标签:循环引用 scan ica 作用域 完整 angular 打包 手动 微软
TypeScript 由微软在 2012 年 10 月首发,经过几年的发展,已经成为国内外很多前端团队的首选编程语言。前端三大框架中的 Angular 和 Vue 3 也都改用了 TypeScript 开发。即使很多人没直接用过 TypeScript,他们也在通过 VSCode 提供的智能提示功能间接享受着 TypeScript 带来的各项便利。
很多人对 TypeScript 背后的原理很感兴趣,你可能想要:
但你上网搜索,你会发现能搜到的全是 TypeScript 如何使用的教程,即使是英文的资料,也鲜有能完全讲解清楚 TypeScript 内部原理的文章。
只有少数的几篇教程会在文末稍微附带一下原理说明,但它们只是大概阐述了一下 TypeScript 的整体架构,最核心的类型分析的具体实现几乎都是一句带过。
能真正了解 TypeScript 内部原理的人极少,多数人对 TypeScript 的想法是:“这方面的东西和我工作没啥关系,我只管能用就行!”(其实内心的想法是:这东西好烦啊!为什么大家都在用?求你别加功能了,学不动了……)
既然你读到这里了,说明你真的想学习 TypeScript 的内部原理。这篇系列文章不教你如何使用 TypeScript(那种你网上随便一搜,很多),我假设你已经熟悉了 TypeScript 的各种语法,文中不会介绍这些语法的功能,也不探讨这些语法的好坏,只重点介绍 TypeScript 是如何实现这个语法的功能的。这篇系列文章可以帮助你在没学过编译原理之类的书的前提下,真正地学会编译相关的知识。但你必须先做好两点准备:1. 检查这个页面的网址,这篇系列文章由徐林迪(xuld)原创,前三篇在博客园首发,禁随意转载、偷爬,如果需要引用文章内容,请直接链接到这篇文章的地址,不要复制内容。2. TypeScript 核心编译器截止目前一共有 8 万行以上代码,GIT 源码仓库 超过 1 G,学习 TypeScript 原理是一个漫长的过程,不是几天就可以搞定的,你需要静下心来,而且原理中包含了大量抽象的逻辑,如果你不打算用太久时间,请尽早放弃。
如果有天你问一个“高手”,TypeScript 是怎么写的,“高手”就回复你一句“你去看编译原理的书,比如某某动物书”,那我可以很肯定地告诉你,你的那位“高手”也不懂 TypeScript 的原理。要实现一个 TypeScript ,确实需要一些编译原理的知识,但并不多,TypeScript 的核心是类型分析、流程分析、ES5 语法转换,而这些东西,在传统的 C 编译器之类的领域都是不存在的。所以你去读那些教你怎么写 parser,怎么编译成机器码的传统编译原理的书,是远远不够的。
TypeScript 的核心设计者之一也是 C#(念 C 井的请注意了——你的英文能力可能会增加你学习 TypeScript 原理的困难度),Pascal 的核心设计者,TypeScript 有很多地方都借鉴了 C# 的实现,也逐渐给 JavaScript 增加了以前只有 C# 才有的功能。
TypeScript 在微软拥抱开源的大政策下,和社区有良好的互动,我曾经给 TypeScript 提过三个 BUG,TypeScript 团队都能在当天回复,并且在下一个版本中立即修复了。
TypeScript 的目标是:
静态分析代码是 TypeScript 的主要职责,通过静态分析,我们可以得到这些功能:
但对于动态脚本语言来说,静态分析是无法做到 100% 准确的,TypeScript 的策略是平衡正确性和实用性。TypeScript 不会确保每处静态分析的结果都是正确的,而是多数情况都是正确的,但他们也提供了两个应对少数情况的解决方案:1. 提供语法允许用户手动修复静态分析的结果(比如用你熟悉的 any)2. 即使源码中存在错误,也可以正常编译。从使用者的角度,只要你不是故意找茬,一般也不会碰到问题。关于正确性和实用性的平衡,你在读后续教程时将会有更深的体会。
TypeScript 的项目结构如下:
├── bin 最终给用户用的 tsc 和 tsserver 命令 ├── doc 语言规范文档 ├── lib 系统标准库 ├── loc 错误文案翻译 ├── scripts 开发项目时的一些工具脚本 ├── src 源码 │ ├── compiler 编译器源码 │ └── services 语言服务,主要为 VSCode 使用,比如查找定义之类的功能 └── tests 测试文件
TypeScript 编译器的核心代码在 src/compiler,其中以下文件是研究的重点(已经按阅读顺序排序):
├── core.ts ├── sys.ts ├── types.ts ├── scanner.ts ├── parser.ts ├── utilities.ts ├── utilitiesPublic.ts ├── binder.ts ├── checker.ts ├── transformer.ts ├── transformers/ ├── emitter.ts └── program.ts
核心部分的架构如图:

TypeScript 编译器的目标是把 TypeScript 编译成 JavaScript,这其实和把“英文”翻译成“中文”没有任何区别。
当我们在翻译一段英文到中文时,要做这些事情:
说的再具体一些,是这样的流程:
所以编译器也在做同样的事情,只不过每个步骤我们都给他一个专业的称呼。
比如句子“我在2009首次创办个人网站”中的个,我们在理解时,会自然地将“个人”连在一起,而不是将“办个”连在一起。这就是一个组词的过程。这个句子组词后的结果如图:

TypeScript 是英文编程语言,编译器的组词流程,即将字母拼成单词:
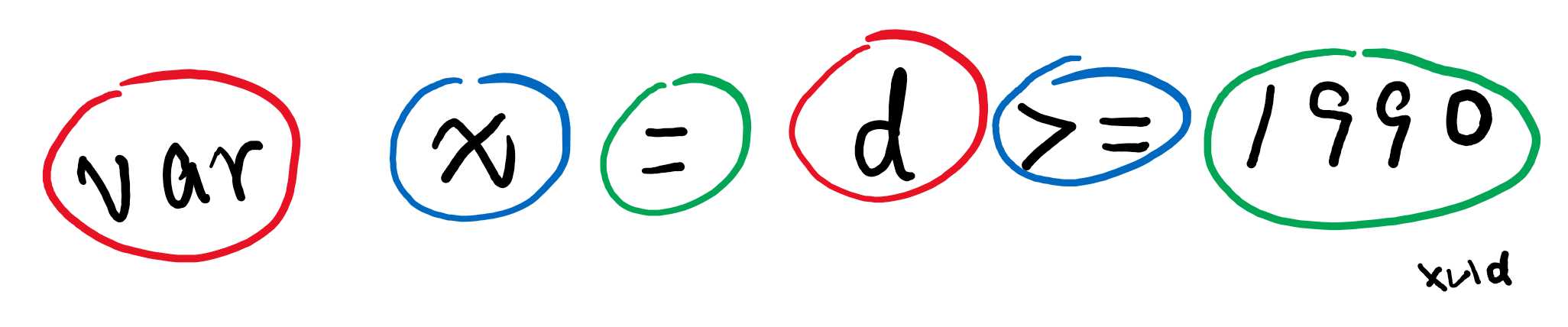
这个过程中,还会跳过代码中的注释、空格,拆出来的词有关键字、有变量名、有数字、也有符号,这些我们统称为标记(Token)。
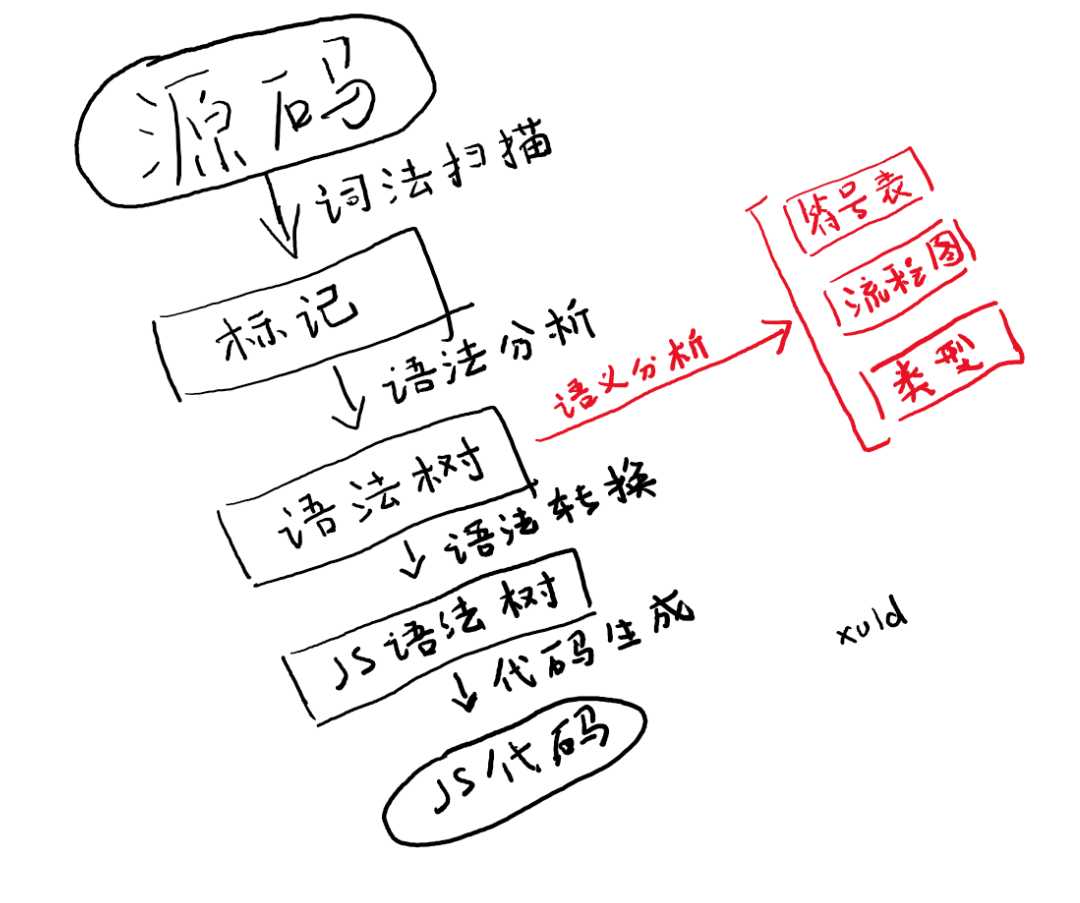
解析标记列表的过程称为词法分析,也叫词法扫描,TypeScript 源码中 scanner.ts 负责完成词法扫描。
比如句子“我在2009首次创办个人网站”,在词数有限时怎么说和原文意义最接近?结果是——“我创办网站”。你会发现,“在2009”、“首次”是用于修饰“创办”的,“个人”是用于修饰“网站”的,一个句子里面,总是先由一些词构成句子的基本结构,然后再添加其它词使得句子变得更丰富起来,每个词有不同的重要等级。“我”,“创办”,“网站”是一级词,“在2009”、“首次”和“个人”是修饰用的二级词。
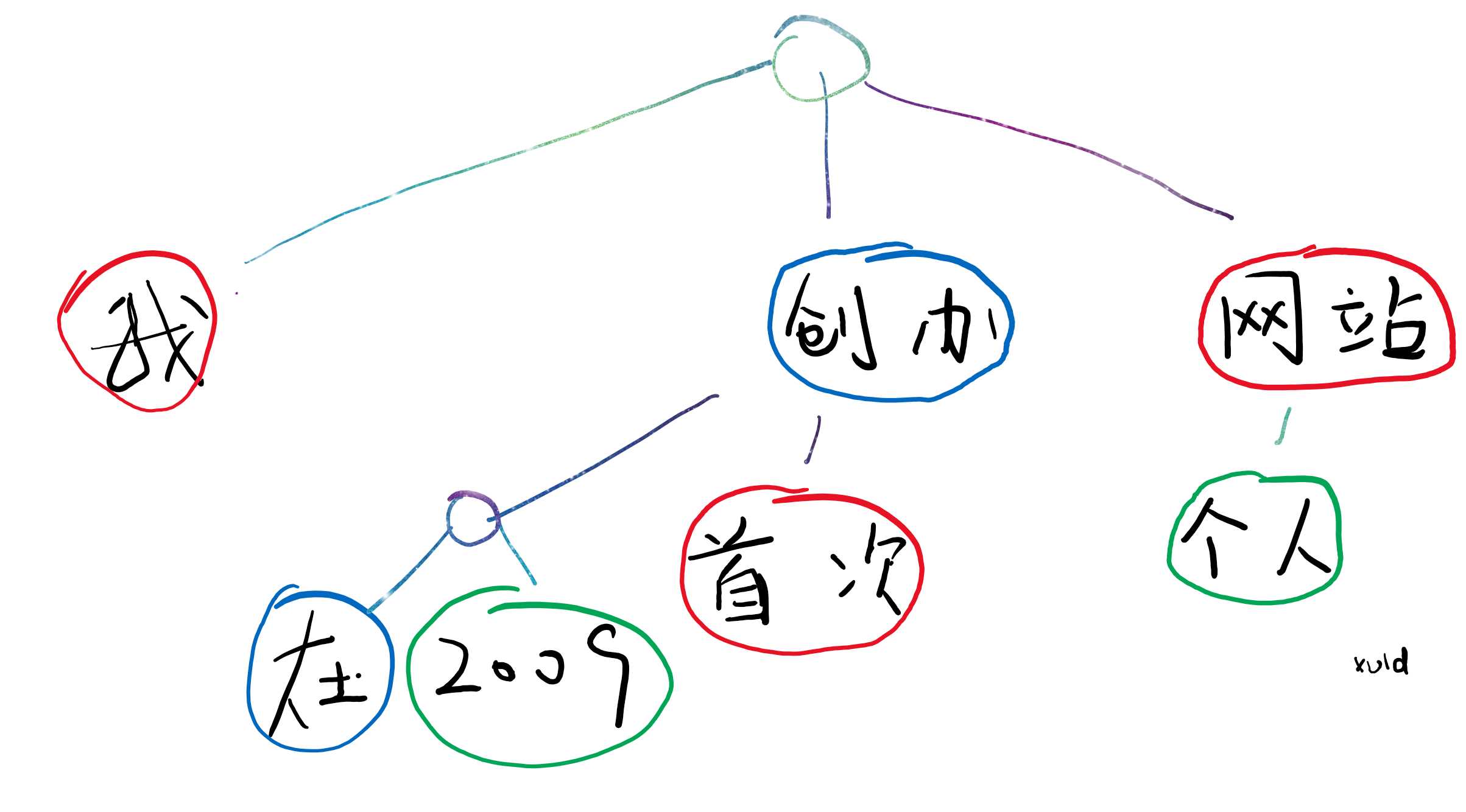
如上图,一个句子是由有上下级关系的词组成的一个树结构。什么是树结构?树结构就是指先有一个根节点,然后这个节点下面有很多子节点,每个子节点下面又有很多其它子节点(就像中国有很多省,每个省下面有很多市,市下面有你的村)。
在编译器中,将最后语法解析得到的结果称为语法树,TypeScript 源码中 parser.ts 负责解析语法生成语法树。
语法树的根节点代表一份源码文件,根节点下面有很多语句,语句即代码中需要用分号隔开的部分(一般一行一个语句),每个语句下面可能还嵌套了别的语句(比如一个函数,内部包含别的语句)。
如果你之前完全没学过编译原理,你可能对语法树还不能很好的理解,没关系,等到第4节的时候,我会更详细地介绍。
如果你之前有学过编译原理相关的东西,你会觉得上面这些讲的太简单了,那准备好了,接下来的内容,是你在其它地方很难学到的东西。
比如句子“我在2009首次创办个人网站,这个网站到现在都还在维护”,其中的“这个”是一个代词,指代前面出现过的词。平时我们也经常使用代词,甚至有的时候连代词都省略了(比如你的女朋友一开始会跟你说“你滚!”,后来,变成了“滚!”)。在谈话中我们需要记住一些概念的定义,才能理解后续的代词的含义(比如你先得记住前半句提到的个人网站,然后才能理解后面的“这个网站”的含义)。
在代码中,变量是非常常见的,一个变量名称可能指代了一个值、一个函数,或者一个类,这些统称为符号(Symbol)。
当用户定义一个变量、函数或类时,就同时定义了一个符号。编译器会先将所有的符号收集起来,建立符号表。当在其他地方使用一个名称时,就查表找出这个名称所代表的符号。
在同一个函数中,不能定义两个同名的变量,但可以定义一个变量和上层的变量重名。函数有一个符号表,其外层也有一个符号表,两个符号表是上下级关系。在函数内部使用一个名称,会先在函数对应的符号表搜索,如果找不到再在外层的符号表继续搜索,如果都找不到就报告:“变量未定义”。
拥有符号表的区域成为词法作用域(Lexical Scope),比如一个源文件、一个函数、一个语句块({})都是一个作用域。在同一个作用域中,不允许有同名的符号,但两个作用域可以存在同名的符号。

TypeScript 源码中 binder.ts 负责解析作用域,创建符号表。
在代码 fn() + gn() 对应的语法树中,fn() 和 gn() 是相邻的两个节点,在执行的时候,它们是有先后顺序的,按每行代码的执行顺序,可以绘制出一份执行流程图。为什么称为流程图而不是流程树?因为习惯上就这么叫——如果回答真这么简单,那你高考咋不考个满分?图——是数学中的专业术语,图和树类似,都是由多个节点及它们之间的关系组成的结构,树结构是一级一级层层向下的,两个节点之间的上下级关系是明确的。如果存在两个节点存在互为上下级关系(即循环引用),那就变成了图。
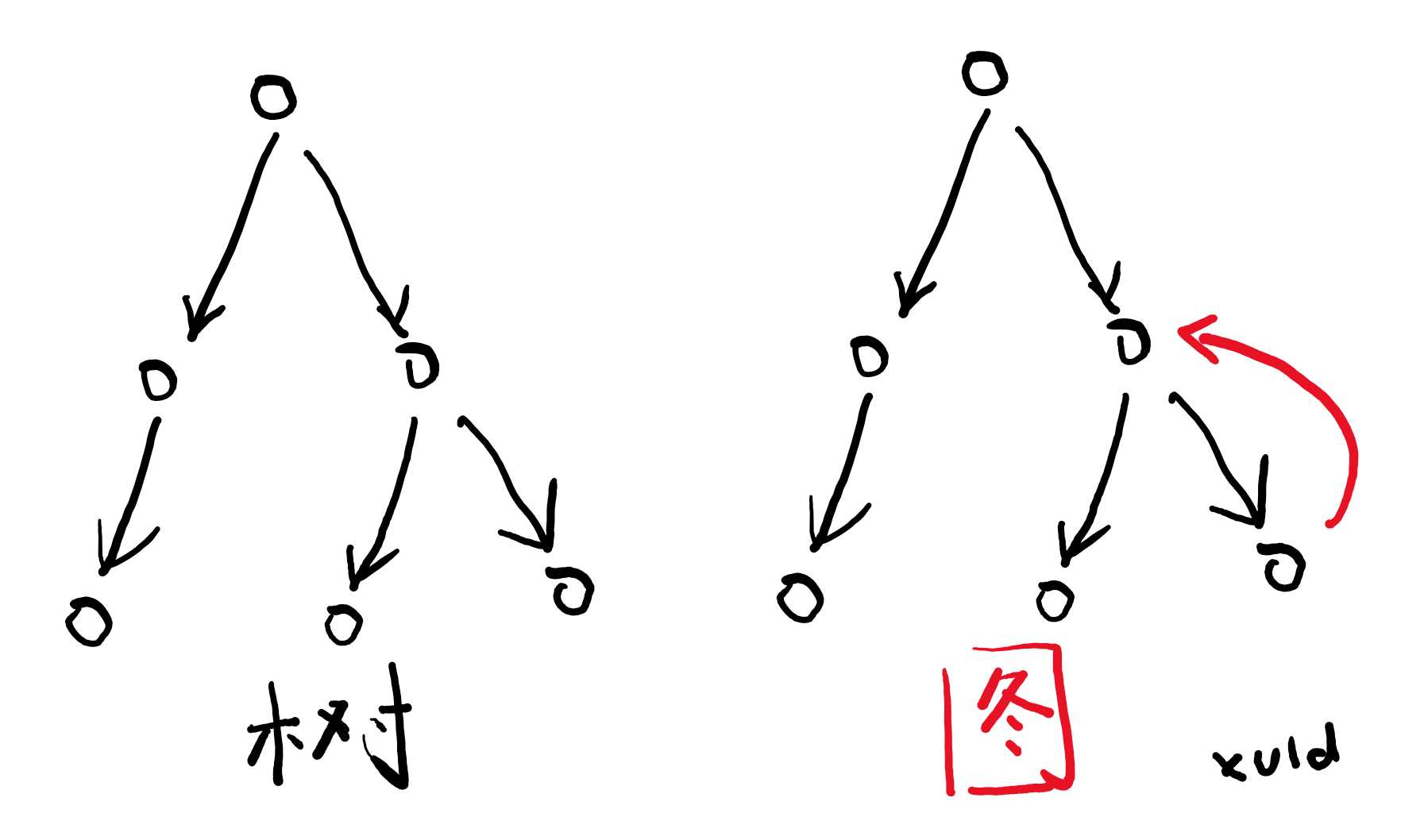
代码中存在循环,在执行的时候,可能存在回到之前执行过的节点的情况,所以称为流程图。
分析流程图有什么用?

其中实现的功能我想大家都应该都能理解,这里你可能会很好奇流程分析是怎么做到的,这会在后续章节解释。
TypeScript 源码中 binder.ts 也负责分析流程,创建流程图。
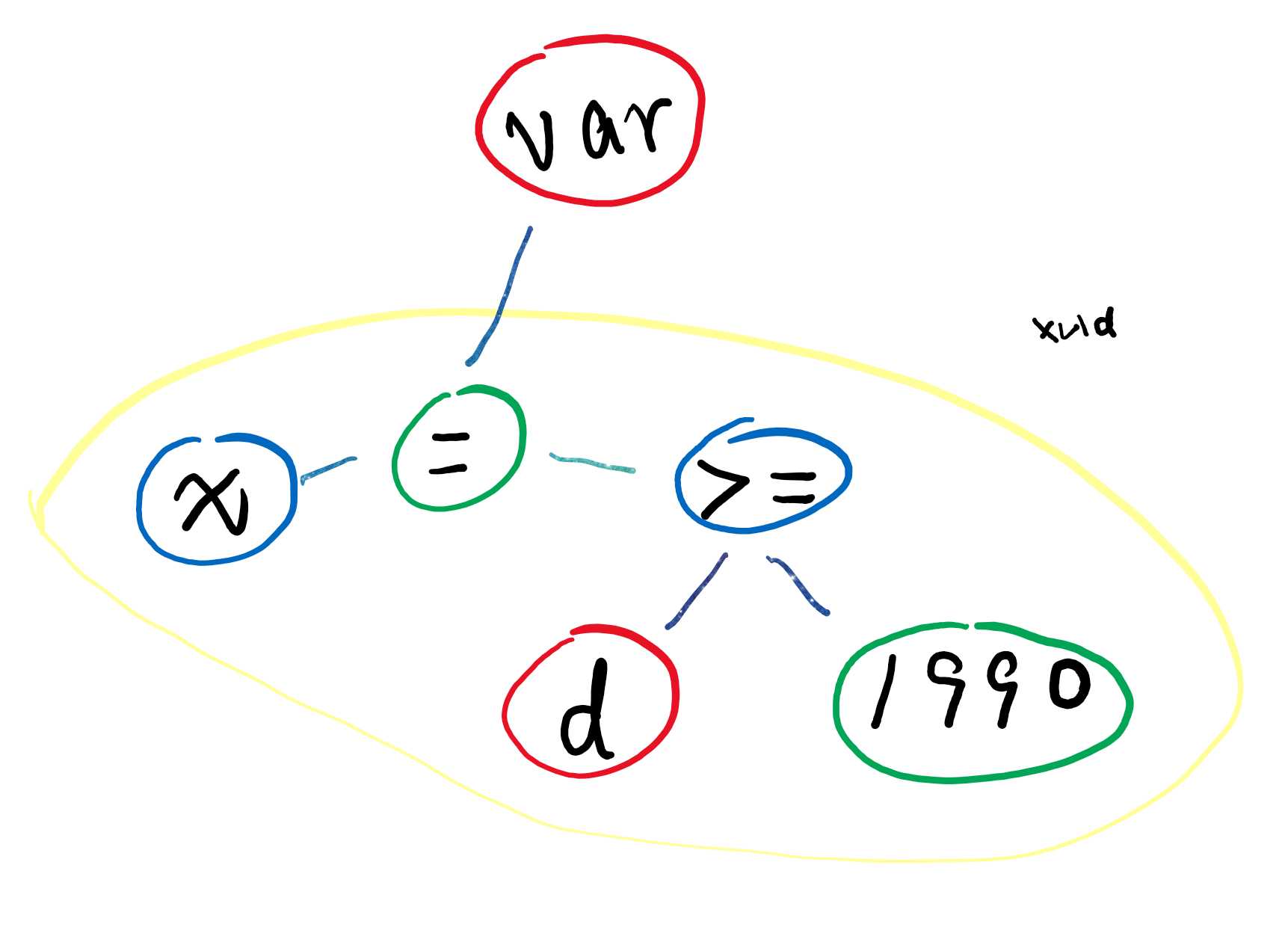
比如句子“我是你爹”,从语法上是没有错的,它确实表达出了一个意思,但这个意思你可能认为是不对的,这就叫语义错误。
比如 var x = null; x.toString(); 从语法上是正确的代码,可以执行,但执行的时候会发现 x 是空,然后就报错了。
语义分析的目的就是在不执行代码的前提下找出可能在执行过程中出错的代码。
你可能会想,为什么不直接执行代码,执行一下代码错误不就出来了吗?假如你正在哈皮地码代码的时候,还没等你测试,它就已经开始工作——并且删除了你珍藏多年的电影——你会不会奔溃?因为 VSCode 需要有实时分析错误的功能,它为了分析错误,把你写到一半的代码直接拿来执行了……
语义分析的错误种类很多,比如:
TypeScript 源码中 checker.ts 负责语义分析。checker.ts 的行数超过 3 万,也将是本篇系列文章中重点研究的对象。
TypeScript 提供了编译成 JavaScript 的功能,而且可以编译成 ES3、ES5、ES2020 等不同版本的代码。
要实现这个功能,就必须先将 TypeScript 代码翻译为 ESNext 的语法(即删除所有类型信息),如果用户需要的是旧版本的语法,再将 ESNext 中旧不版本不支持的语法替换掉。
每次转换都是通过一个转换器(Transformer)实现的,转换器的输入是语法树,输出是新的语法树。每个转换器就像工厂里的一道加工流程,原料在流水线被不断加工并最后包装成产品。输入的原始的 TypeScript 语法树也会被不同的转换器处理,最后得到标准的 JavaScript 语法树。
TypeScript 内置了 TS→ESNext、ES7→ES6、ES6→ES5、ES5→ES3 等转换器,用户也可以开发自己的转换器,生成更实用的代码。
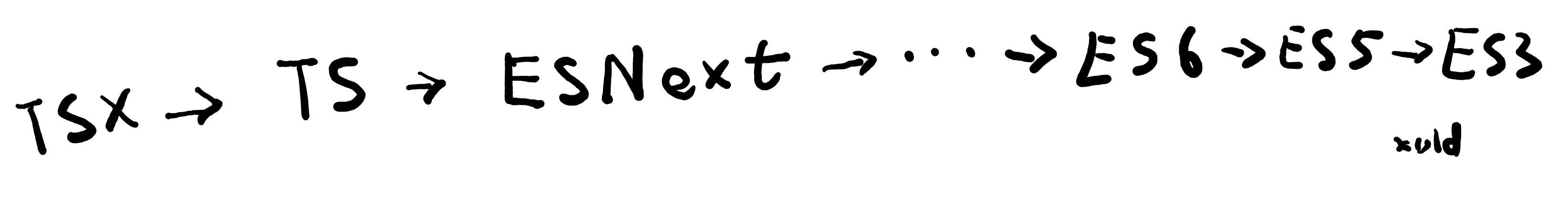
TypeScript 源码中 transformer.ts 负责语法转换,不同的转换器源码则在 transformer 文件夹。
经过以上步骤后,现在已经得到了一个最终的语法树,接下来要做的事情很简单——将语法树重新拼装回代码,并保存到文件。
TypeScript 为了保证对代码的影响最少,生成最终代码时还会保留源代码的注释,同时对齐了缩进。
TypeScript 源码中 emitter.ts 负责生成代码。
此外,TypeScript 还会同时生成源映射(Source Map),以及类型描述文件(.d.ts),这些都将在相关章节详细介绍。
完整的编译流程如图:
上面初步介绍了整个编译流程,以及相关的专业术语。接下来我将按每个阶段分别解读 TypeScript 源码中是如何实现这些流程的。
下一节将具体介绍词法扫描的第一步:字符处理。【不定时更新】
#如果你有问题可以在评论区提问#
标签:循环引用 scan ica 作用域 完整 angular 打包 手动 微软
原文地址:https://www.cnblogs.com/xuld/p/12180913.html