标签:val 方式 通过 style 工作 png 指定 操作 数组
pandas 含有使数据分析工作变得更快更简单的高级数据结构和操作工具。pandas 是基于Numpy 构建的。
导入pandas包:
from pandas import Series , DataFrame
import pandas as pd
包括两个主要的数据结构:Series 和DataFrame.
1.1 Series
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series:
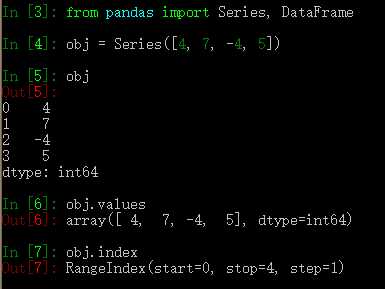
Series 的字符串形式表现为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0 到N-1 (N为数据的长度)的整数型索引。可以通过Series 的values 和index 属性获取其数组表示形式和索引对象。
我们也可以创建一个可以对各个数据点进行标记的索引:
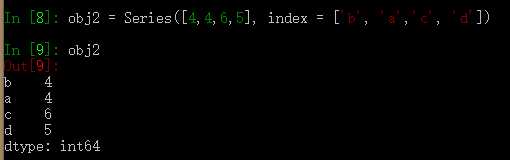
如果数据被存放在一个python字典中,也可以直接通过这个字典来创建Series:
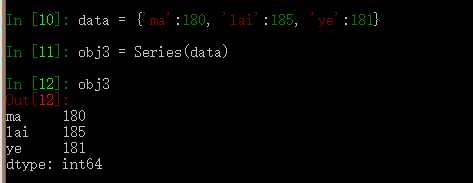
如果Series中的values值缺失,索引对应的位置就会显示NaN(即“非数字”not a number).
在pandas中,它用于表示缺失或者NA值。pandas的isnull 和notnull 函数可用于检测缺失数据。
1.2 DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,他可以被看做由Series 组成的字典(共同用一个索引)。
1.2.1 构建DataFrame
方法一:
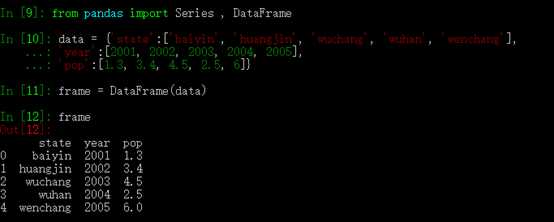
直接传入一个由等长列表或者Numpy 数组组成的字典:
data = {‘state’:[‘0hio’, ‘0hio’, ‘Nevada’, ‘Lai’, ‘ lao’],
‘year’:[2000, 2001, 2002, 2003, 2004],
‘pop’:[1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data)
如下:结果DataFrame 会自动加上索引,且全部列会被有序排列:
我们也可以指定列序列:
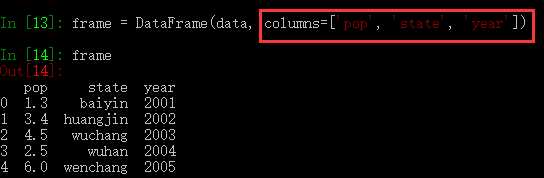
跟Series一样,如果传入的列的在数据中找不到,就会产生NA值:

通过类似字典标记的方式或者属性的方式,可以将DataFrame的列获取为一个Series:
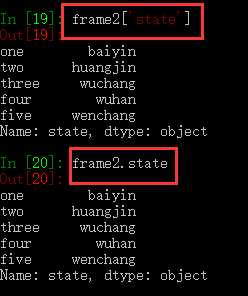
返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应的设置好了。
行也可以通过位置或名称的方式进行获取,比如用索引字段 ix:
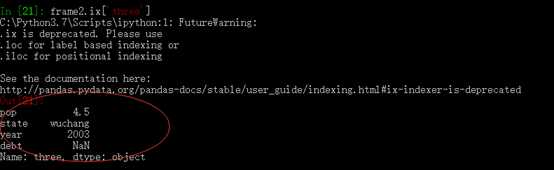
1.2.2 索引对象
pandas 的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series和DataFrame 时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
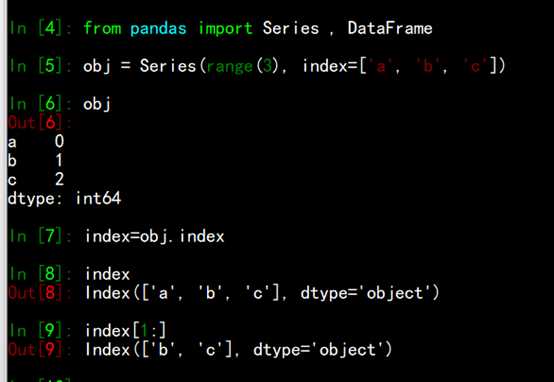
注:index对象是不可修改的(immutable)。用户不能对其进行修改,这样才能使Index对象在多个数据结构之间安全共享。
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。

1.2.3 基本功能
pandas对象的一个重要方法是reindex,作用是创建一个适应新索引的新对象。
drop方法:
dropna 方法:
fillna 方法
标签:val 方式 通过 style 工作 png 指定 操作 数组
原文地址:https://www.cnblogs.com/bltstop/p/12182053.html