标签:使用 错误 bin 应用程序 mamicode 非阻塞 服务器 没有 udp数据报
1.端口号
端口号用于区分使用相同协议的进程。
TCP69 与 UDP69 是不同的。
端口号范围 0 - 65535, 其中 0- 1023 是保留端口。
2.套接字对
TCP服务通过套接字对,唯一识别进程。
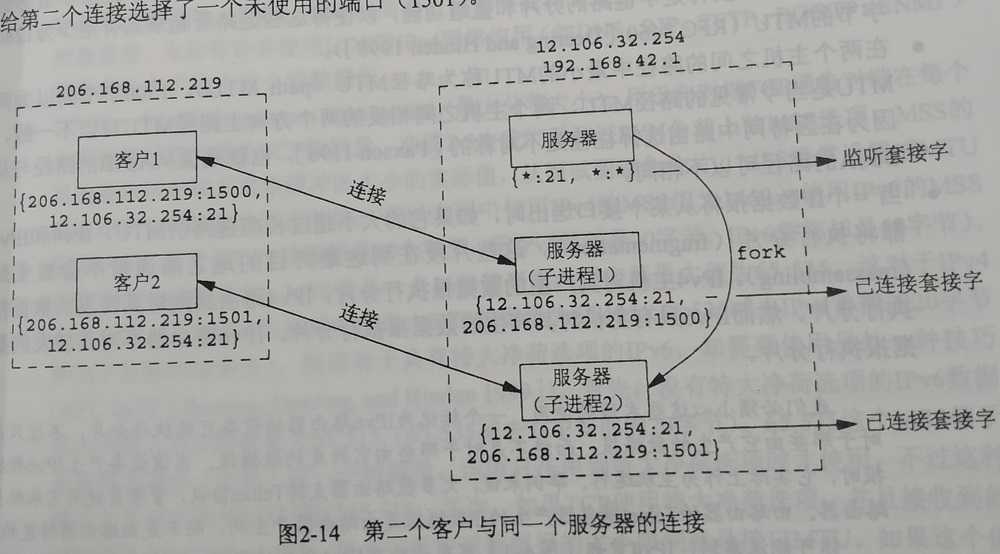
如上,服务器fork后,两个子进程都 bind 了 12.106.32.254:21,那么TCP服务收到对端的数据包,应该给哪个进程呢?
所以套接字对才是数据收发的唯一表示,两个套接字对,是连接的唯一标识。
3.TCP输出

如上,TCP是带缓存的。
(1)应用程序调用 write,数据只是拷贝到TCP缓存,如果缓存空间不足,write会阻塞(若设置非阻塞,会直接返回),直到所有数据传到 TCP缓存。
所以write返回后,并不表示数据传到了对端,只是写入了TCP缓存。
(2)TCP缓存的大小可以用 SO_SNDBUF 设置
(3)TCP如何处理缓存数据?
TCP会按照MSS进行分节,并保留副本,并传递给IP层,IP层会打包分组,传到链路层,链路层按照MTU生成帧,传到物理层。
这里:
MSS <= MTU - 20(TCP首部字节数) - 20(IP首部字节数)
是设置MSS的推荐方法,原因是避免MTU分组
(4)TCP会等待对端的ACK,收到ACK,就将缓存对应分节释放,若没收到,要超时重传
(5)TCP的分节最终会到链路层的输出队列,若输出队列已满,链路层会丢弃分组,并使用协议栈向上报错,TCP会注意这个错误,并在某个时刻重传分节。
上面操作,应用无需关心。
3.UDP输出
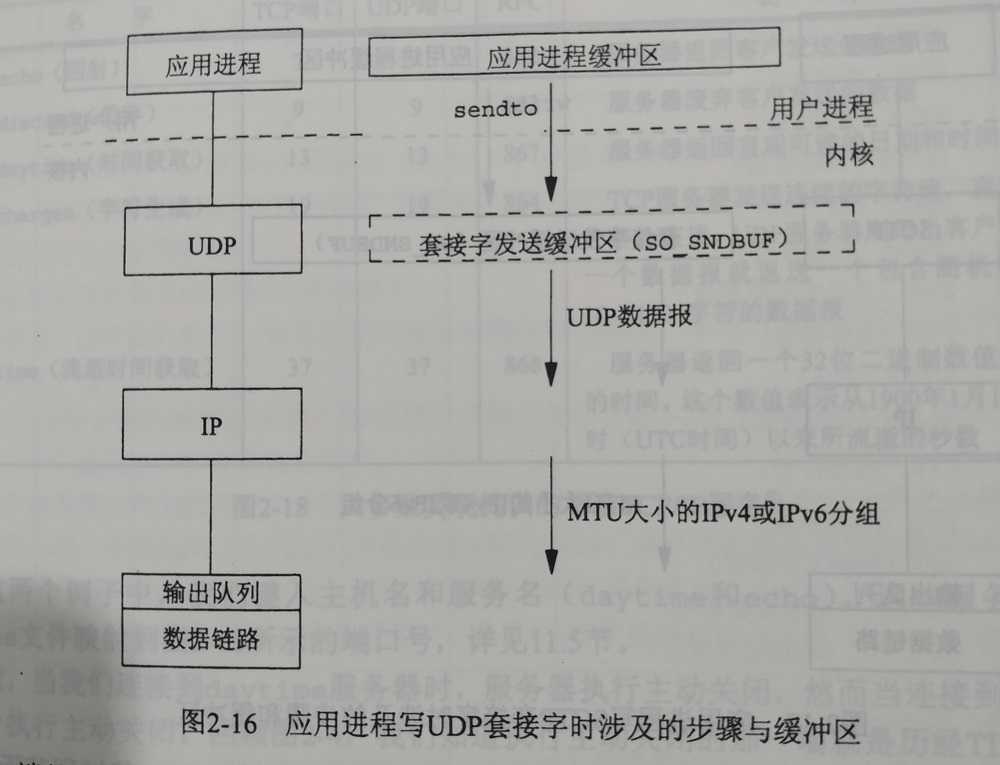
如上,UDP分组是没有缓存的。因为UDP不可靠,所以不需要保存数据副本。
(1)UDP可以使用SO_SNDBUF设置UDP数据报的大小上线,如果应用传入的数据超出上线,内核向进程返回错误EMSGSIZE。
(2)应用写的数据,实际上是写入内核缓存,缓存的数据传入链路层输出队列,就直接丢弃。
(3)如果链路层输出队列满了,会丢弃UDP的数据,并向上报错,内核会返回ENOBUFS错误给进程。
(4)UDP无法设置MSS,由于MTU的缘故,写入大数据时,会造成比TCP更多的分片。
标签:使用 错误 bin 应用程序 mamicode 非阻塞 服务器 没有 udp数据报
原文地址:https://www.cnblogs.com/yangxinrui/p/12203801.html