标签:请求 提取 调度 mit extract 配置文件 深度 去除 爬虫
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
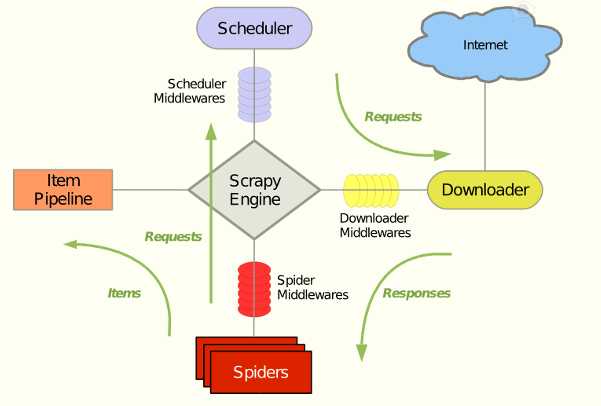
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
用来处理整个系统的数据流处理,触发事务(加载核心)。
Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个url(抓取网页的网址或者说是链接)的优先队列,由它来绝对下一个要抓取的网址是什么,同时去除重复的网址
Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item).用户也可以从中提取链接,让Scrapy继续抓取下一个页面
Item Pipeline(管道):
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
Downloader Middlewares(下载中间件):
一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
pip3 install scrapy
# 1.安装wheel 1.pip3 install wheel # 2.下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted # 3.安装twisted 进入下载目录,执行pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl # 4.安装pywin32 pip3 install pywin32 # 5.安装scrapy pip3 install scrapy
# 在pyCharm的终端执行 # 切换到当前目录下 cd scrapy_practice # 创建一个项目 scrapy startproject proname # 切换到当前项目文件目录下 cd proname # 创建爬虫文件 scrapy genspider spidername www.xxx.com # 执行命令爬虫的文件 scrapy crawl spidername # settings配置文件 1.默认是遵从robots协议的,ROBOTSTXT_OBEY = True改为False,就不遵从robots协议 2.UA伪装 3.LOG_LEVEL = "ERROR" # 修改日志的输出等级,让日志值输出错误信息
import scrapy class FirstSpider(scrapy.Spider): # 爬虫文件的名称;爬虫源文件的唯一标识 name = "first"
# 允许的域名:就是对起始的url列表进行限制(通常情况下都会注释) allowed_domains = [‘www.xxx.com‘]
# 起始的url列表:列表中的列表元素会被scrapy自动的进行请求发送,可以存放多个 start_urls = [‘http://www.xxx.com/‘,‘http://www.xxx2.com/‘]
# 解析数据 def parse(self, response): print(response)
extract():列表是有多个列表元素
extract_first():列表元素只有单个
import scrapy class FirstSpider(scrapy.Spider): # 爬虫文件的名称:爬虫源文件的唯一标识 name = ‘first‘ # 允许的域名: allowed_domains = [‘www.baidu.com‘] #起始的url列表:列表中的列表元素会被scrapy自动的进行请求发送 start_urls = [‘https://dig.chouti.com/‘] #解析数据 def parse(self, response): div_list = response.xpath(‘/html/body/main/div/div/div[1]/div/div[2]/div[1]‘) for div in div_list: # 注意:xpath返回的列表中的列表元素是Selector对象,我们要解析获取的字符串的数据是存储在该对象中必须经过一个extract()的操作才可以将改对象中存储的字符串的数据获取 # content = div.xpath(‘./div/div/div[1]/a/text()‘)[0].extract() content = div.xpath(‘./div/div/div[1]/a/text()‘).extract_first() # xpath返回的列表中的列表元素有多个(Selector对象),想要将每一个列表元素对应的Selector中的字符串取出改如何操作?response.xpath(‘/div//text()‘).extract() print(content) # <Selector xxx=‘dsdsd‘ data="短发hi的说法绝对是">
只可以将parse方法的返回值存储到磁盘文件中
# 返回值的数据统一写入当前file.csv文件中,如果文件不存在就会新建文件 scrapy crawl first -o file.csv # 对文件的后缀有限制,支持的文件后缀有:(‘json‘, ‘jsonlines‘, ‘jl‘, ‘csv‘, ‘xml‘, ‘marshal‘, ‘pickle‘)
import scrapy class HuyaSpider(scrapy.Spider): name = ‘huya‘ # allowed_domains = [‘www.xxx.com‘] start_urls = [‘https://www.huya.com/g/xingxiu/‘] def parse(self, response): print(response) li_list = response.xpath(‘//*[@id="js-live-list"]/li‘) dic_list = [] for li in li_list: title = li.xpath(‘./a[2]/text()‘).extract_first() authod = li.xpath(‘./span/span[1]/i/text()‘).extract_first() hot = li.xpath(‘./span/span[2]/i[2]/text()‘).extract_first() dic = { "title": title, "authod": authod, "hot": hot, } dic_list.append(dic) return dic_list # 在终端命令输出 D:\practice\crawler_practice\scrapy框架的应用\huyaproject>scrapy crawl huya -o huya.csv
编码流程:

细节补充:
# huya.py import scrapy from huyaPro.items import HuyaproItem class HuyaSpider(scrapy.Spider): name = ‘huya‘ # allowed_domains = [‘www.xxx.com‘] start_urls = [‘https://www.huya.com/g/xingxiu‘] def parse(self, response): li_list = response.xpath(‘//*[@id="js-live-list"]/li‘) for li in li_list: title = li.xpath(‘./a[2]/text()‘).extract_first() author = li.xpath(‘./span/span[1]/i/text()‘).extract_first() hot = li.xpath(‘./span/span[2]/i[2]/text()‘).extract_first() # 实例化item类型的对象 item = HuyaproItem() item[‘title‘] = title item[‘author‘] = author item[‘hot‘] = hot yield item # 提交给管道 # items.py import scrapy class HuyaproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() # Field是一个万能的数据类型(可以任意类型的数据) author = scrapy.Field() hot = scrapy.Field() # pipeline.py import pymysql from redis import Redis # 写入文件中 class HuyaprojectPipeline(object): fp = None def open_spider(self,spider): print("只会在爬虫开始的时候执行一次") self.fp = open("huyazhibo.txt","w",encoding="utf-8") def process_item(self, item, spider): # item就是接收到爬虫类提交过来的item对象 self.fp.write(item[‘title‘]+‘:‘+item[‘author‘]+‘:‘+item[‘hot‘]+‘\n‘) print(item["item"],"写入成功") return item def close_spider(self,spider): print("只会在爬虫结束的时候的调用一次") self.fp.close() # 写入mysql数据库中 class mysqlPipeLine(object): conn = None cursor = None def open_spider(self,spider): self.conn = pymysql.Connect( host=‘127.0.0.1‘, port=3306, user=‘root‘, password=‘123‘, db=‘Spider‘, charset=‘utf8‘) def process_item(self,item,spider): sql = ‘insert into huya values("%s","%s","%s")‘%(item[‘title‘],item[‘author‘],item[‘hot‘]) self.cursor = self.conn.cursor() try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self,spider): self.cursor.close() self.conn .close() # 写radis数据库中 class RedisPipeLine(object): conn = None def open_spider(self,spider): self.conn = Redis(host=‘127.0.0.1‘,port=6379) def process_item(self,item,spider): self.conn.lpush(‘huyaList‘,item) return item
待续
标签:请求 提取 调度 mit extract 配置文件 深度 去除 爬虫
原文地址:https://www.cnblogs.com/zangyue/p/12207349.html