标签:parse val function height 输出 空格 user lin 多次
combineByKey的强大之处,在于提供了三个函数操作来操作一个函数。第一个函数,是对元数据处理,从而获得一个键值对。第二个函数,是对键值键值对进行一对一的操作,即一个键值对对应一个输出,且这里是根据key进行整合。第三个函数是对key相同的键值对进行操作,有点像reduceByKey,但真正实现又有着很大的不同。
在Spark入门(五)--Spark的reduce和reduceByKey中,我们用reduce进行求平均值。用combineByKey我们则可以求比平均值更为丰富的事情。现在有一个数据集,每一行数据包括一个a-z字母和一个整数,其中字母和整数之间以空格分隔。现在要求得每个字母的平均数。这个场景有点像多个学生,每个学生多门成绩,求得学生的平均分。但这里将问题简化,其中数据集放在grades中。数据集以及下面的代码都可以在github上下载。
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkCombineByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkCombineByKey")
val sc = new SparkContext(conf)
sc.textFile("./grades").map(line=>{
val splits = line.split(" ")
(splits(0),splits(1).toInt)
}).combineByKey(
value => (value,1),
(x:(Int,Int),y)=>(x._1+y,x._2+1),
(x:(Int,Int),y:(Int,Int))=>(x._1+y._1,x._2+y._2)
).map(x=>(x._1,x._2._1/x._2._2)).foreach(println)
}
}
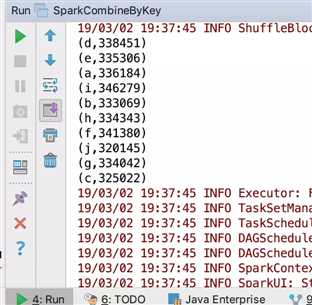
(d,338451)
(e,335306)
(a,336184)
(i,346279)
(b,333069)
(h,334343)
(f,341380)
(j,320145)
(g,334042)
(c,325022)
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.sources.In;
import scala.Tuple2;
public class SparkCombineByKeyJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkCombineByKeyJava");
JavaSparkContext sc = new JavaSparkContext(conf);
combineByKeyJava(sc);
combineByKeyJava8(sc);
}
public static void combineByKeyJava(JavaSparkContext sc){
JavaPairRDD<String,Integer> splitData = sc.textFile("./grades").mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
String[] splits = s.split(" ");
return new Tuple2<>(splits[0],Integer.parseInt(splits[1]));
}
});
splitData.combineByKey(new Function<Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<>(integer, 1);
}
}, new Function2<Tuple2<Integer, Integer>, Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> integerIntegerTuple2, Integer integer) throws Exception {
return new Tuple2<>(integerIntegerTuple2._1 + integer, integerIntegerTuple2._2 + 1);
}
}, new Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> integerIntegerTuple2, Tuple2<Integer, Integer> integerIntegerTuple22) throws Exception {
return new Tuple2<>(integerIntegerTuple2._1+integerIntegerTuple22._1,integerIntegerTuple2._2+integerIntegerTuple22._2);
}
}).map(new Function<Tuple2<String,Tuple2<Integer,Integer>>, Tuple2<String,Double>>() {
@Override
public Tuple2<String,Double> call(Tuple2<String, Tuple2<Integer, Integer>> stringTuple2Tuple2) throws Exception {
return new Tuple2<>(stringTuple2Tuple2._1,stringTuple2Tuple2._2._1*1.0/stringTuple2Tuple2._2._2);
}
}).foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
System.out.println(stringDoubleTuple2._1+" "+stringDoubleTuple2._2);
}
});
}
public static void combineByKeyJava8(JavaSparkContext sc){
JavaPairRDD<String,Integer> splitData = sc.textFile("./grades").mapToPair(line -> {
String[] splits = line.split(" ");
return new Tuple2<>(splits[0],Integer.parseInt(splits[1]));
});
splitData.combineByKey(
x->new Tuple2<>(x,1),
(x,y)->new Tuple2<>(x._1+y,x._2+1),
(x,y)->new Tuple2<>(x._1+y._1,x._2+y._2)
).map(x->new Tuple2(x._1,x._2._1*1.0/x._2._2)).foreach(x->System.out.println(x._1+" "+x._2));
}
}
d 338451.6
e 335306.7480769231
a 336184.95321637427
i 346279.497029703
b 333069.8589473684
h 334343.75
f 341380.94444444444
j 320145.7618069815
g 334042.37605042016
c 325022.4183673469
在开始python之前,我们先观察java和scala两个程序。我们发现java7的代码非常冗余,而java8和scala则相比起来非常干净利落。当然,我们难说好坏,但是这也表现出当代语言开始从繁就简的一个转变。到了python这一特点就体现的更加淋漓尽致。
但我们不光说语言,我们分析这个求平均的实现方式,由于java中对数值做了一个处理,因此有保留小数,而scala则没有,但至少可以判断两者的结果是一致的。当然,这不是重点,重点是,这个combinByKey非常复杂,有三个函数。我们很难观察到每个过程做了什么。因此我们在这里,对scala程序进行进一步的输出,从而观察combineByKey到底做了什么。
import org.apache.spark.{SparkConf, SparkContext}
object SparkCombineByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkCombineByKey")
val sc = new SparkContext(conf)
sc.textFile("./grades").map(line=>{
val splits = line.split(" ")
(splits(0),splits(1).toInt)
}).combineByKey(
value => {
println("这是第一个函数")
println("将所有的值遍历,并放在元组中,标记1")
println(value)
(value,1)
},
(x:(Int,Int),y)=>{
println("这是第二个函数")
println("将x中的第一个值进行累加求和,第二个值加一,求得元素总个数")
println("x:"+x.toString())
println("y:"+y)
(x._1+y,x._2+1)
},
(x:(Int,Int),y:(Int,Int))=>{
(x._1+y._1,x._2+y._2)
}
).map(x=>(x._1,x._2._1/x._2._2)).foreach(println)
}
}
这是第一个函数
将所有的值遍历,并放在元组中,标记1
222783
这是第一个函数
将所有的值遍历,并放在元组中,标记1
48364
这是第一个函数
将所有的值遍历,并放在元组中,标记1
204950
这是第一个函数
将所有的值遍历,并放在元组中,标记1
261777
...
...
...
这是第二个函数
将x中的第一个值进行累加求和,第二个值加一,求得元素总个数
x:(554875,2)
y:357748
这是第二个函数
将x中的第一个值进行累加求和,第二个值加一,求得元素总个数
x:(912623,3)
y:202407
这是第一个函数
将所有的值遍历,并放在元组中,标记1
48608
这是第二个函数
将x中的第一个值进行累加求和,第二个值加一,求得元素总个数
x:(1115030,4)
y:69003
这是第一个函数
将所有的值遍历,并放在元组中,标记1
476893
...
...
...
(d,338451)
(e,335306)
(a,336184)
(i,346279)
(b,333069)
(h,334343)
(f,341380)
(j,320145)
(g,334042)
(c,325022)
这里我们发现了,函数的顺序并不先全部执行完第一个函数,再执行第二个函数。而是分区并行,即第一个分区执行完第一个函数,并不等待其他分区执行完第一个函数,而是紧接着执行第二个函数,最后在第三个函数进行处理。在本地单机下,该并行特点并不能充分发挥,但在集群环境中,各个分区在不同节点计算,然后处理完结果汇总处理。这样,当数据量十分庞大时,集群节点数越多,该优势就表现地越明显。
此外还有一个非常值得关注的特点,当我们把foreach(println)这句话去掉时
foreach(println)
我们运行程序,发现程序没有任何输出。这是由于spark的懒加载特点,spark只用在对数据执行具体操作时,如输出、保存等才会执行计算。这看起来有点不合理,但实际上这样做在很多场景下能大幅度提升效率,但如果没有处理好,可能会导致spark每次执行操作都会从头开始计算该过程。因此当一个操作结果需要被频繁或者多次调用的时候,我们应该将结果存下来。
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("SparkCombineByKey")
sc = SparkContext(conf=conf)
sc.textFile("./grades") .map(lambda line : (line.split(" ")[0],int(line.split(" ")[1]))) .combineByKey(
lambda num:(num,1),lambda x,y:(x[0]+y,x[1]+1),lambda x,y:(x[0]+y[0],x[1]+y[1])
).map(lambda x:(x[0],x[1][0]/x[1][1])).foreach(print)
(‘b‘, 333069.8589473684)
(‘f‘, 341380.94444444444)
(‘j‘, 320145.7618069815)
(‘h‘, 334343.75)
(‘a‘, 336184.95321637427)
(‘g‘, 334042.37605042016)
(‘d‘, 338451.6)
(‘e‘, 335306.7480769231)
(‘c‘, 325022.4183673469)
sortByKey非常简单,也非常常用。这里依然采用上述文本,将处理后的结果,进行排序,得到平均值最大的字母。在实际运用中我们这里可以看成求得按照成绩排序,或者按照姓名排序。
import org.apache.spark.{SparkConf, SparkContext}
object SparkSortByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkCombineByKey")
val sc = new SparkContext(conf)
val result = sc.textFile("./grades").map(line=>{
val splits = line.split(" ")
(splits(0),splits(1).toInt)
}).combineByKey(value =>(value,1),(x:(Int,Int),y)=>(x._1+y,x._2+1),(x:(Int,Int),y:(Int,Int))=>(x._1+y._1,x._2+y._2)
).map(x=>(x._1,x._2._1/x._2._2))
//按照名字排序,顺序
result.sortByKey(true).foreach(println)
//按照名字排序,倒序
result.sortByKey(false).foreach(println)
val result1 = sc.textFile("./grades").map(line=>{
val splits = line.split(" ")
(splits(0),splits(1).toInt)
}).combineByKey(value =>(value,1),(x:(Int,Int),y)=>(x._1+y,x._2+1),(x:(Int,Int),y:(Int,Int))=>(x._1+y._1,x._2+y._2)
).map(x=>(x._2._1/x._2._2,x._1))
//按照成绩排序,顺序
result1.sortByKey(true).foreach(println)
//按照成绩排序,倒序
result1.sortByKey(false).foreach(println)
}
}
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("SparkCombineByKey")
sc = SparkContext(conf=conf)
result = sc.textFile("./grades") .map(lambda line : (line.split(" ")[0],int(line.split(" ")[1]))) .combineByKey(
lambda num:(num,1),lambda x,y:(x[0]+y,x[1]+1),lambda x,y:(x[0]+y[0],x[1]+y[1])
).map(lambda x:(x[0],x[1][0]/x[1][1]))
result.sortByKey(True).foreach(print)
result.sortByKey(False).foreach(print)
result1 = sc.textFile("./grades") .map(lambda line : (line.split(" ")[0],int(line.split(" ")[1]))) .combineByKey(
lambda num:(num,1),lambda x,y:(x[0]+y,x[1]+1),lambda x,y:(x[0]+y[0],x[1]+y[1])
).map(lambda x:(x[1][0]/x[1][1],x[0]))
result1.sortByKey(True).foreach(print)
result1.sortByKey(False).foreach(print)
(a,336184)
(b,333069)
(c,325022)
(d,338451)
(e,335306)
(f,341380)
(g,334042)
(h,334343)
(i,346279)
(j,320145)
(j,320145)
(i,346279)
(h,334343)
(g,334042)
(f,341380)
(e,335306)
(d,338451)
(c,325022)
(b,333069)
(a,336184)
(320145,j)
(325022,c)
(333069,b)
(334042,g)
(334343,h)
(335306,e)
(336184,a)
(338451,d)
(341380,f)
(346279,i)
(346279,i)
(341380,f)
(338451,d)
(336184,a)
(335306,e)
(334343,h)
(334042,g)
(333069,b)
(325022,c)
(320145,j)
数据集以及代码都可以在github上下载。
转自:https://juejin.im/post/5c7a58426fb9a049a42fc190
Spark入门(六)--Spark的combineByKey、sortBykey
标签:parse val function height 输出 空格 user lin 多次
原文地址:https://www.cnblogs.com/tjp40922/p/12181635.html