标签:save 元组 复制 set iterator tps oid lis 直接下载
在上一节Spark经典的单词统计中,了解了几个RDD操作,包括flatMap,map,reduceByKey,以及后面简化的方案,countByValue。那么这一节将介绍更多常用的RDD操作,并且为每一种RDD我们分解来看其运作的情况。
flatMap,有着一对多的表现,输入一输出多。并且会将每一个输入对应的多个输出整合成一个大的集合,当然不用担心这个集合会超出内存的范围,因为spark会自觉地将过多的内容溢写到磁盘。当然如果对运行的机器的内存有着足够的信心,也可以将内容存储到内存中。
为了更好地理解flatMap,我们将举一个例子来说明。当然和往常一样,会准备好例子对应的数据文本,文本名称为uv.txt,该文本和示例程序可以从github上下载。以下会用三种语言:scala、java、python去描述,同时在java中会对比采用java和java8来实现各个例子。其中java和scala程序在github能直接下载,而python则暂时不提供,后续会补上。
import org.apache.spark.{SparkConf, SparkContext}
object SparkFlatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkFlatMap")
val sc = new SparkContext(conf)
//设置数据路径
val textData = sc.textFile("./uv.txt")
//输出处理前总行数
println("before:"+textData.count()+"行")
//输出处理前第一行数据
println("first line:"+textData.first())
//进行flatMap处理
val flatData = textData.flatMap(line => line.split(" "))
//输出处理后总行数
println("after:"+flatData.count())
//输出处理后第一行数据
println("first line:"+flatData.first())
//将结果保存在flatResultScala文件夹中
flatData.saveAsTextFile("./flatResultScala")
}
}
复制代码import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.Arrays;
import java.util.Iterator;
public class SparkFlatMapJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//java实现
flatMapJava(sc);
//java8实现
flatMapJava8(sc);
}
public static void flatMapJava(JavaSparkContext sc){
//设置数据路径
JavaRDD<String> textData = sc.textFile("./uv.txt");
//输出处理前总行数
System.out.println("before:"+textData.count()+"行");
//输出处理前第一行数据
System.out.println("first line:"+textData.first()+"行");
//进行flatMap处理
JavaRDD<String> flatData = textData.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//输出处理后总行数
System.out.println("after:"+flatData.count()+"行");
//输出处理后第一行数据
System.out.println("first line:"+flatData.first()+"行");
//将结果保存在flatResultScala文件夹中
flatData.saveAsTextFile("./flatResultJava");
}
public static void flatMapJava8(JavaSparkContext sc){
sc.textFile("./uv.txt")
.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.saveAsTextFile("./flatResultJava8");
}
}
复制代码from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("FlatMapPython")
sc = SparkContext(conf=conf)
textData = sc.textFile("./uv.txt")
print("before:"+str(textData.count())+"行")
print("first line"+textData.first())
flatData = textData.flatMap(lambda line:line.split(" "))
print("after:"+str(flatData.count())+"行")
print("first line"+flatData.first())
flatData.saveAsTextFile("./resultFlatMap")
复制代码运行任意程序,得到相同结果
before:86400行
first line:2015-08-24_00:00:00 55311 buy
after:259200
first line:2015-08-24_00:00:00
复制代码查看文件
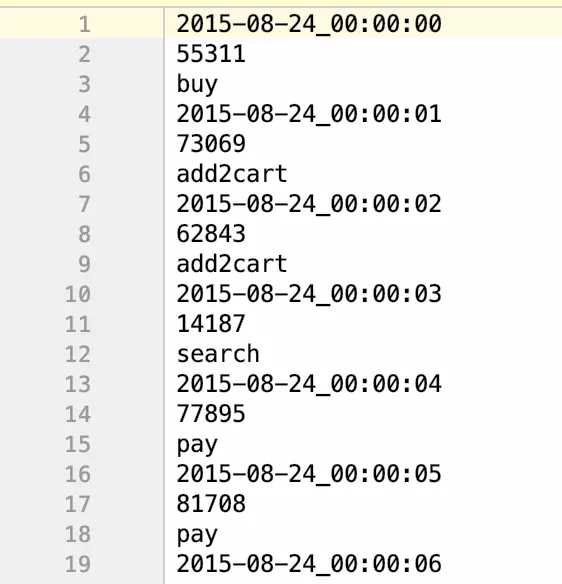
很显然每一行都按照空格拆分成了三行,因此总行数是拆分前的三倍,第一行的内容只剩下原第一行的第一个数据,时间。这样flatMap的作用就很明显了。
用同样的方法来展示map操作,与flatMap不同的是,map通常是一对一,即输入一个,对应输出一个。但是输出的结果可以是一个元组,一个元组则可能包含多个数据,但是一个元组是一个整体,因此算是一个元素。这里注意到在输出的结果是元组时,scala和python能够很正常处理,而在java中则有一点不同。
import org.apache.spark.{SparkConf, SparkContext}
object SparkMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkFlatMap")
val sc = new SparkContext(conf)
val textData = sc.textFile("./uv.txt")
//得到一个最后一个操作值,前面的时间和次数舍弃
val mapData1 = textData.map(line => line.split(" ")(2))
println(mapData1.count())
println(mapData1.first())
mapData1.saveAsTextFile("./resultMapScala")
//得到一个最后两个值,前面的时间舍弃
val mapData2 = textData.map(line => (line.split(" ")(1),line.split(" ")(2)))
println(mapData2.count())
println(mapData2.first())
//将所有值存到元组中去
val mapData3 = textData.map(line => (line.split(" ")(1),line.split(" ")(1),line.split(" ")(2)))
println(mapData3.count())
println(mapData3.first())
}
}
复制代码import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.codehaus.janino.Java;
import scala.Tuple2;
import scala.Tuple3;
public class SparkMapJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//java实现
mapJava(sc);
//java8实现
mapJava8(sc);
}
public static void mapJava(JavaSparkContext sc){
JavaRDD<String> txtData = sc.textFile("./uv.txt");
//保留最后一个值
JavaRDD<String> mapData1 = txtData.map(new Function<String, String>() {
@Override
public String call(String s) throws Exception {
return s.split(" ")[2];
}
});
System.out.println(mapData1.count());
System.out.println(mapData1.first());
//保留最后两个值
JavaRDD<Tuple2<String,String>> mapData2 = txtData.map(new Function<String, Tuple2<String,String>>() {
@Override
public Tuple2<String,String> call(String s) throws Exception {
return new Tuple2<>(s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(mapData2.count());
System.out.println(mapData2.first());
//保留最后三个值
JavaRDD<Tuple3<String,String,String>> mapData3 = txtData.map(new Function<String, Tuple3<String,String,String>>() {
@Override
public Tuple3<String,String,String> call(String s) throws Exception {
return new Tuple3<>(s.split(" ")[0],s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(mapData2.count());
System.out.println(mapData2.first());
}
public static void mapJava8(JavaSparkContext sc){
JavaRDD<String> mapData1 = sc.textFile("./uv.txt").map(line -> line.split(" ")[2]);
System.out.println(mapData1.count());
System.out.println(mapData1.first());
JavaRDD<Tuple2<String,String>> mapData2 = sc.textFile("./uv.txt").map(line -> new Tuple2<String, String>(line.split(" ")[1],line.split(" ")[2]));
System.out.println(mapData2.count());
System.out.println(mapData2.first());
JavaRDD<Tuple3<String,String,String>> mapData3 = sc.textFile("./uv.txt").map(line -> new Tuple3<String, String, String>(line.split(" ")[0],line.split(" ")[1],line.split(" ")[2]));
System.out.println(mapData3.count());
System.out.println(mapData3.first());
}
}
复制代码from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("FlatMapPython")
sc = SparkContext(conf=conf)
textData = sc.textFile("./uv.txt")
mapData1 = textData.map(lambda line : line.split(" ")[2])
print(mapData1.count())
print(mapData1.first())
mapData2 = textData.map(lambda line : (line.split(" ")[1],line.split(" ")[2]))
print(mapData2.count())
print(mapData2.first())
mapData3 = textData.map(lambda line : (line.split(" ")[0],line.split(" ")[1],line.split(" ")[2]))
print(mapData3.count())
print(mapData3.first())
复制代码运行任意程序,得到相同结果
86400
buy
86400
(55311,buy)
86400
(55311,55311,buy)
复制代码import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class SparkMapToPair {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkFlatMapJava");
JavaSparkContext sc = new JavaSparkContext(conf);
mapToPairJava(sc);
mapToPairJava8(sc);
}
public static void mapToPairJava(JavaSparkContext sc){
JavaPairRDD<String,String> pairRDD = sc.textFile("./uv.txt").mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<>(s.split(" ")[1],s.split(" ")[2]);
}
});
System.out.println(pairRDD.count());
System.out.println(pairRDD.first());
}
public static void mapToPairJava8(JavaSparkContext sc){
JavaPairRDD<String,String> pairRDD = sc.textFile("./uv.txt").mapToPair(line -> new Tuple2<>(line.split(" ")[1],line.split(" ")[2]));
System.out.println(pairRDD.count());
System.out.println(pairRDD.first());
}
}
复制代码运行得到结果
86400
(55311,buy)
复制代码显然我们发现这个结果,和用map处理保留后两个的结果是一致的。灵活使用map、flatMap、mapToPair将非常重要,后面还将有运用多种操作去处理复杂的数据。以上所有程序的代码都能够在GitHub上下载
转自:https://juejin.im/post/5c77e383f265da2d8f474e29
Spark入门(四)--Spark的map、flatMap、mapToPair
标签:save 元组 复制 set iterator tps oid lis 直接下载
原文地址:https://www.cnblogs.com/tjp40922/p/12181626.html