标签:代码 端口号 before 不同 远程服务器 next bind failure 默认
、主从复制高可用
#主从复制存在的问题: 1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master 2 主从复制,只能主写数据,所以写能力和存储能力有限
哨兵是对Redis的系统的运行情况的监控,它是一个独立进程,它会独立运行,功能有二个:
通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
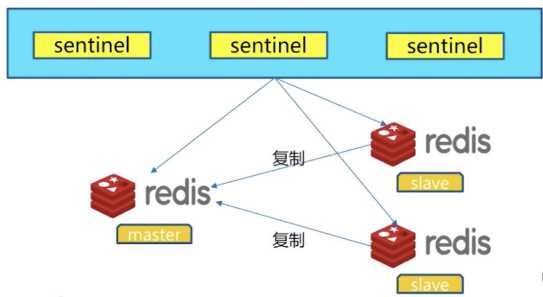
二、架构说明
可以做故障判断,故障转移,通知客户端(其实是一个进程),客户端直接连接sentinel的地址
流程
1 多个sentinel发现并确认master有问题 2 选举触一个sentinel作为领导 3 选取一个slave作为新的master 4 通知其余slave成为新的master的slave 5 通知客户端主从变化 6 等待老的master复活成为新master的slave
三、配置哨兵
一般配置多个哨兵,除了监控各个redis服务器之外,哨兵之间也会互相监控。
1.环境配置
| 主机服务 | 主机IP | 端口 | sentinel端口 |
| master(主库) |
127.0.0.1
|
6379 |
26379 |
| slave (从库) | 127.0.0.1 | 6380 | 26380 |
| slave (从库) |
127.0.0.1 |
6381
|
26381 |
redis默认的sentinel.conf文件

2.创建自定义sentinel文件
进入服务器的redis文件夹下,创建redis6379_sentinel.conf配置
port 26379 #此端口号是该哨兵文件的端口号,每个哨兵文件的端口号不同 daemonize no dir /root/data protected-mode no bind 0.0.0.0 logfile "redis6379_sentinel.log"
#sentinel monitor代表监控,mymaster是给主库取得别名,ip地址代表监控的主库,6379是主库的端口号,2代表有两个或者两个以上的哨兵认为主库不可用时,才会进行换库 sentinel monitor mymaster 127.0.0.1 6379 2
#此配置指需要多少时间,一个master才会被sentinel主观认定是不可用的,单位是毫秒,默认是30秒 sentinel down-after-milliseconds mymaster 30000
#此配置值在发生故障时,最多可以有几个slave同时对新的master进行同步,这个数字越小完成故障处理的时间越短 sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
#failover-timeout可以用在以下这些方面
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。 #2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 #3.当想要取消一个正在进行的failover所需要的时间。 #4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
需要三个哨兵,所以创建三个sentinel.conf

redis6380_sentinel.conf
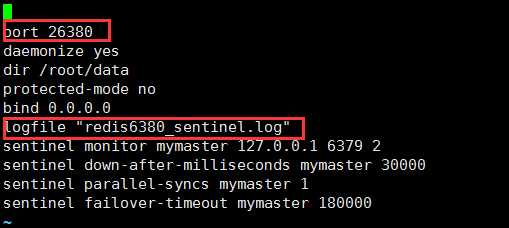
注意:需要将端口号改为26380(******)
同理,再复制出一份redis6381_sentinel.conf,这样就完成了三个哨兵的配置
四、启动哨兵
1.首先需要先把redis的主从服务器启动:redis-server redis.conf

2.然后启动3个哨兵:redis-sentinel sentinel.conf
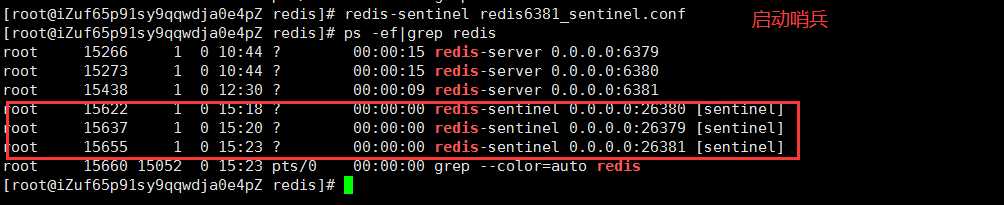
3.查看sentinel信息
启动之后可以看到redis6381_sentinel.conf配置有一些添加的内容
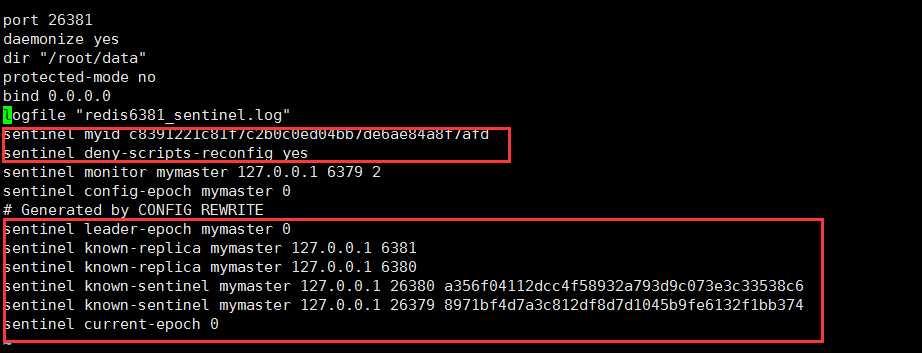
如果发生了故障,sentinel的配置文件会自动进行相应的更改。
客户端连接:redis-cli -p 26379,再输入info查看到的部分信息
# Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0
#主节点是mymaster,ip和端口是127.0.0.1和6379,有2个从节点,4个哨兵 master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=4
这样就是配置成功了
五、python中使用哨兵模式
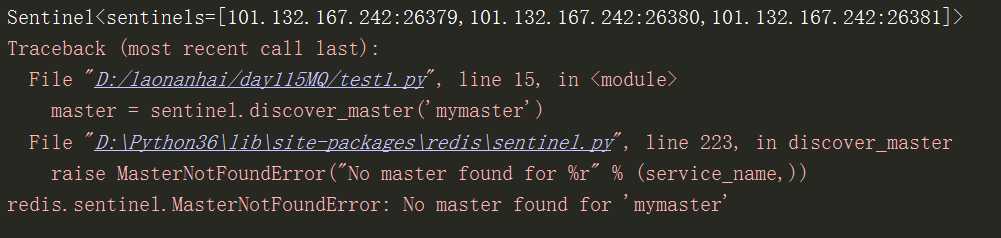
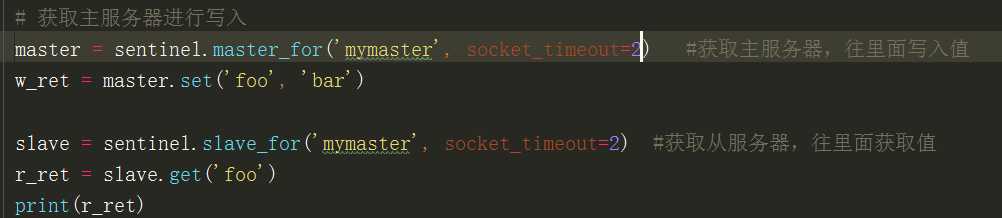
import redis from redis.sentinel import Sentinel # 连接哨兵服务器(主机名也可以用域名) # 101.132.167.242是远程服务器的ip地址 sentinel = Sentinel([(‘101.132.167.242‘, 26379), (‘101.132.167.242‘, 26380), (‘101.132.167.242‘, 26381) ], socket_timeout=5) print(sentinel) #Sentinel<sentinels=[101.132.167.242:26379,101.132.167.242:26380,101.132.167.242:26381]> # 获取主服务器地址 master = sentinel.discover_master(‘mymaster‘) print(master) #(‘127.0.0.1‘, 6379) # 获取从服务器地址 slave = sentinel.discover_slaves(‘mymaster‘) print(slave) #[(‘127.0.0.1‘, 6380), (‘127.0.0.1‘, 6381)] # 获取主服务器进行写入 master = sentinel.master_for(‘mymaster‘, socket_timeout=0.5) #获取主服务器,往里面写入值 w_ret = master.set(‘foo‘, ‘bar‘) slave = sentinel.slave_for(‘mymaster‘, socket_timeout=0.5) #获取从服务器,往里面获取值 r_ret = slave.get(‘foo‘) print(r_ret)
出现这种错误,可能是阿里云没设置哨兵端口号
在阿里云中设置哨兵端口号

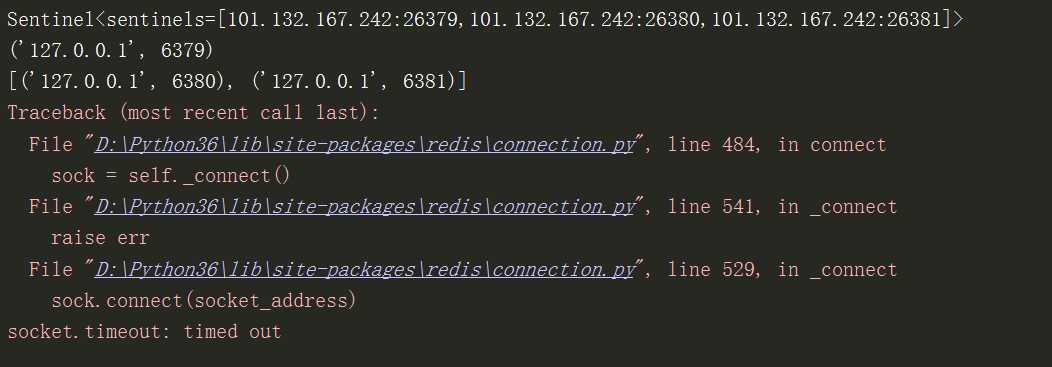
出现time out报错可能是因为代码中timeout时间设置太短了
时间设置长一点就行
六、主服务故障转移
1.先关闭主服务器redis,过一会查看一下sentinel日志。
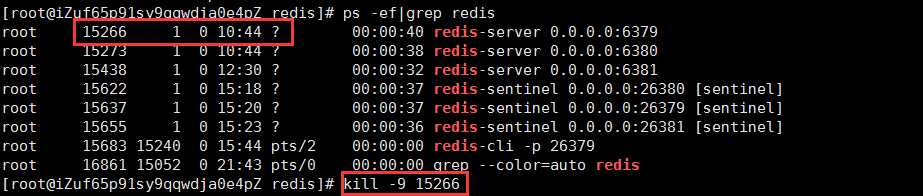
2.查看26379 sentinel文件

15637:X 12 Jan 2020 21:44:38.983 # +sdown master mymaster 127.0.0.1 6379 #发现master服务已经不能用 15637:X 12 Jan 2020 21:44:39.063 # +new-epoch 1 15637:X 12 Jan 2020 21:44:39.065 # +vote-for-leader c8391221c81f7c2b0c0ed04bb7de6ae84a8f7afd 1 #投票选举哪个哨兵当leader 15637:X 12 Jan 2020 21:44:39.066 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2 #3个哨兵有2哨兵投票不能使用了 15637:X 12 Jan 2020 21:44:39.066 # Next failover delay: I will not start a failover before Sun Jan 12 21:50:40 2020 15637:X 12 Jan 2020 21:44:40.066 # +config-update-from sentinel c8391221c81f7c2b0c0ed04bb7de6ae84a8f7afd 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
#26381哨兵当leader修改配置,6381升级为master 15637:X 12 Jan 2020 21:44:40.066 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 #主数据库从6379转变为6381 15637:X 12 Jan 2020 21:44:40.066 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 #添加6380为6381的从库 15637:X 12 Jan 2020 21:44:40.066 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 #添加6379为6381的从库 15637:X 12 Jan 2020 21:45:10.088 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 #发现6379已经宕机,等待6379的恢复
3.客户端连接查看主服务器转移
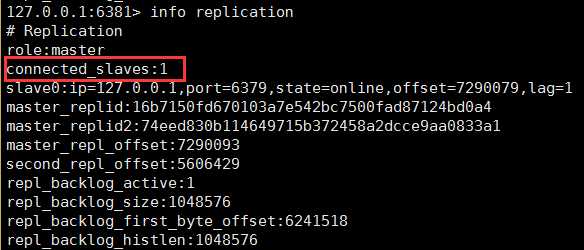
客户端连接6381,输入info replication
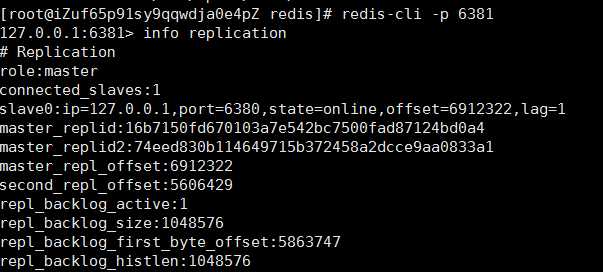
可以看出,6381目前是master,拥有一个slave,slave是6380
客户端连接6380,输入info replication
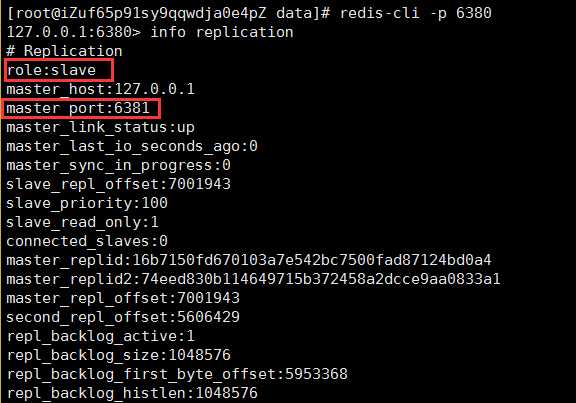
可以看出6380是slave,master是6381
4.重新启动6379查看状态
启动6379:

客户端连接6381查看状态:
已经将6379设置为6381的slave
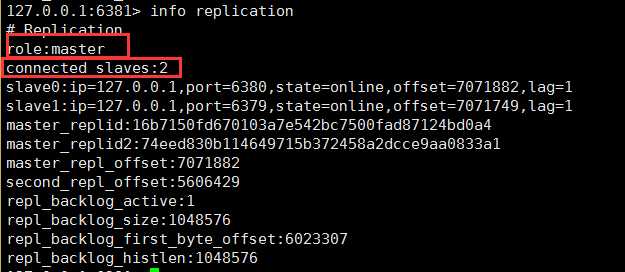
查看6379 sentine.log文件

15637:X 12 Jan 2020 23:47:40.287 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 #6379已经恢复服务 15637:X 12 Jan 2020 23:47:50.234 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 #将6379设置为6381的slave
七、从服务故障转移
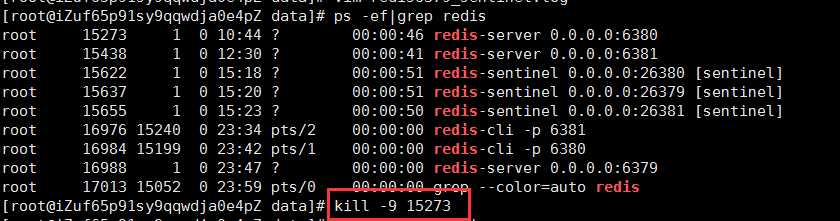
关闭6380从服务
查看6380 sentinel.log文件

说明已经监控到6380slave宕机了,那么如果恢复6380端口服务,会自动加入到主从复制吗?
从6381的客户端也可以查出6380宕机了,slave数量变为1
重新启动6380从服务,查看6380 sentinel.log文件

可以看出6380slave新加入了主从复制中,-sdown:说明是恢复服务
Redis(六)——高可用之哨兵sentinel配置与启动及主从服务宕机与恢复
标签:代码 端口号 before 不同 远程服务器 next bind failure 默认
原文地址:https://www.cnblogs.com/wangcuican/p/12185385.html