标签:nan array clu 除了 依赖 来历 参数设置 使用 ica
好了,大家现在进入到机器学习中的一块核心部分了,那就是特征工程,洋文叫做Feature Engineering。实际在机器学习的应用中,真正用于算法的结构分析和部署的工作只占很少的一部分,相反,用于特征工程的时间基本都占70%以上,因为是实际的工作中,绝大部分的数据都是非标数据。因而这一块的内容是非常重要和必要的,如果想要提高机器学习应用开发的效率,feature engineering就像一把钥匙,一个加速器,能给整个项目带来事半功倍的效果。另外,feature engineering做的好不好,直接关系到后面的模型的质量。正因为上面的原因,feature engineering我准备详细的解释,我准备花三篇随笔说完。这是第一篇,主要介绍两部分,分别是missing value的处理和categorical data的处理。其中missing value的处理相对简单,复杂的是categorical data的处理,有很多种处理方式,我们在这边就直说常用的5中方式。那么好啦,咱们就直接进入主题内容吧。
missing value 顾名思义就是有些实际数据中,有很多的数值是缺失的,那么怎么处理这些缺失的数据,就变成了一个很有必要的事情。基本上,咱们处理missing value的方法就是三种,分别是:dropping, Imputation, 和 An extension to imputation。那下面就这三种方法分别来进行代码的演示和结果的展示
missing_data_cols = [col for col in train_X.columns if train_X[col].isna().any()] #drop missing data columns reduced_train_X = train_X.drop(missing_data_cols, axis =1)
上面代码的第一句是为了找出所有含有空数据的column,第二句代码的意思就是删除掉这些含有空数据的column,记住axis参数设置成1代表着是column,如果设置成0或者没有设置,则默认指删除行row。
from sklearn.impute import SimpleImputer my_imputer = SimpleImputer(strategy = "mean") my_imputer.fit_transform(train_X) imputed_train_X = pd.DataFrame(my_imputer.fit_transform(train_X))
注意这里需要引进一个新的库进行数据处理,那就是sklearn, 它是sci-kit learn的缩写。这个库也是一个很牛逼的库,它和TensorFlow的功能一样,提供了丰富的数据处理方面的接口,可以极大的方便咱们的数据处理,也提供了很多常用的模型供咱们选择,在机器学习领域可以说是经常用到的。上面第二行代码就是设置通过什么方式来impute,这里设置的是平均数。第三行返回的是一个numpy array,第四行咱们将这个impute过后的numpy array转化成dataframe。
X_train_extension = train_X.copy() X_val_extension = val_X.copy() #making columns with missing data for col in missing_data_cols: X_train_extension[col + "_was_missing"] = train_X[col].isnull() #imputation my_imputer = SimpleImputer() X_train_extension_impute = pd.DataFrame(my_imputer.fit_transform(X_train_extension))
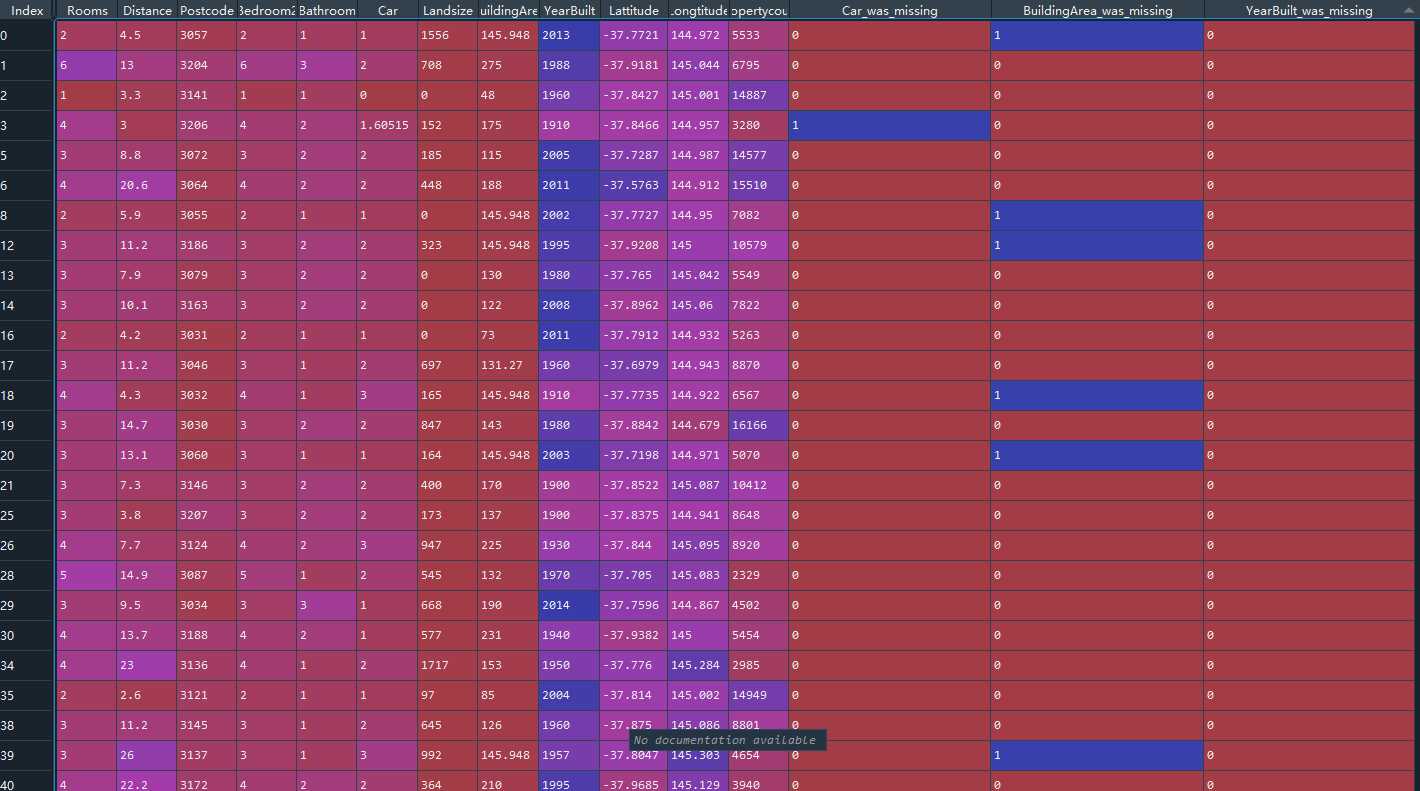
上面展示了代码还有一小段结果的截图。大家可以很明显的看出来添加了三个新的columns。这里的顺序根据代码也可以看出来,是先添加新的columns,然后再imputation。
上面一节主要讲的是Missing value的一些简单的处理方式,在实际的数据处理中,咱们大部分时间遇到的数据并不是numerical data,相反,咱们大部分时间遇到的都是categorical data,可是在咱们的计算机处理数据的时候,处理的都是numerical data,所以咱们得想办法将这些categorical data转成numerical才行。实际中咱们经常使用的策略就是下面的五种方式,下面咱们来一个个讲解一下,这一块也是咱们的重点内容。
X_train_result_drop = X_train_result.select_dtypes(exclude=["object"])
看看上面这一句简单的代码,通过dataframe的select_dtypes方法,传递一个exclude参数,因为在dataframe中object的数据类型就是categorical data,所以上面的api直接就是删除了所有categorical data的数据。
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder() X_train_result_label[col] = label_encoder.fit_transform(X_train_result[col])#one column after one column
咱们也可以看出,咱们得先创建一个LabelEncoder实例对象,然后对每一个categorical data的column分别应用encoder, 如果需要对多个categorical column进行lable encoding, 咱们得写一个循环,分别对每一个column 进行label encoding。
one-hot encoding。这是一个大家可能最常用到的一种category encoding的方法,至少在我学习机器学习的过程中,这是最常见到的一种方式,那么到底什么是one-hot encoding呢?这里没有一个官方的定义,最直接的方法就是先看一下下面的图片,这是最直接的方式,也最简单易懂 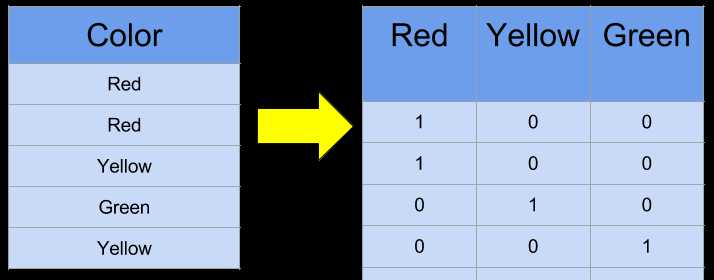 现在咱们来解释一下,首先先计算出一个category column中一共有多少个categories,然后有多少category就创建多少个columns,每一个category对应一个column,最后在相对应的位置填充1,其他则填充0。故而新创建的dataframe中,每一行只有一个1 其他都是0。这也是one-hot encoding这个名字的来历。那咱们来看看one hot encoding的代码实现吧
现在咱们来解释一下,首先先计算出一个category column中一共有多少个categories,然后有多少category就创建多少个columns,每一个category对应一个column,最后在相对应的位置填充1,其他则填充0。故而新创建的dataframe中,每一行只有一个1 其他都是0。这也是one-hot encoding这个名字的来历。那咱们来看看one hot encoding的代码实现吧
from sklearn.preprocessing import OneHotEncoder one_hot_encoder = OneHotEncoder(handle_unknown=‘ignore‘, sparse=False) X_train_result_one_hot = pd.DataFrame(one_hot_encoder.fit_transform(X_train_result[object_cols]))
和之前的label encoding一样,它也需要引用sklearn这个库,但是它是先实例化一个OneHotEncoder对象,然后用这个encoder一次性的应用于多个categorical columns, 而不像label encoding那样要一个column一个column的调用。one hot encoding是categorical data encoding中最常用的技术了,但是在有些情况下也不是很适用,例如:如果一个categorical column的categories太多的话,例如1000个,10000个等等,那么它就不适用于one hot encoding了,因为有1000个categories,就会产生1000个columns,产生的数据就太大了,而且很容易会产生overfitting的情况。
Count encoding
这也是一种简单而且高效的encoding方法,它是先计算一个categorical column中的每一个category出现的次数,然后就将这些category用次数来代替,同一个category被代替后,数值是一样的,有点和series.values_countt()有点类似,大家满满体会一下哈。这种方式和label encoding一样的简单,而且Python也帮助咱们处理好了细节部分,咱们可以通过下面的方式直接调用它的接口进行计算
import category_encoders as ce count_encoder = ce.CountEncoder() categorical_data_ce = count_encoder.fit_transform(ks[categorical_cols])
从上面的代码,咱们可以看出来,它也是encoder直接作用于多个categorical columns。
Target encoding Target encoding是根据target来计算category的,然后来替代的。那么它的具体流程是什么呢? 其实呢它是很简单的,就是先看每一个category对应的target值,然后计算相对应的target的平均数,最后用这个平均数来代替每一个category。其实就是这么的so easy。老规矩,咱们先看看如何实现的
import category_encoders as ce target_encoder = ce.TargetEncoder(cols=categorical_cols) target_encoder.fit_transform(train[categorical_cols], train.outcome)
从上面咱们可以看出,整体的步骤和count encoding很相似。但是这种方法也有一个致命的弱点,那就是这里的encoding太过于依赖target了,有很大的可能会有data leakage的风险,target encoding与target有很强的correlation,就有很强的data leakage的风险。所以大家在选择target encoding的时候一定要仔细考虑分析数据后在选择。
总结:最后国际惯例咱们先来总结一下feature engineering的第一部分,就是category data和missing value的处理。上面的一些方法是最简单常用的一些方法了,大家一定要熟悉理解应用,这里也设计到一些库的使用,我会在后面详细叫大家怎么用。missing value常用的处理方式是:1. dropping
2. Imputation
3. Extension to Imputation
然后category data的处理主要是下面的5中方式,这里大家一定要理解
1. Dropping
2. Label encoding
3. one hot encoding (最常用)
4. Count encoding
5. Target encoding (risk of data leakage)
机器学习-特征工程-Missing value和Category encoding
标签:nan array clu 除了 依赖 来历 参数设置 使用 ica
原文地址:https://www.cnblogs.com/tangxiaobo199181/p/12203808.html