标签:term wan osi out gre sse help roc ges
2020-01-15 08:05:47
Source: https://www.fast.ai//2020/01/13/self_supervised/
Wherever possible, you should aim to start your neural network training with a pre-trained model, and fine tune it. You really don’t want to be starting with random weights, because that’s means that you’re starting with a model that doesn’t know how to do anything at all! With pretraining, you can use 1000x less data than starting from scratch.
So, what do you do if there are no pre-trained models in your domain? For instance, there are very few pre-trained models in the field of medical imaging. One interesting recent paper, Transfusion: Understanding Transfer Learning for Medical Imaging has looked at this question and identified that using even a few early layers from a pretrained ImageNet model can improve both the speed of training, and final accuracy, of medical imaging models. Therefore, you should use a general-purpose pre-trained model, even if it is not in the domain of the problem that you’re working in.
However, as this paper notes, the amount of improvement from an ImageNet pretrained model when applied to medical imaging is not that great. We would like something which works better but doesn’t will need a huge amount of data. The secret is “self-supervised learning”. This is where we train a model using labels that are naturally part of the input data, rather than requiring separate external labels. For instance, this is the secret to ULMFiT, a natural language processing training approach that dramatically improves the state-of-the-art in this important field. In ULMFiT we start by pretraining a “language model” — that is, a model that learns to predict the next word of a sentence. We are not necessarily interested in the language model itself, but it turns out that the model which can complete this task must learn about the nature of language and even a bit about the world in the process of its training. When we’d then take this pretrained language model, and fine tune it for another task, such as sentiment analysis, it turns out that we can very quickly get state-of-the-art results with very little data. For more information about how this works, have a look at this introduction to ULMFiT and language model pretraining.
In self-supervised learning the task that we use for pretraining is known as the “pretext task”. The tasks that we then use for fine tuning are known as the “downstream tasks”. Even although self-supervised learning is nearly universally used in natural language processing nowadays, it is used much less in computer vision models than we might expect, given how well it works. Perhaps this is because ImageNet pretraining has been so widely successful, so folks in communities such as medical imaging may be less familiar with the need for self-supervised learning. In the rest of this post I will endeavor to provide a brief introduction to the use of self-supervised learning in computer vision, in the hope that this might help more people take advantage of this very useful technique.
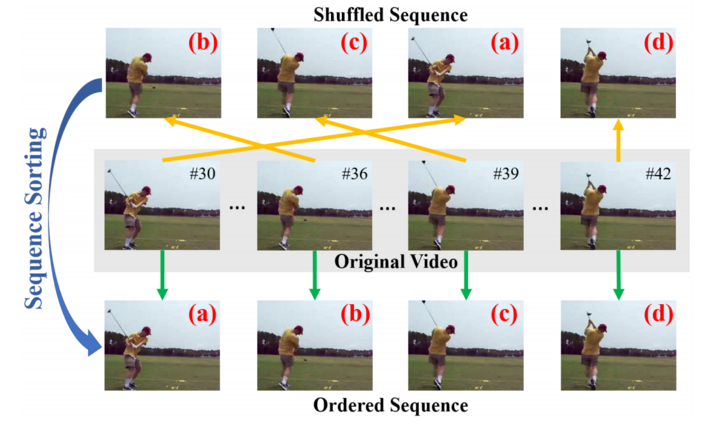
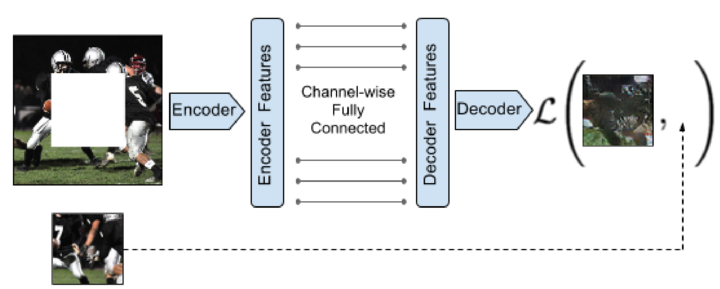
The most important question that needs to be answered in order to use self-supervised learning in computer vision is: “what pretext task should you use?” It turns out that there are many you can choose from. Here is a list of a few, and papers describing them, along with an image from a paper in each section showing the approach.

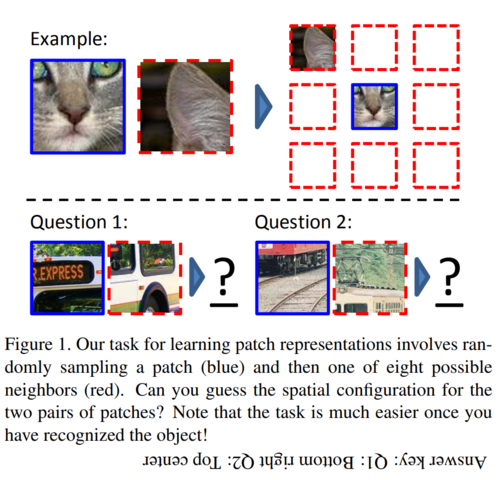
(paper)
(paper)

In this example, the green images are not corrupted, and the red images are corrupted. Note that an overly simple corruption scheme may result in a task that’s too easy, and doesn’t result in useful features. The paper above uses a clever approach that corrupts an autoencoder’s features, and then tries to reconstruct them, to make it a challenging task.
The tasks that you choose needs to be something that, if solved, would require an understanding of your data which would also be needed to solve your downstream task. For instance, practitioners often used as a pretext task something called an “autoencoder”. This is a model which can take an input image, converted into a greatly reduced form (using a bottleneck layer), and then convert it back into something as close as possible to the original image. It is effectively using compression as a pretext task. However, solving this task requires not just regenerating the original image content, but also regenerating any noise in the original image. Therefore, if your downstream task is something where you want to generate higher quality images, then this would be a poor choice of pretext task.
You should also ensure that the pretext task is something that a human could do. For instance, you might use as a pretext task the problem of generating a future frame of a video. But if the frame you try to generate is too far in the future then it may be part of a completely different scene, such that no model could hope to automatically generate it.
Once you have pretrained your model with a pretext task, you can move on to fine tuning. At this point, you should treat this as a transfer learning problem, and therefore you should be careful not to hurt your pretrained weights. Use the things discussed in the ULMFiT paper to help you here, such as gradual unfreezing, discriminative learning rates, and one-cycle training. If you are using fastai2 then you can simply call the fine_tune method to have this all done for you.
Overall, I would suggest not spending too much time creating the perfect pretext model, but just build whatever you can that is reasonably fast and easy. Then you can find out whether it is good enough for your downstream task. Often, it turns out that you don’t need a particularly complex pretext task to get great results on your downstream task. Therefore, you could easily end up wasting time over engineering your pretext task.
Note also that you can do multiple rounds of self-supervised pretraining and regular pretraining. For instance, you could use one of the above approaches for initial pretraining, and then do segmentation for additional pretraining, and then finally train your downstream task. You could also do multiple tasks at once (multi-task learning) at either or both stages. But of course, do the simplest thing first, and then add complexity only if you determine you really need it!
If you’re interested in learning more about self-supervised learning in computer vision, have a look at these recent papers:
Self-supervised learning and computer vision
标签:term wan osi out gre sse help roc ges
原文地址:https://www.cnblogs.com/wangxiaocvpr/p/12194871.html