标签:运动 down apt 优点 概念 算法 学习 保留 校正
在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新,其中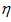 是学习率:
是学习率:
$ \theta=\theta-\eta\bigtriangledown\theta J(\theta) $
优点:
cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值。
缺点:
由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢
训练数较多时,需要较大内存
批量梯度下降不允许在线更新模型,例如新增实例。
和批梯度下降算法相反,Stochastic gradient descent 算法每读入一个数据,便立刻计算cost fuction的梯度来更新参数:
$ \theta=\theta-\eta\bigtriangledown\theta J(\theta;x^{(i)},y^{(i)}) $
优点:
算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的)。
可以在线更新训练数据。
有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优,因为有时候方向会走错,从而跳出局部最优。
缺点:
容易收敛到局部最优。
mini-batch Gradient Descent的方法是在上述两个方法中取折衷, 每次从所有训练数据中取一个子集(mini-batch) 用于计算梯度:
$ \theta=\theta-\eta\bigtriangledown\theta J(\theta;x^{(i:i+n)},y^{(i:i+n)}) $
Mini-batch Gradient Descent在每轮迭代中仅仅计算一个mini-batch的梯度,不仅计算效率高,而且收敛较为稳定。
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
$ \upsilon_{t}=\theta \upsilon_{t-1}-\eta\bigtriangledown\theta J(\theta) $ \\
$ \theta=\theta -\upsilon_{t-1} $
3. Adagrad
上述方法中,对于每一个参数 的训练都使用了相同的学习率 。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的 更新;相反,对于出现频率较高的参数采用较小的 更新。因此,Adagrad非常适合处理稀疏数据。
我们设 为第t轮第i个参数的梯度,即 因此,SGD中参数更新的过程可写为:
Adagrad在每轮训练中对每个参数 的学习率进行更新,参数更新公式如下:
为对角矩阵,每个对角线位置i,i为对应参数 ?,从第1轮到第t轮梯度的平方和。?是平滑项,用于避免分母为0,一般取值1e−8。Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
其中, , 分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 , 的近似 , 是对 , 的校正,这样可以近似为对期望的无偏估计。 Adam算法的提出者建议 的默认值为0.9, 的默认值为.999。
标签:运动 down apt 优点 概念 算法 学习 保留 校正
原文地址:https://www.cnblogs.com/AntonioSu/p/12194403.html