标签:建立 备份 清除 recover and 存储 服务 管道 starting
接下来记录一下HBase存储原理相关的知识,理解尚浅,后续再补充。
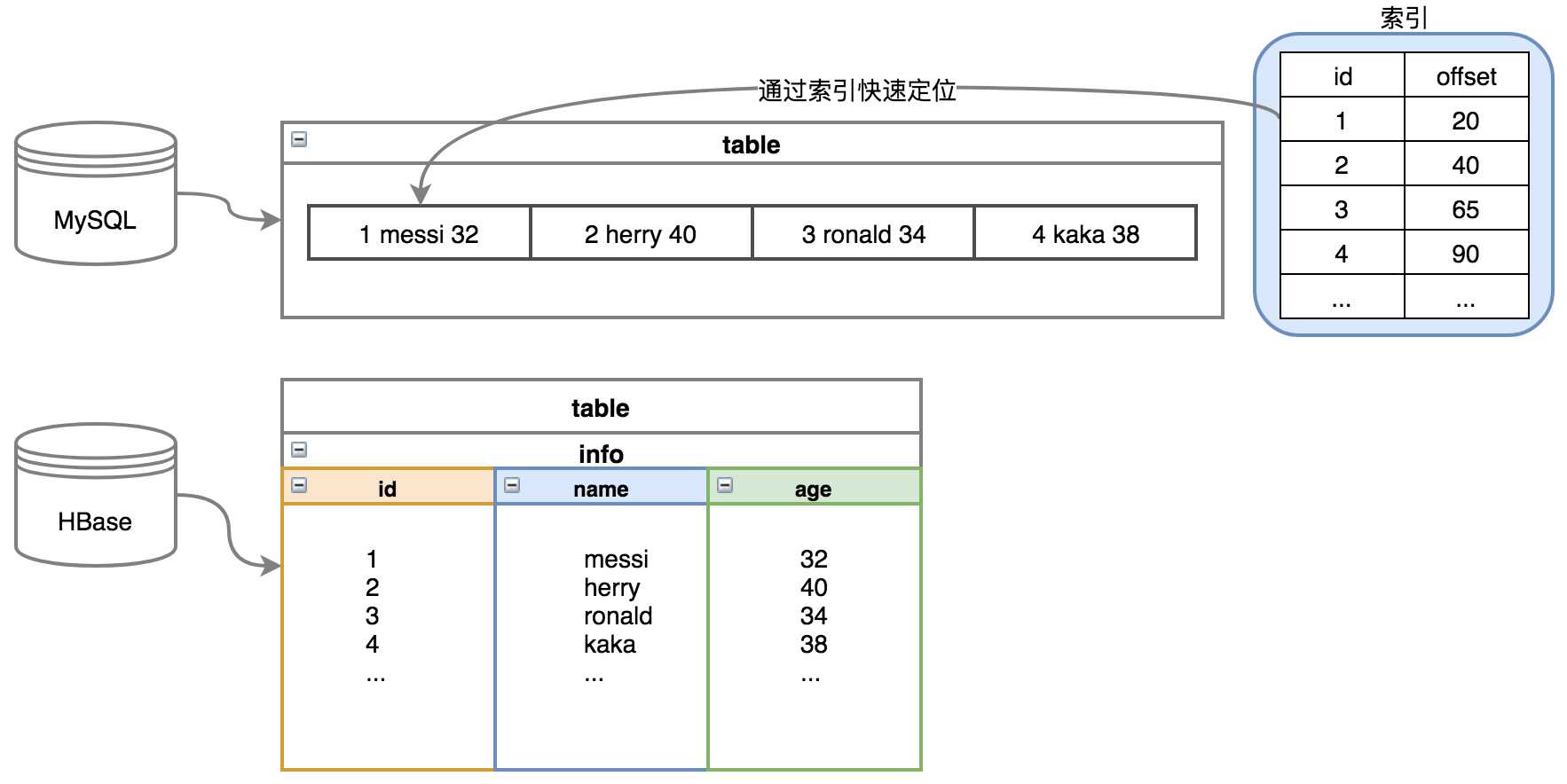
hbase中没有索引,但是mysql有,区别在于mysql是行级存储,hbase是列级存储,索引对行级存储有意义,对于列级存储意义不大。
如下图所示,不管是mysql还是hbase,最终数据都会落地成文件,当给行级存储建立索引,如果想查找id为1的数据,直接通过建立的索引,可以快速定位到数据所在的位置,这样显然比文件中遍历更加高效,如果是列级存储,建立了索引也只对单列数据有效,如想查询{id=1,name=messi,age=32}的数据,单列的索引显得没意义,因此hbase中就暂时没有索引的说法。
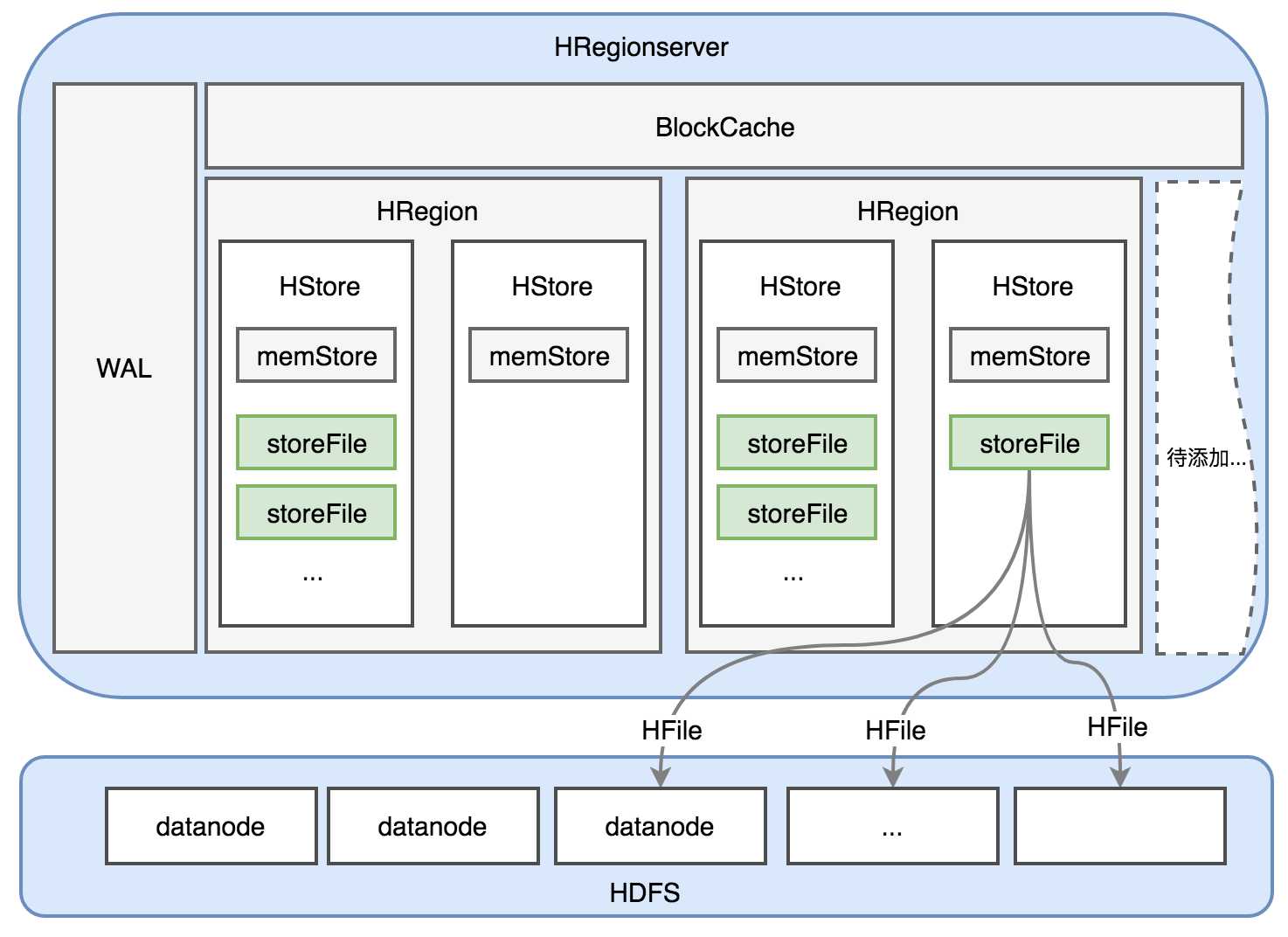
HRegionserver是管理HRegion的,HRegion中的数据最终会以HFile的形式落地到hdfs,因此它和dataNode部署在同一个节点上(数据本地化策略,这样可以减少网络IO消耗),以下是它的主要组成结构图。
① WAL:写日志相关
② BlockCache:读缓存相关
③ HRegion:写缓存,存储相关
后面将一一说明这些组成部分,最后storeFile会以HFile的形式落地到hdfs,因此hbase也具有了副本策略。
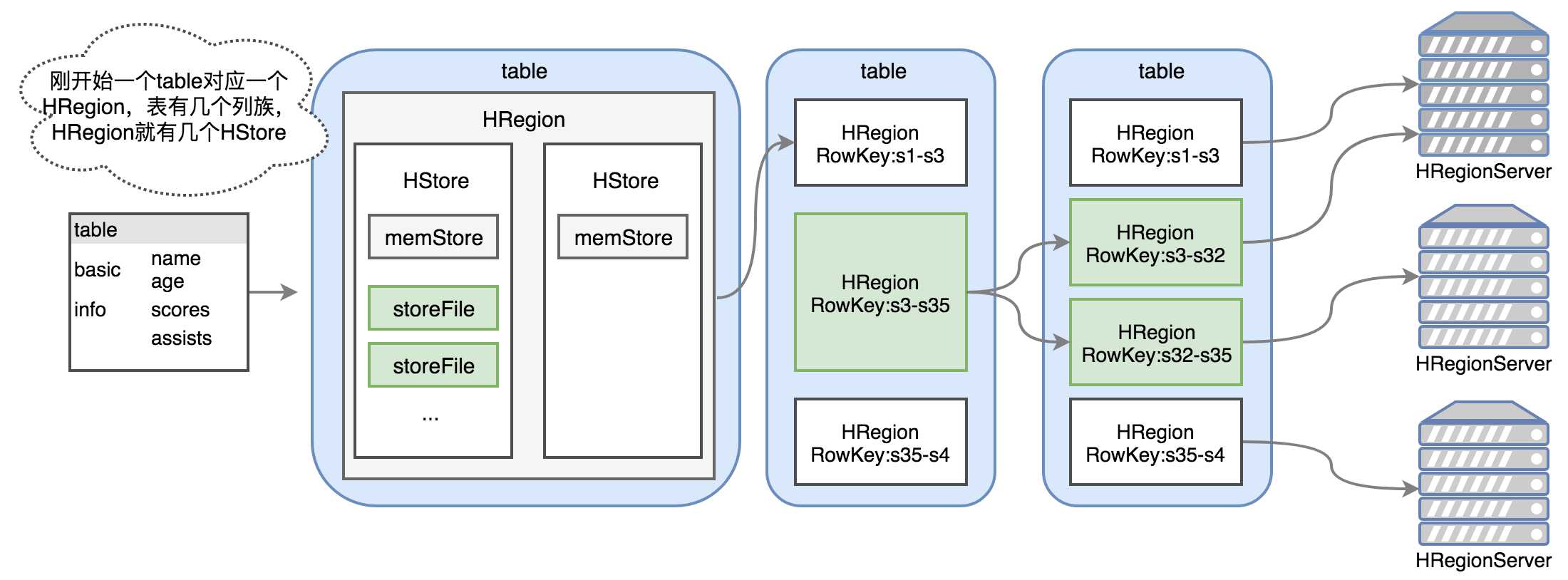
hbase中一个表会在行键的方向上,会被切分为一个或多个HRegion,其中HRegion是分布式存储的最小单元,以下是对HRegion的说明记录。
(1)HRegion里有至少一个HStore,一个HStore对应一个列族,因为表中列族至少有一个,因此HRegion中就至少有一个HStore。
(2)memStore是写缓存,默认128MB,写入hbase的数据不是直接写入到hdfs,而是会经过写缓存,写缓存里会根据字典序对行键排序,它有一定的规则来冲刷,冲刷后的文件就是storeFile。
(3)storeFile的数目是0到多个,如果memStore还没有写出,那就没有storeFile,写出就有,它是存储的最小单元,存储到hdfs后会变成HFile的形式,其中storeFile是HFile的轻量版封装。
(4)刚开始table不大时,一个HRegion就可以应付,当数据量大于阈值10G时(默认10G,可以通过hbase.hregion.max.filesize来配置,范围1~20G),HRegion会分裂成两个同样大小的HRegion,并且其中一个HRegion的管理权会发生转移。如果RowKey为s3-s35的数据量大于10G时,会分裂成两个新的HRegion,可以看出行键都是按照字典序排列,因此多个HRegion之间没有数据的交叉。
(5)HRegion交由HRegionServer来管理,后者跟DataNode在同一个节点上,符合数据本地化策略。
WAL即write ahead log,是维系在磁盘上的文件,所有的写操作(如put、delete),首先会写入这个文件,当写成功后才会写入memStore。当发生HRegionserver的宕机,依然可以从这个文件中进行数据的恢复。
文件是以HLog作为实现类,它是hadoop sequence file,key为HLogKey对象,其中包含数据的归属信息,如表名、HRegion、写入时间戳、sequence number等,value为hbase中的KeyValue对象(待补充)。
在0.94版本之前,WAL往里写入数据是阻塞的,会影响性能,为了优化,在1.0版本后使用了多管道并行技术。
一个HRegionserver中只有一个blockcache,维系在内存中,默认128M。限于它的空间有限,会采取‘引用局部性原理‘,来缓存下次访问能大概率命中的数据。
(1)时间局部性:数据被访问后,下次这条数据将大概率被访问到。
(2)空间局部性:数据被访问后,下次这条数据附近的数据也将大概率被访问到。空间局部性缓存的数据最小单位是datablock,datablock中一条数据被读取,则整个datablock都会被缓存到blockcache。
由于它的大小有限,数据跟redis类似,会采用淘汰策略来清除,默认采用on-heap LRU BlockCache策略,即删除最近最少使用,以及最长时间没有被使用的数据。
zookeeper负责管理hbase上的节点,hbase启动后会注册一个持久节点hbase,下面有很多的子节点。其中master和backup-masters子节点分别保存active HMaster和standby HMaster,这两个子结点都是临时节点,其中一个挂掉另外一个就能监听到,这利用了zookeeper的watcher。
(1)如果active HMaster宕机,standby HMaster会顶替为active来提供服务。
(2)active HMaster会监控backup-masters里的standby HMaster,选择还存活的备用节点进行数据的同步,为下次故障转移做准备。
# 查看hbase持久节点下的节点 [zk: localhost:2181(CONNECTED) 18] ls /hbase [replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, region-in-transition, online-snapshot, master, running, recovering-regions, draining, namespace, hbaseid, table] # 查看master节点内容,hadoop01为active HMaster [zk: localhost:2181(CONNECTED) 20] get /hbase/master ?master:60000K‘1????PBUF
# hadoop01为active hadoop01???????- cZxid = 0x480000000a ctime = Tue Jan 14 13:57:58 CST 2020 mZxid = 0x480000000a mtime = Tue Jan 14 13:57:58 CST 2020 pZxid = 0x480000000a cversion = 0 dataVersion = 0 aclVersion = 0
# 显示不为0X0,说明是临时节点,后面的16进制数字代表session id ephemeralOwner = 0x16fa2a06d490001 dataLength = 54 numChildren = 0 # hadoop02为backup HMaster [zk: localhost:2181(CONNECTED) 21] ls /hbase/backup-masters
# 下面一整串,就是备用节点的名字 [hadoop02,60000,1579027138325]
前面hbase启动后会有一个HMaster以及多个HRegionserver,这个HMaster就是管理HRegionserver的主节点,它可以启动多个。而HRegionserver是管理多个HRegion的从节点。
(1)HMaster可以启动多个,先启动的就是主节点,后启动都是从节点,主节点注册在zookeeper的/hbase/master节点,从节点注册在/hbase/backup-masters节点下。通过如下hbase-daemon.sh start master命令就可以启动一个HMaster,虽然不限制启动的个数,但是考虑到备份数据占用网络IO影响效率,不宜超过3个。
[root@hadoop02 /home/software/hbase-0.98.17-hadoop2/bin]# sh hbase-daemon.sh start master starting master, logging to /home/software/hbase-0.98.17-hadoop2/bin/../logs/hbase-root-master-hadoop02.out
(2)HMaster负责表的DDL操作,如create,drop,enable和disable等,如下图所示。

(3)为了确认HMaster还存活,它会定期(默认180s)向zookeeper发送心跳, 实际应用中为了更快的检测故障并转移,会将时间设置得更短,一般为10-30秒。
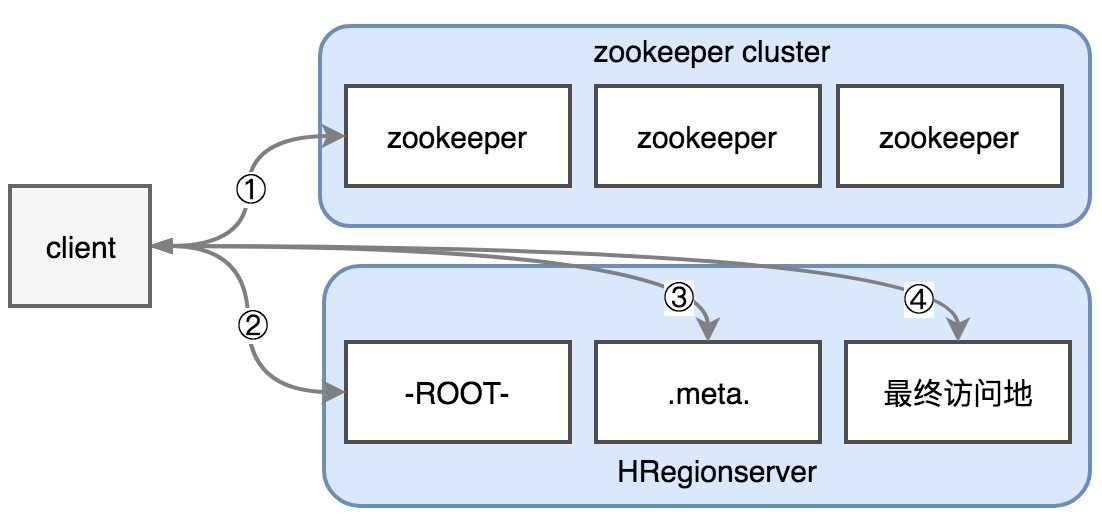
hbase的读写分为hbase0.96版本之前和之后,之前要复杂一些,因为里面涉及到一步鸡肋的-ROOT-文件的读取,0.96版本之前主要步骤如下。
① client对hbase发起请求,如put/get请求,首先会访问zookeeper节点root-region-server,获取到-ROOT-文件的位置。
② 获取到-ROOT-文件位置后,它实际存储在某个HRegionserver的节点上,如图用第一个表示,找到后会读取-ROOT-数据内容,获取到.meta.文件的位置。
③ 获取到.meta.文件的位置后,它可能存储在另外一个HRegionserver节点,如图用第二个表示,找到后读取其中内容,获取到数据对应的HRegion,以及HRegionserver位置。
④ 直接访问最终访问地HRegionserver后,跟它进行通信完成读写。
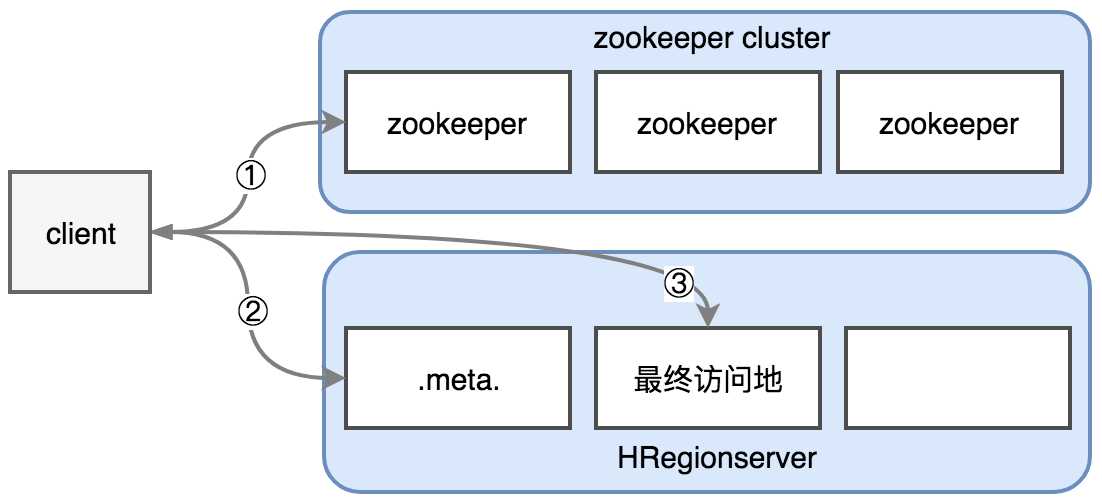
这种步骤错误的估计了meta文件的大小,hbase中元数据包括namespace、表名、列族、表-HRegion关系数据、HRegion-HRegionserver关系数据等。一个表的元数据,一般几KB,因此一般的项目,元数据也就十几MB的大小,为了这样大小的元数据专门设置一个-ROOT-目录来管理显得没有意义,因此在hbase0.96后的版本对它进行了舍弃,以上步骤将没有第一步,将更新为以下如图所示步骤。
① client对hbase发起请求,如put/get请求,首先会访问zookeeper节点meta-region-server,获取到.meta.文件的位置,客户端获取这个位置信息后会进行缓存。
② 获取到.meta.文件位置后,它实际存储在某个HRegionserver的节点上,如图用第一个表示,找到后读取其中内容,获取到数据对应的HRegion,以及HRegionserver位置。客户端也会缓存.meta.文件中的内容,如果读取的次数越多这个文件将越大,下次发起请求将可以直接读取缓存数据,提高效率。但是在HRegion发生分裂或者client宕机后,需要重新读取建立缓存。
③ 直接访问最终访问地HRegionserver后,跟它进行通信完成读写。
接上面读写整体概括,当写操作达到最终目的地HRegionserver后,执行以下流程。
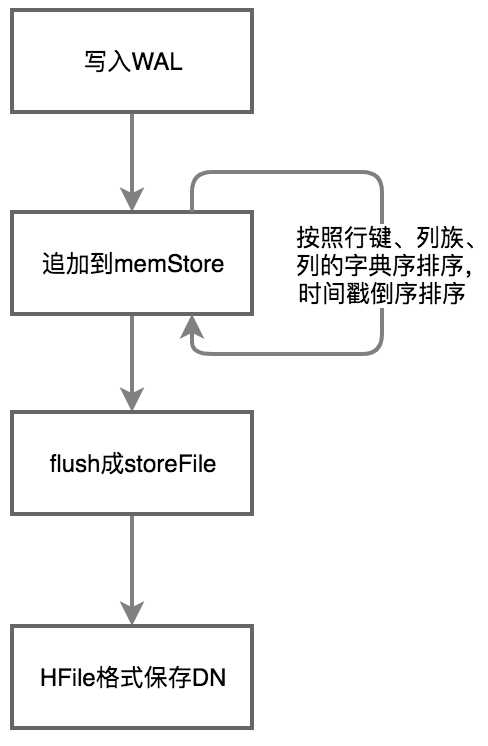
(1)先将操作写入到WAL中。
(2)将数据追加到menStore中,menStore中数据会进行排序。
现在有个问题,如果在进行写操作的时候,想更新一条数据的值,恰好更新的数据也在memStore中,是否应该去更新它呢?答案是否定的,hbase中这里采用顺序写,即更新内容以追加的形式进入memStore,而不是移动指针到以前数据的位置进行更改。为了性能考虑,hbase采用顺序写,而不是随机写(可以移动指针修改)。
(3)menStore数据达到一定条件会冲刷,memStore冲刷的条件有三,一般在稳定运行的项目上容易实现条件三,因为数据量上去了,自然memStore就多了,每个默认128M,多了就物理内存会吃不消会冲刷:
a.写缓存满,冲刷;
b.WAL达到1G,冲刷,并且新建WAL;
c.当HRegionserver下所有的memStore之和占用的空间达到物理内存的35%,冲刷最大的那个memStore。
(4)冲刷成HFile后,单个HFile是有序的,因为在冲刷之前以前需排序过了,所以HFile上将把持起始行键和结束行键。
关于HFile,目前前后经历了3个版本,以第一个版本来说明它的格式内容,后面两个版本就是添加了其他的内容,差别不是很大。
HFile格式如下图所示。
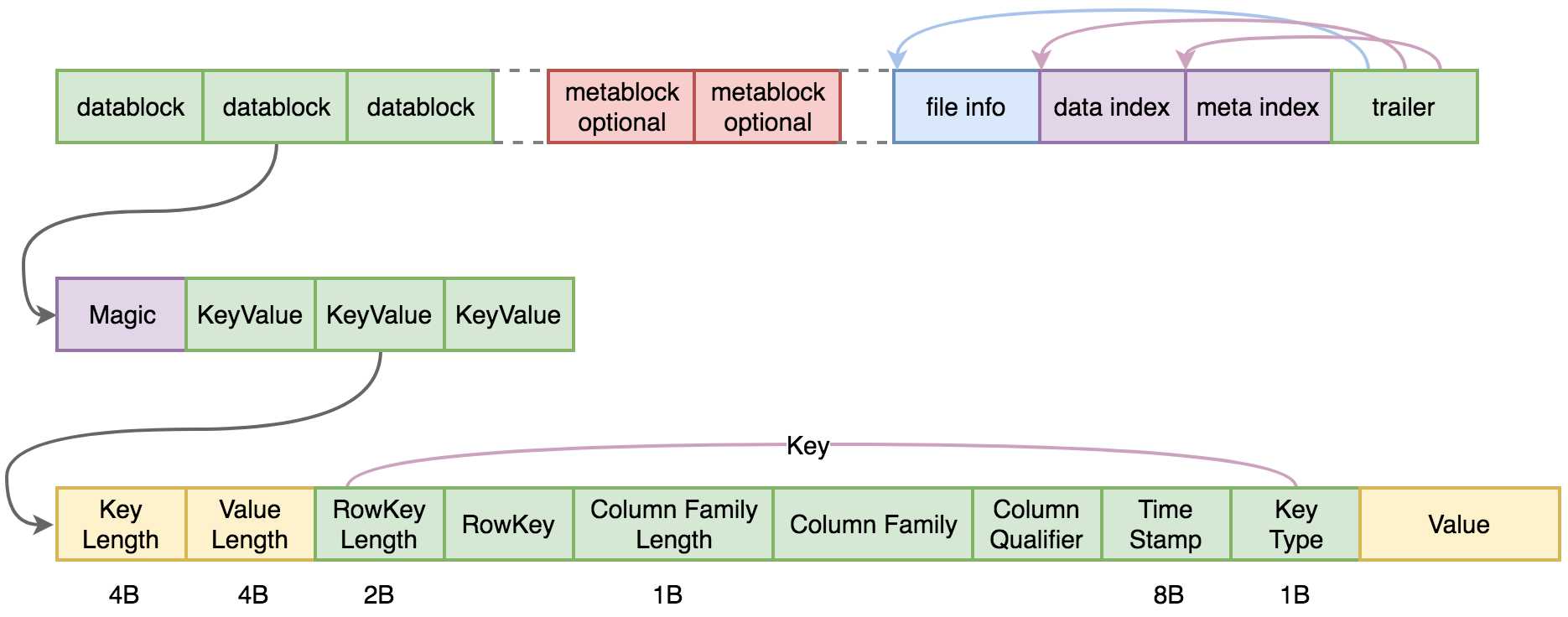
(1)datablock存储数据
a.每个datablock都是有序的,也会有起始行键和结束行键,便于数据查找。
b.默认大小64KB,可以调整,如果调小便于get查找,即字段查,调大便于scan查找,即顺序读。
c.一个datablock由魔数Magic和多个KeyValue组成。魔数本质上就是一个随机数,除了表明这是一个datablock外,还可以用于验证datablock文件完整性,或者是否修改,如果有变动则魔数会变,因此它可以用于验证。
d.KeyValue本质是一个byte数组,如图所示key包含信息很多,而value是二进制数据。
e.在HFile V2版本中,最后还引入了BloomFilter布隆过滤器。
(2)metablock存储元数据,这个部分一般是可选,出现在.meta.文件中。
(3)file info,即HFile的描述信息,如AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY,COMPARATOR, MAX_SEQ_ID_KEY等。
(4)data index,记录datablock的在HFile中的起始位置。
(5)meta index,记录metablock的在HFile中的起始位置。
(6)trail,里面记录了data index和meta index的起始位置,也记录了file info的起始位置。
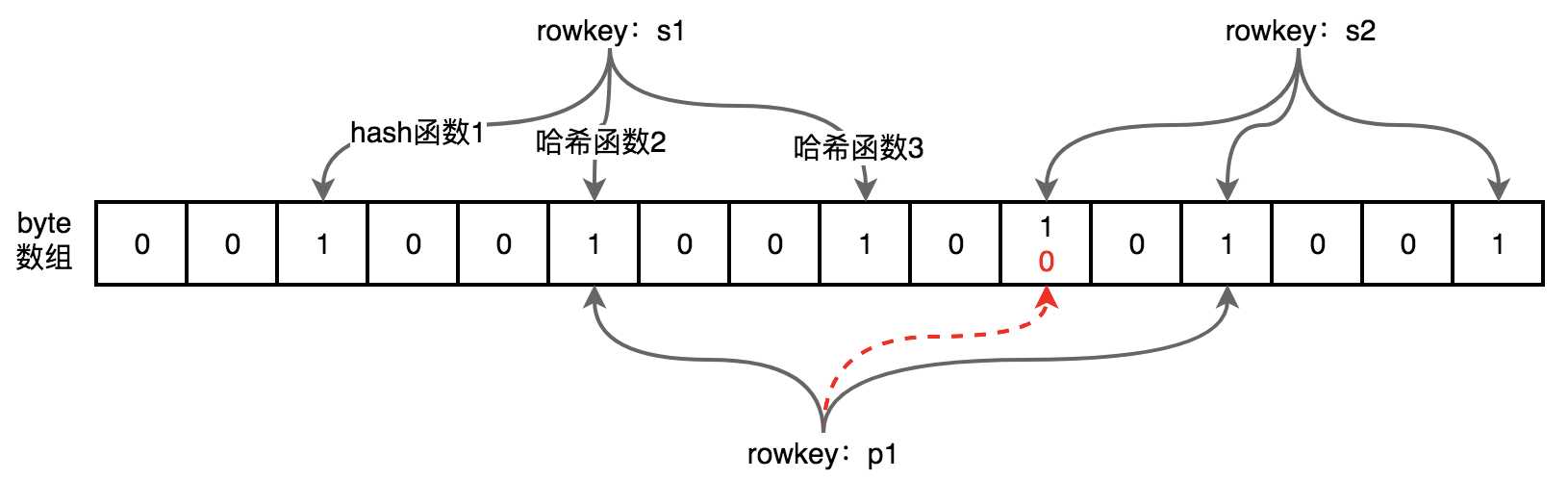
布隆过滤器,是为了查找HFile更快速而在V2版本中添加的。因为如果读取一个数据,只是使用行键来查询,过滤掉剩下的HFile可能依然很多,定位还不够快,V2版本中添加的布隆过滤器,可以将不存在这个行键的HFile再过滤,这样剩下的HFile就更加值得遍历查询,提高了读取的速度。
布隆过滤器会维持一个byte数组,它的特点是能确定一个数据确定没有,但是不能确定一定有。如下图所示,一个数据会通过三个不同的哈希函数来映射到byte数组上的位置,如果有一个不为1,则能肯定这个数据没有,如p1。如果全部为1,不一定确定有,如p1映射的结果有一个本来为0,但是这个数据会被s2覆盖,这样p1映射结果有不为1的但是byte数组对应位置全为1,造成有p1数据的假象,但实际却没有。
如果数据量多了,会造成判断的失误,因此这种过滤器适宜用在不要求100%准确率,但是需要这种功能的场景。
接上面读写整体概括,当读操作达到最终目的地HRegionserver后,执行以下流程。
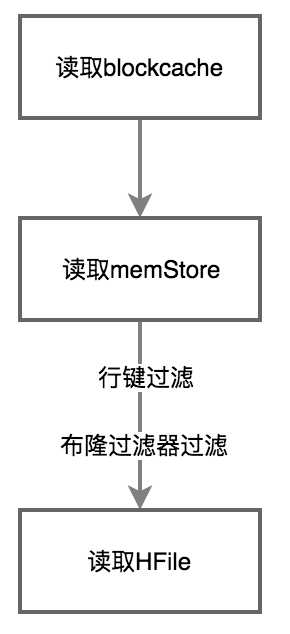
(1)先读取读缓存。
(2)读缓存没有,就去memStore查找
(3)memStore中没有就去HFile中查找,需要进行过滤,提高读取速度。
前面的memStore很容易冲刷出HFile,这样很容易产生很多小文件,显然对hdfs存储来说是不利的,hbase考虑到了这一点,因此就有了compaction机制,分为minor compact和major compact。
hbase默认采用minor compact对HFile进行合并,因为效率高。
major compact是memStore中所有HFile一起合并,这种合并执行效率低,一般需要好几个小时,一般安排在凌晨或周末进行。
以上是对hbase原理的总结,后续再完善。
参考博文:
(1)《HBase权威指南中文版》
(2)https://www.jianshu.com/p/53864dc3f7b4
标签:建立 备份 清除 recover and 存储 服务 管道 starting
原文地址:https://www.cnblogs.com/youngchaolin/p/12187151.html