标签:分布 文章 集群 超过 地方 两种 http 运行 指正
1. 首先zookeeper是什么
zookeeper是一个开放源代码的分布式应用程序协调服务,可以把它看成是整个集群的管理者,监视者。
2. zookeeper能做什么
它可以实现诸如分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能。
3. zookeeper服务与kafka集群的联系
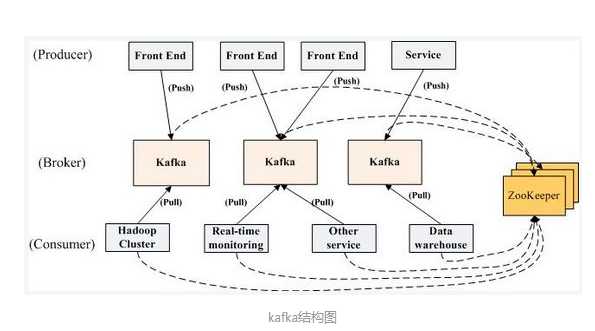
这里首先说一下broker的概念:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker,每个broker服务器都要连接到zk服务。
4. Leader选举流程。
选举流程主要出现在以下两种情况发生时:
(1)服务器初始化启动时;
(2)服务器在运行期间leader出现故障。
由于涉及到算法和流程较复杂,这里就以个人理解浅显的描述以下选举过程,如有不当的地方欢迎指正。
当服务器在初始化时启动:
假设集群中共有3台机器,分别使用server1、server2、server3等来表示,按编号以此启动起来。
第一步:每个server发起一个投票,推荐自己作为leader服务器,投票内容为(Serverid,Zxid),分别表示服务器ID、数据ID(服务器中存放定的最大数据ID)。由于server1先启动,它的投票为(1,0),然后进入Looking状态;
第二步:server2启动,发起投票为(2,0),并与已启动的server1交换结果,由于server2的编号2大于1,因此胜出,并告知server1。
第三步:server1将自己的投票改为(2,0),并重新投票。而server继续维持之前投票(2,0)。这个时候统计第二轮投票,server2以两票胜出,同时判断当前投票人数为2,已经超过3台服务器的50%,因此结果生效,server2当选为Leader,状态变为LEADING;server1状态变为FOLLOWING。
第四部:此时server3启动,发现Leader已经存在,则直接将自己的状态调整为FOLLOWING。
注意:如果集群中有5台机器,那么由于投票人数不足50%,则需要保持Looking状态,继续等待新的投票者加入,直到超过50%为止。
当服务器在运行期间leader出现故障:
第一步:假设server2作为leader挂了之后,剩下所有机器都会将自己的状态改为LOOKING,然后开始Leader选举过程。
第二步:server1发出投票为(1,233),server3发出投票为(3,222)。
第三步:两台机器互相接收来自别的服务器的投票,判断投票的有效性(是否来自LOOKING状态的服务器),然后进行将别人的投票与自己的投票进行PK,PK规则如下:1.优先检查Zxid,Zxid较大的优先作为leader;2.如果Zxid相同,那么Serverid较大的胜出。对于当前情况来看,server1胜出。
第四步:发起第二轮投票,server3将自己投票改为(1,233),server1保持不变(1,233),此时判断投票人数超过半数,server1胜出,当选为新leader。server1状态改为LEADING,server3状态改为FOLLOWING。
参考文章:《zookeeper的leader选举过程》
https://blog.csdn.net/virtil33/article/details/94343215
kafka中对于zookeeper的理解和leader选举过程
标签:分布 文章 集群 超过 地方 两种 http 运行 指正
原文地址:https://www.cnblogs.com/jockeyhao/p/12180176.html