标签:生成 其他 情况下 mail 基础上 iter running 并且 sqlite3
设计数据库和表结构是做网站的基础。在django中,我们不需要通过SQL语句直接跟数据库打交道,而是完全用python的方式创建数据库模型,之后交给django完成数据库的操作。
利用django开发网站系统,一般情况下,要先编写数据模型,就是在./blog/models.py中写一个类,这个类与数据库中的数据表具有对应关系。
下面就在./blog/models.py中编写博客的数据模型类Blog,本质上它是一个继承了django.db.models.Model的类
./blog/models.py:
from django.db import models from django.db import models from django.utils import timezone from django.contrib.auth.models import User class BlogArticles(models.Model): title = models.CharField(max_length=300) author = models.ForeignKey(User, related_name="blog_posts") body = models.TextField() pulish = models.DateTimeField(default=timezone.now) class Meta: ordering = ("-publish",) def __str__(self): return self.title
代码中,title = models.CharField(max_length=300)定义了字段title,属性为CharField()类型,并且以参数max_length=30的形式说明字段的最大数量。
author = models.ForeignKey(User, related_name="blog_posts")通过author规定了博客文章和用户之间的关系—一个用户对应多篇文章,ForeignKey()就反映了这种“一对多”关系。类User就是BlogArticles的对应对象, related_name="blog_posts"的作用是允许通过类User反向查询到BlogArticles。
class Meta:
ordering = ("-publish",)
上面两句从名称上看貌似python中的元类,但它跟元类不同,在此处,通过ordering = ("-publish",)规定了BlogArticles实例对象的显示顺序,即按照publish字段值的倒叙显示。
BlogArticles类的数据模型编写好了,将来数据库表的基本结构就是按照上述各字段及其属性而定的。如何根据数据模型建立数据库表呢?跟着下面的步骤继续操作。
在/mysite/manage.py位置执行python manage.py makemigrations,结果如下:
[root@localhost mysite]# python3 manage.py makemigrations
Migrations for ‘blog‘:
blog/migrations/0001_initial.py:
- Create model BlogArticles
上面的提示信息高速我们在blog/migrations目录中创建了一个BlogArticles模型,我们打开看下
[root@localhost migrations]# more 0001_initial.py
# -*- coding: utf-8 -*- # Generated by Django 1.10.1 on 2019-10-13 08:09 from __future__ import unicode_literals from django.conf import settings from django.db import migrations, models import django.db.models.deletion import django.utils.timezone class Migration(migrations.Migration): initial = True dependencies = [ migrations.swappable_dependency(settings.AUTH_USER_MODEL), ] operations = [ migrations.CreateModel( name=‘BlogArticles‘, fields=[ (‘id‘, models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name=‘ID‘)), (‘title‘, models.CharField(max_length=300)), (‘body‘, models.TextField()), (‘publish‘, models.DateTimeField(default=django.utils.timezone.now)), (‘author‘, models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name=‘blog_posts‘, t o=settings.AUTH_USER_MODEL)), ], options={ ‘ordering‘: (‘-publish‘,), }, ), ]
这个文件不是我们编写的,是在执行python manage.py makemigrations之后django自动生成的。如果上述代码的含义不是很清楚,还可以用下面的方法看下该文件的本质。
[root@localhost mysite]# python3 manage.py sqlmigrate blog 0001
BEGIN; -- -- Create model BlogArticles -- CREATE TABLE "blog_blogarticles" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "title" varchar(300) NOT NULL, "body" text NOT NULL, "publish" datetime NOT NULL, "author_id" integer NOT NULL REFERENCES "auth_user" ("id")); CREATE INDEX "blog_blogarticles_4f331e2f" ON "blog_blogarticles" ("author_id"); COMMIT;
这只是换一种方式来查看,如果读者熟悉SQL语句,就知道上述文件的功能是创建一个名称为blog_blogarticles的数据库表。这个表的名称由两部分组成,第一部分blog是本应用的名称,第二部分blogarticles(都小写)是在models.py中创建的数据库模型类的名称,中间用单下划线连接。
再观察数据库表中的字段名称,除id是自动生成外,其他都是在数据模型类BlogArticles中所声明的字段及其属性。
上面创建了一个能够建立数据库表的文件,下面就在此基础上,真正创建数据库了。
[root@localhost mysite]# python3 manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, blog, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying blog.0001_initial... OK
Applying sessions.0001_initial... OK
[root@localhost mysite]# ls
blog db.sqlite3 manage.py mysite
对于db.sqlite3这个文件,可以安装一个名为SQLiteSpy的客户端工具,打开保存在项目根目录中的数据库文件db.sqlite3,这个文件可以在pycharm中通过deployment把linux下的该文件下载到windows中,然后SQLiteSpy打开这个文件,如下图所示:
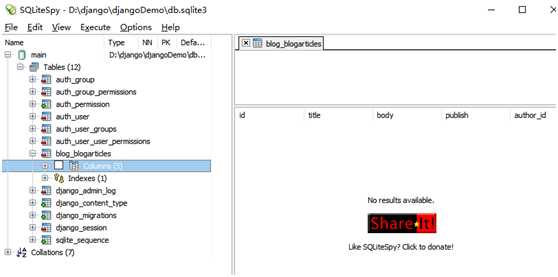
在tables下列出了本项目中目前已有的数据库表,除blog_blogarticles是刚刚通过BlogArticles模型建立的外,别的都是项目默认创建的数据库表。
选中blog_blogarticles后,右边显示该数据库表结构,仔细观察一下每个字段的数据类型,将这里的结果和前面的数据模型类BlogArticles类中所规定的字段及其属性进行对照,进一步理解数据模型类中的各个属性含义。
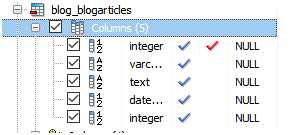
这样就建立了博客的数据库—这是基础,接下来就是发布博客,并保存到这个数据中。
标签:生成 其他 情况下 mail 基础上 iter running 并且 sqlite3
原文地址:https://www.cnblogs.com/xiaxiaoxu/p/12198884.html