标签:nbsp either tput 必须 大数 全连接 没有 compress use
SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点;
它表示连接到 spark,在进行 spark 操作之前必须先创建一个 SparkContext 的实例,并且只能创建一个;
利用 SparkContext 实例创建的对象都是 RDD,这是相对于 SparkSession 说的,因为 它创建的对象都是 DataFrame;

class SparkContext(__builtin__.object):
def __init__(self, master=None, appName=None, sparkHome=None, pyFiles=None, environment=None, batchSize=0, serializer=PickleSerializer(), conf=None, gateway=None, jsc=None, profiler_cls=<cl
ass ‘pyspark.profiler.BasicProfiler‘>)
‘‘‘Create a new SparkContext. At least the master and app name should be set,
| either through the named parameters here or through C{conf}.
|
| :param master: Cluster URL to connect to
| (e.g. mesos://host:port, spark://host:port, local[4]). local 表示本地运行,4 表示使用4个 cpu核
| :param appName: A name for your job, to display on the cluster web UI.
| :param sparkHome: Location where Spark is installed on cluster nodes.
| :param pyFiles: Collection of .zip or .py files to send to the cluster
| and add to PYTHONPATH. These can be paths on the local file
| system or HDFS, HTTP, HTTPS, or FTP URLs.
| :param environment: A dictionary of environment variables to set on
| worker nodes.
| :param batchSize: The number of Python objects represented as a single
| Java object. Set 1 to disable batching, 0 to automatically choose
| the batch size based on object sizes, or -1 to use an unlimited
| batch size
| :param serializer: The serializer for RDDs.
| :param conf: A L{SparkConf} object setting Spark properties.
| :param gateway: Use an existing gateway and JVM, otherwise a new JVM
| will be instantiated.
| :param jsc: The JavaSparkContext instance (optional).
| :param profiler_cls: A class of custom Profiler used to do profiling
| (default is pyspark.profiler.BasicProfiler).
|
|
| >>> from pyspark.context import SparkContext
| >>> sc = SparkContext(‘local‘, ‘test‘)
|
| >>> sc2 = SparkContext(‘local‘, ‘test2‘) # doctest: +IGNORE_EXCEPTION_DETAIL
| Traceback (most recent call last):
| ...
| ValueError:...‘‘‘
示例代码
from pyspark import SparkContext, SparkConf
### method 1
conf = SparkConf().setAppName(‘myapp1‘).setMaster(‘local[4]‘) # 设定 appname 和 master
sc = SparkContext(conf=conf)
## method 2
sc = SparkContext("spark://hadoop10:7077")
spark 最重要的一个概念叫 RDD,Resilient Distributed Dataset,弹性分布式数据集
spark 是以 RDD 概念为中心运行的,RDD 是一个容错的、可以被并行操作的元素集合。
创建 RDD 有三种方式:
1. 在驱动程序中并行化一个已经存在的集合 【内存中的数据】
2. 从外部存储系统引入数据,生成 RDD 【外部存储介质中的数据,注意 spark 本身没有存储功能】
// 这个存储系统可以是一个共享文件系统,如 hdfs、hbase
3. 从一种 RDD 转换成 另一种 RDD
详见我的博客 RDD 认知
RDD 的操作有两种方式:转换 和 行动,而且 转换 是 惰性的
可以根据 是否有返回 判断是哪个操作,行动 有返回值,转换无返回值
详见官网 RDD
RDD 的操作也叫 RDD 算子
惰性,无返回值
map(func[, preservesPartitioning=False]):把一个序列中的元素逐个送入 map,经 func 处理后,返回一个新的 序列
rdd = sc.parallelize([2, 3, 4]) rdd.map(lambda x: x + 1).collect() # [3, 4, 5]
filter(func):类似 map,func 是个过滤函数
rdd = sc.parallelize([2, 3, 4]) rdd.map(lambda x: x > 3).collect() # [False, False, True]
flatMap(func[, preservesPartitioning=False]):也类似 map,只是 它会把 每次经过 func 处理的结果进行 合并,输入和输出的 list 长度可能不同
rdd = sc.parallelize([2, 3, 4]) rdd.flatMap(lambda x: range(1, x)).collect() # [1, 1, 2, 1, 2, 3] # range(1, 2): 1 # range(1, 3): 1, 2 # range(1, 4): 1, 2, 3 ### vs map rdd.map(lambda x: range(1, x)).collect() # [[1], [1, 2], [1, 2, 3]]
mapPartitions(func [, preservesPartitioning=False]) :map的一个变种,map 是把序列的单个元素送入 func ,而 mapPartitions 是把 序列分区后 每个 分区 整体送入 func
rdd = sc.parallelize([1,2,3,4,5], 3) # 分 3 个区 def f(iterator): yield sum(iterator) # 必须是生成器,即 yield,不能 return rdd.mapPartitions(f).collect() # [1, 5, 9]
mapPartitionsWithIndex(func [, preservesPartitioning=False]) :func 有两个参数,分片的序号 和 迭代器,返回 分片序号,也必须是 迭代器
rdd = sc.parallelize(range(15), 13) # 分 13 个区 def f(splitIndex, iterator): yield splitIndex rdd.mapPartitionsWithIndex(f).collect() # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
cartesian(otherDataset):利用两个 序列 生成 笛卡尔內积 的数据集
x = sc.parallelize([1,2,3]) y = sc.parallelize([4,5]) x.cartesian(y).collect() # [(1, 4), (1, 5), (2, 4), (2, 5), (3, 4), (3, 5)]
groupBy(self, f, numPartitions=None, partitionFunc=portable_hash):输入一个 func,每个元素都用经过 func 处理,并对处理后的结果自动分组
## 条件是分组依据,条件不影响最后的输出格式,输出格式仍和原数据相同
## 如 原来是 [1, 2],经过分组后分到了 第 1 组,输出是 [1, [1, 2]], [1, 2] 完全保留
# 这个例子相当于求 奇偶数
rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
result = rdd.groupBy(lambda x: x % 2).collect() # [(0, <pyspark.resultiterable.ResultIterable object at 0x7f2f76096890>),
# (1, <pyspark.resultiterable.ResultIterable object at 0x7f2f760965d0>)]
# 解析迭代器并排序
sorted([(x, sorted(y)) for (x, y) in result]) # [(0, [2, 8]), (1, [1, 1, 3, 5])]
keyBy(self, f):利于 func 为 rdd 中每个元素设置一个 key
x = sc.parallelize(range(0,3)).keyBy(lambda x: x*x).collect() # [(0, 0), (1, 1), (4, 2)]
sortBy(self, keyfunc, ascending=True, numPartitions=None):根据指定函数进行排序
tmp = [(‘a‘, 1), (‘b‘, 2), (‘1‘, 3), (‘d‘, 4), (‘2‘, 5)] sc.parallelize(tmp).sortBy(lambda x: x[0]).collect() # [(‘1‘, 3), (‘2‘, 5), (‘a‘, 1), (‘b‘, 2), (‘d‘, 4)] sc.parallelize(tmp).sortBy(lambda x: x[1]).collect() # [(‘a‘, 1), (‘b‘, 2), (‘1‘, 3), (‘d‘, 4), (‘2‘, 5)]
cogroup(self, other, numPartitions=None):把 kv 对按 k 进行收集
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
[(x, tuple(map(list, y))) for x, y in # sorted(list(x.cogroup(y).collect()))]
[(‘a‘, ([1], [2])), (‘b‘, ([4], []))]
以下方法只适用 key-value 数据
keys(self),values(self)
m = sc.parallelize([(1, 2), (3, 4)]).keys() m.collect() # [1, 3]
mapValues(func):根据 func 处理 value
rdd = sc.parallelize([(1, [1,2,3]), (3, [‘a‘, ‘b‘])]) rdd.mapValues(len).collect() # [(1, 3), (3, 2)] 计算 value 的长度
reduceByKey(func [, numPartitions=None, partitionFunc=<function portable_hash at 0x7fa664f3cb90>]):针对 k-v 对的处理方法,把 key 相同的 value 进行 reduce,然后重新组成 key-reduce 对
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
def f(x, y): return x + y
rdd.reduceByKey(f).collect() # [(‘a‘, 2), (‘b‘, 1)]
groupByKey(self, numPartitions=None, partitionFunc=portable_hash):根据 key 进行分组
rdd.groupByKey().collect() # [(‘a‘, <pyspark.resultiterable.ResultIterable object at 0x7f16e3c0bd90>), (‘b‘, <pyspark.resultiterable.ResultIterable object at 0x7f16e3c0bcd0>)] sorted(rdd.groupByKey().mapValues(len).collect()) # [(‘a‘, 2), (‘b‘, 1)] sorted(rdd.groupByKey().mapValues(list).collect()) # [(‘a‘, [1, 1]), (‘b‘, [1])]
sortByKey([ascending=True, numPartitions=None, keyfunc=<function <lambda> at 0x7fa665048c80>]):根据 key 进行排序,默认升序,numPartitions 代表分区数,keyfunc 是处理 key 的,在 排序过程中对 key 进行处理
tmp = [(‘a‘, 4), (‘b‘, 3), (‘c‘, 2), (‘D‘, 1)] sc.parallelize(tmp).sortByKey(True, 1).collect() # 升序[(‘D‘, 1), (‘a‘, 4), (‘b‘, 3), (‘c‘, 2)] 1代表分区数 sc.parallelize(tmp).sortByKey(True, 2, keyfunc=lambda k:k.lower()).collect() # 升序[(‘a‘, 4), (‘b‘, 3), (‘c‘, 2), (‘D‘, 1)] D跑到后面了 sc.parallelize(tmp).sortByKey(False, 2, keyfunc=lambda k:k.lower()).collect()# 降序[(‘D‘, 1), (‘c‘, 2), (‘b‘, 3), (‘a‘, 4)]
keyfunc 只在 排序过程中起作用,在输出时 keyfunc 不起作用
join(otherDataset [, numPartitions=None]):将 两个 k-v RDD 中 共有的 key 的 value 交叉组合
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("a", 3)])
x.join(y).collect() # [(‘a‘, (1, 2)), (‘a‘, (1, 3))]
join 是内连接,也就是共有的 key 进行组合;
还有 leftOuterJoin 左连接,rightOuterJoin 右连接,fullOuterJoin 全连接
groupWith(other, *others):把多个 RDD 的 key 进行分组;输出 (key,迭代器)
分组后的数据是有顺序的,每个 key 对应的 value 是按 原本 RDD 的顺序的,如果原本 RDD 没有这个 key,留空
w = sc.parallelize([("a", 5), ("b", 6)])
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
z = sc.parallelize([("b", 42)])
w.groupWith(x, y, z).collect()
[(x, tuple(map(list, y))) for x, y in list(w.groupWith(x, y, z).collect())] # [(‘a‘, ([5], [1], [2], [])), (‘b‘, ([6], [4], [], [42]))]
有返回值
count:返回 RDD 中元素个数
first:返回 RDD 中第一个元素
max. min.sum:不解释
take(n):返回 RDD 中 前 n 个元素
collect:返回 RDD 中的数据
要注意的是,collect 相当于把 worker 的数据转移给驱动程序来显示,如果数据量过大,可能导致驱动程序崩溃
takeOrdered(n [, key=None]):对 RDD 先进行排序,然后取排序后的 前 n 个数据,key 表示先经过 keyfunc 处理后再进行排序,最终返回的还是原数据
sc.parallelize([9,7,3,2,6,4]).takeOrdered(3) # [2, 3, 4] sc.parallelize([9,7,3,2,6,4]).takeOrdered(3, key=lambda x: -x) # [9, 7, 6] ## 过程如下 # 9, 7, 3, 2, 6, 4 ## 原数据 # -9, -7, -3, -2, -6, -4 ## 经过 keyfunc 处理后的数据 # -9, -7, -6, -4, -3, -2 ## 对处理后的数据升序排序 # -9, -7, -6 ## 取前3个 # 9, 7, 6 ## 对应到原数据
也就是说,keyfunc 只在排序时起作用,在输出时不起作用
foreach(func):运行 func 函数 并行处理 RDD 的所有元素
它与 map 的区别在于一个是 转换算子,一个是行动算子 【曾经面试被问过这个问题,从功能上讲两个函数好像一样的,当时没答上,心碎】
sc.parallelize([1, 2, 3, 4, 5]).foreach(print) # 并行打印,不按顺序输出 # 1 # 2 # 4 # 5 # 3
reduce(func):把 RDD 中前两个元素送入 func,得到一个 value,把这个 value 和 下一个元素 送入 func,直至最后一个元素
sc.parallelize([1,2,3,4,5]).reduce(lambda x, y: x + y) # 15 求和
fold:与 reduce 类似,fold 是有一个 基数,然后 把每个元素 和 基数 送入 func,然后替换该基数,循环,直到最后一个元素
x = sc.parallelize([1,2,3]) neutral_zero_value = 0 # 0 for sum, 1 for multiplication y = x.fold(neutral_zero_value, lambda obj, accumulated: accumulated + obj) # computes cumulative sum print(x.collect()) # [1,2,3] print(y) # 6
aggregate:对每个分区进行聚合,然后聚合每个分区的聚合结果,详见我的博客 aggregate
countByValue:统计相同元素的个数
sc.parallelize([1,2,3,1,2,5,3,2,3,2]).countByValue().items() # [(1, 2), (2, 4), (3, 3), (5, 1)] # 输入 k-v 不按 value 统计,按 k-v 统计 sc.parallelize([(‘a‘, 1), (‘b‘, 1)]).countByValue().items() # [((‘a‘, 1), 1), ((‘b‘, 1), 1)]
saveAsTextFile(path [, compressionCodecClass=None]):把 RDD 存储到文件系统中
counts.saveAsTextFile(‘/usr/lib/spark/out‘)
输入必须是 路径,且该路径不能事先存在
以下方法只适用 key-value 数据
countByKey:统计相同 key 的个数,返回 key-count
sc.parallelize([("a",1), ("b",1), ("a", 3)]).countByKey() # defaultdict(<type ‘int‘>, {‘a‘: 2, ‘b‘: 1})
dictdata= sc.parallelize([("a",1), ("b",1), ("a", 3)]).countByKey()
dictdata.items() # [(‘a‘, 2), (‘b‘, 1)]
lookup(self, key):输入 key,返回对应的所有 value
rdd = sc.parallelize([(‘a‘, 1), (‘b‘,3), (‘a‘, 5)]) rdd.lookup(‘a‘) # [1, 5]
把 RDD 缓存到 内存中, 惰性执行
distFile = sc.textFile(‘README.md‘) m = distFile.map(lambda x: len(x)) # map 是 转换 操作,并不立即执行 m.cache() # 把 map 的输出缓存到内存中,其实 cache 就是 执行 操作 # 或者 m.persist()
缓存除了存储到内存中,还有一个非常重要的作用,复用以提高效率;
缓存的 RDD 不仅可以直接拿来转换成新的 RDD,还可以多次利用;
我们知道 RDD 是有血缘关系的,即一个 RDD 由另一个 RDD 转换得来,而这种关系可能是多层的;
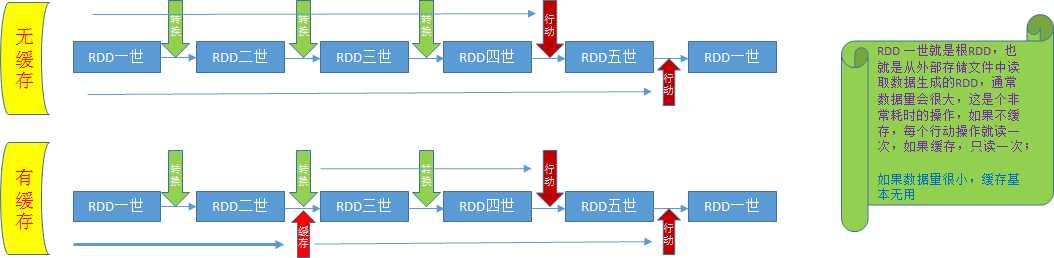
如果一个 RDD 缓存了,spark 会执行到目前为止所有转换操作,并为生成的 RDD 创建一个检查点,
但是由于 缓存 是惰性操作,缓存只会在第一次 行动 操作后创建,且第一次 行动 操作不受益,第二次三次直接调用缓存才受益;
缓存适合多次使用的数据,只用一次的无需缓存;
缓存适合大数据,小数据无需缓存
persist(self, storageLevel=StorageLevel.MEMORY_ONLY):这个方法加入了 存储等级,可以把 RDD 缓存在内存或者磁盘上,参数可选,如果没有,等于 cache,存于内存中
参数取值: MEMORY_ONLY、DISK_ONLY、MEMORY_AND_DISK 等
RDD 缓存可容错,即有备份的;
保存到文件等存储介质中,行动操作
saveAsNewAPIHadoopDataset(self, conf, keyConverter=None, valueConverter=None)
saveAsNewAPIHadoopFile(self, path, outputFormatClass, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, conf=None)
saveAsHadoopDataset(self, conf, keyConverter=None, valueConverter=None)
saveAsHadoopFile(self, path, outputFormatClass, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, conf=None, compressionCodecClass=None)
saveAsSequenceFile(self, path, compressionCodecClass=None)
saveAsPickleFile(self, path, batchSize=10)
saveAsTextFile(self, path, compressionCodecClass=None)
参考资料:
https://www.cnblogs.com/yangzhang-home/p/6056133.html 快速入门
https://blog.csdn.net/kl28978113/article/details/80361452 较全教程
http://spark.apache.org/docs/latest/ spark 2.4.4 官网
http://spark.apache.org/docs/latest/api/python/index.html spark 2.4.4 python API
https://www.cnblogs.com/Vito2008/p/5216324.html
https://blog.csdn.net/proplume/article/details/79798289
https://www.iteblog.com/archives/1396.html#aggregate RDD 操作 API
https://www.cnblogs.com/yxpblog/p/5269314.html RDD 操作 API
spark教程(四)-SparkContext 和 RDD 算子
标签:nbsp either tput 必须 大数 全连接 没有 compress use
原文地址:https://www.cnblogs.com/liuys635/p/12208457.html