重新执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,相当于S[5]跟P[0]匹配(i=5,j=0)
6. 至此,我们可以看到,如果按照暴力匹配算法的思路,尽管之前文本串和模式串已经分别匹配到了S[9]、P[5],但因为S[10]跟P[6]不匹配,所以文本串回溯到S[5],模式串回溯到P[0],从而让S[5]跟P[0]匹配。
而S[5]肯定跟P[0]失配。为什么呢?因为在之前第4步匹配中,我们已经得知S[5] = P[1] = B,而P[0] = A,即P[1] != P[0],故S[5]必定不等于P[0],所以回溯过去必然会导致失配。那有没有一种算法,让i 不往回退,只需要移动j 即可呢?
答案是肯定的。这种算法就是本文的主旨KMP算法,它利用之前已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。
int KmpSearch(char* s, char* p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}
向右移动4位后,S[10]跟P[2]继续匹配。为什么要向右移动4位呢,因为移动4位后,模式串中又有个“AB”可以继续跟S[8]S[9]对应着,从而不用让i 回溯。相当于在除去字符D的模式串子串中寻找相同的前缀和后缀,然后根据前缀后缀求出next 数组,最后基于next 数组进行匹配(不关心next 数组是怎么求来的,只想看匹配过程是咋样的,可直接跳到下文3.3.4节)。
比如对于字符串aba来说,它有长度为1的相同前缀后缀a;而对于字符串abab来说,它有长度为2的相同前缀后缀ab(相同前缀后缀的长度为k + 1,k + 1 = 2)。
比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1(相同前缀后缀的长度为k,k = 1)。

失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
下面,咱们就结合之前的《最大长度表》和上述结论,进行字符串的匹配。
如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。
由上文,我们已经知道,字符串“ABCDABD”各个前缀后缀的最大公共元素长度分别为:
而且,根据这个表可以得出下述结论
把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。意识到了这一点,你会惊呼原来next 数组的求解竟然如此简单:就是找最大对称长度的前缀后缀,然后整体右移一位,初值赋为-1(当然,你也可以直接计算某个字符对应的next值,就是看这个字符之前的字符串中有多大长度的相同前缀后缀)。
换言之,对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

根据最大长度表求出了next 数组后,从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
而后,你会发现,无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。为什么呢?因为:
所以,你可以把《最大长度表》看做是next 数组的雏形,甚至就把它当做next 数组也是可以的,区别不过是怎么用的问题。
接下来,咱们来写代码求下next 数组。
基于之前的理解,可知计算next 数组的方法可以采用递推:
向右移动4位后,模式串中的字符C继续跟文本串匹配。
对于P的前j+1个序列字符:
模式串的后缀:ABDE
模式串的前缀:ABC
前缀右移两位: ABC
用代码重新计算下“ABCDABD”的next 数组,以验证之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组是否正确,计算结果如下表格所示:
从上述表格可以看出,无论是之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组,还是之后通过代码递推计算求得的next 数组,结果是完全一致的。
下面,我们来基于next 数组进行匹配。
还是给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:
在正式匹配之前,让我们来再次回顾下上文2.1节所述的KMP算法的匹配流程:
匹配过程一模一样。也从侧面佐证了,next 数组确实是只要将各个最大前缀后缀的公共元素的长度值右移一位,且把初值赋为-1 即可。
我们已经知道,利用next 数组进行匹配失配时,模式串向右移动 j - next [ j ] 位,等价于已匹配字符数 - 失配字符的上一位字符所对应的最大长度值。原因是:
但为何本文不直接利用next 数组进行匹配呢?因为next 数组不好求,而一个字符串的前缀后缀的公共元素的最大长度值很容易求。例如若给定模式串“ababa”,要你快速口算出其next 数组,乍一看,每次求对应字符的next值时,还得把该字符排除之外,然后看该字符之前的字符串中有最大长度为多大的相同前缀后缀,此过程不够直接。而如果让你求其前缀后缀公共元素的最大长度,则很容易直接得出结果:0 0 1 2 3,如下表格所示:
然后这5个数字 全部整体右移一位,且初值赋为-1,即得到其next 数组:-1 0 0 1 2。
next 负责把模式串向前移动,且当第j位不匹配的时候,用第next[j]位和主串匹配,就像打了张“表”。此外,next 也可以看作有限状态自动机的状态,在已经读了多少字符的情况下,失配后,前面读的若干个字符是有用的。
行文至此,咱们全面了解了暴力匹配的思路、KMP算法的原理、流程、流程之间的内在逻辑联系,以及next 数组的简单求解(《最大长度表》整体右移一位,然后初值赋为-1)和代码求解,最后基于《next 数组》的匹配,看似洋洋洒洒,清晰透彻,但以上忽略了一个小问题。
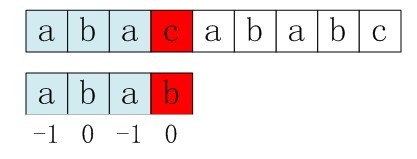
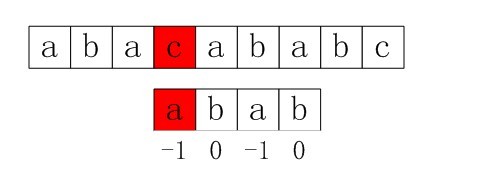
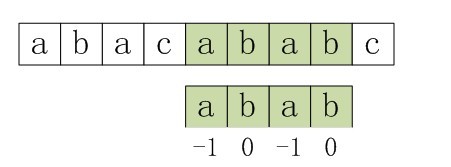
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。
右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?
问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。利用优化过后的next 数组求法,可知模式串“abab”的新next数组为:-1 0 -1 0。可能有些读者会问:原始next 数组是前缀后缀最长公共元素长度值右移一位, 然后初值赋为-1而得,那么优化后的next 数组如何快速心算出呢?实际上,只要求出了原始next 数组,便可以根据原始next 数组快速求出优化后的next 数组。还是以abab为例,如下表格所示:
只要出现了p[next[j]] = p[j]的情况,则把next[j]的值再次递归。例如在求模式串“abab”的第2个a的next值时,如果是未优化的next值的话,第2个a对应的next值为0,相当于第2个a失配时,下一步匹配模式串会用p[0]处的a再次跟文本串匹配,必然失配。所以求第2个a的next值时,需要再次递归:next[2] = next[ next[2] ] = next[0] = -1(此后,根据优化后的新next值可知,第2个a失配时,执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符”),同理,第2个b对应的next值为0。
对于优化后的next数组可以发现一点:如果模式串的后缀跟前缀相同,那么它们的next值也是相同的,例如模式串abcabc,它的前缀后缀都是abc,其优化后的next数组为:-1 0 0 -1 0 0,前缀后缀abc的next值都为-1 0 0。
然后引用下之前3.1节的KMP代码:
接下来,咱们继续拿之前的例子说明,整个匹配过程如下:
1. S[3]与P[3]匹配失败。
2. S[3]保持不变,P的下一个匹配位置是P[next[3]],而next[3]=0,所以P[next[3]]=P[0]与S[3]匹配。
3. 由于上一步骤中P[0]与S[3]还是不匹配。此时i=3,j=next [0]=-1,由于满足条件j==-1,所以执行“++i, ++j”,即主串指针下移一个位置,P[0]与S[4]开始匹配。最后j==pLen,跳出循环,输出结果i - j = 4(即模式串第一次在文本串中出现的位置),匹配成功,算法结束。
“KMP的算法流程:
我们发现如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。
所以,如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。
KMP的匹配是从模式串的开头开始匹配的,而1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹配算法:Boyer-Moore算法,简称BM算法。该算法从模式串的尾部开始匹配,且拥有在最坏情况下O(N)的时间复杂度。在实践中,比KMP算法的实际效能高。
BM算法定义了两个规则:
下面举例说明BM算法。例如,给定文本串“HERE IS A SIMPLE EXAMPLE”,和模式串“EXAMPLE”,现要查找模式串是否在文本串中,如果存在,返回模式串在文本串中的位置。
1. 首先,"文本串"与"模式串"头部对齐,从尾部开始比较。"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符,它对应着模式串的第6位。且"S"不包含在模式串"EXAMPLE"之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到"S"的后一位。
2. 依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在模式串"EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。
3. 依次比较,得到 “MPLE”匹配,称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。
4. 发现“I”与“A”不匹配:“I”是坏字符。如果是根据坏字符规则,此时模式串应该后移2-(-1)=3位。问题是,有没有更优的移法?
5. 更优的移法是利用好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串中上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
6. 继续从尾部开始比较,“P”与“E”不匹配,因此“P”是“坏字符”,根据“坏字符规则”,后移 6 - 4 = 2位。因为是最后一位就失配,尚未获得好后缀。
由上可知,BM算法不仅效率高,而且构思巧妙,容易理解。
上文中,我们已经介绍了KMP算法和BM算法,这两个算法在最坏情况下均具有线性的查找时间。但实际上,KMP算法并不比最简单的c库函数strstr()快多少,而BM算法虽然通常比KMP算法快,但BM算法也还不是现有字符串查找算法中最快的算法,本文最后再介绍一种比BM算法更快的查找算法即Sunday算法。
Sunday算法由Daniel M.Sunday在1990年提出,它的思想跟BM算法很相似:
下面举个例子说明下Sunday算法。假定现在要在文本串"substring searching algorithm"中查找模式串"search"。
1. 刚开始时,把模式串与文本串左边对齐:
substring searching algorithm
search
^
2. 结果发现在第2个字符处发现不匹配,不匹配时关注文本串中参加匹配的最末位字符的下一位字符,即标粗的字符 i,因为模式串search中并不存在i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符n)开始下一步的匹配,如下图:
substring searching algorithm
search
^
3. 结果第一个字符就不匹配,再看文本串中参加匹配的最末位字符的下一位字符,是‘r‘,它出现在模式串中的倒数第3位,于是把模式串向右移动3位(r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个‘r‘对齐,如下:
substring searching algorithm
search
^
4. 匹配成功。
回顾整个过程,我们只移动了两次模式串就找到了匹配位置,缘于Sunday算法每一步的移动量都比较大,效率很高。完。
原文地址:http://blog.csdn.net/txl199106/article/details/40683945