标签:def 素数 网络io atomic push 基于 开始 翻译 怎么
【前言】
队列是众多数据结构中最常见的一种之一。曾经有人和我说过这么一句话,叫做“程序等于数据结构+算法”。因此在设计模块、写代码时,队列常常作为一个很常见的结构出现在模块设计中。DPDK不仅是一个加速网络IO的框架,其内部还提供众多的功能组件,rte_ring就是DPDK内部提供的一种无锁队列,本篇文章将从使用的角度出发阐述DPDK的ring怎么用?在怎么用的角度上再来阐述ring无锁的实现,最后将探讨实现无锁队列的关键以及在不通平台上如何实现,本文将会探讨x86平台下无锁队列的实现。
权当抛砖引玉,有问题请留言指正,感激不尽。
【场景】
程序等于数据结构+算法。但是场景仍然是最重要的,因为场景取决于我们到底“用不用”某个技术或者是某个组件,亦或是某种数据结构。
做数据面的都应该见过如图1的这种线程模型。
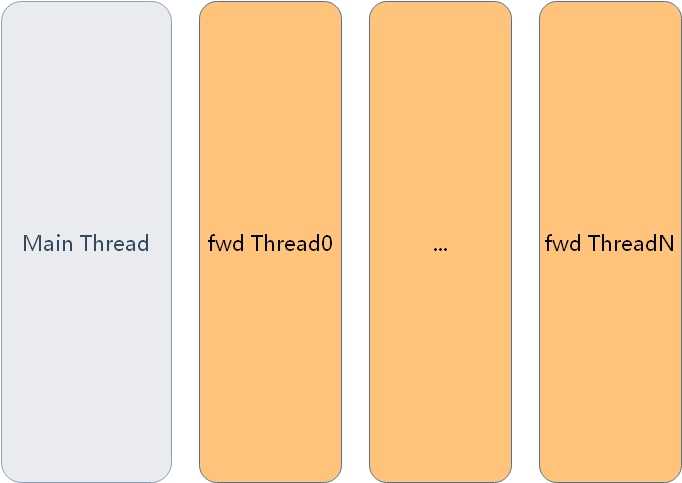
图1.常见的数据面线程模型
图1是一种常见的数据面模型,比如linux基金会的FD.IO(VPP)采用的就是这种线程模型,这种线程模型下分工明确:
那么现在有一种需求,fwd线程需要将一些信息上传至控制面进程那么最好的做法是什么呢?这里通常有很多种实现方式,但是均和本篇文章的主要讨论对象无关,因此不多做讨论。
其中一种常见的手段就是通过ring,还有一种场景就是DPDK的multiprocess场景,也同样可以通过ring来讲数据包分发到其他process中。如图2这种情况
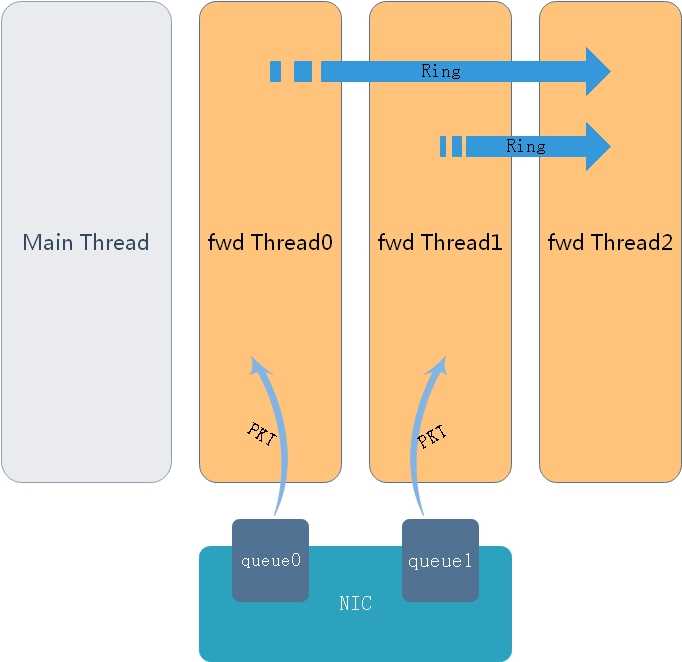
图2.另外一种常见的场景
这种场景是典型的“僧多肉少”型,就是“processer的数量多于rx队列数量”,那么这种场景下注定有一些processer是无法接管网卡队列的,但是我还想发挥这些processer的处理能力,怎么办?
那么常见的方案就是在接管到rx队列的processer将数据包从rx queue上收上来后,计算数据包的rss,然后将数据包“尽量均匀”的通过ring来发送到那些没有分配到rx queue的fwd thread上。其实也不光是云计算的数据面场景,在很多场景下我们都需要用到队列,因为队列是一个再基础不过的数据结构,因此我们拿DPDK的ring出发,最终阐述无锁队列的常见实现方式。
【DPDK ring 从使用出发】
我个人觉得任何一种技术,出发点肯定是“先用再分析”,说白了就是对一种技术或对某一个模块的直观印象都不是直接分析代码就能得到的,都是“先跑起来,玩一下,看看情况”得到的第一印象,因此这里还是会先从使用的角度出发,先会用再分析实现。如果有用过DPDK Ring,那么本节可以直接跳过,直接看后面的分析章节。
DPDK的ring代码主要以lib的形式集成在DPDK源代码中,具体代码位置为:DPDK根目录/lib/librte_ring目录中。以下代码均已DPDK 19.11版本作为参照(其他版本基本都是大同小异)。
先介绍一下主要的函数接口:
struct rte_ring * rte_ring_create(const char *name, unsigned count, int socket_id, unsigned flags) //创建dpdk的rte_ring void rte_ring_free(struct rte_ring *r) //释放已经创建的dpdk的rte_ring struct rte_ring * rte_ring_lookup(const char *name) //去寻找一个已经创建好的dpdk的rte_ring static __rte_always_inline unsigned int __rte_ring_do_enqueue(struct rte_ring *r, void * const *obj_table, unsigned int n, enum rte_ring_queue_behavior behavior, unsigned int is_sp, unsigned int *free_space) //此函数为内部方法,所有入队函数都是此函数的上层封装 static __rte_always_inline unsigned int __rte_ring_do_dequeue(struct rte_ring *r, void **obj_table, unsigned int n, enum rte_ring_queue_behavior behavior, unsigned int is_sc, unsigned int *available) //此函数为内部方法,所有出队函数都是此函数的上层封装 static __rte_always_inline unsigned int rte_ring_mp_enqueue_bulk(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) //此函数为批量入队函数,为多生产者安全(multi producer) static __rte_always_inline unsigned int rte_ring_sp_enqueue_bulk(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) //此函数为批量入队函数,为单生产者安全(single producer) static __rte_always_inline unsigned int rte_ring_enqueue_bulk(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) //此函数为批量入队函数,具体安全性质取决于创建队列时的标志(flags) static __rte_always_inline unsigned int rte_ring_mc_dequeue_bulk(struct rte_ring *r, void **obj_table, unsigned int n, unsigned int *available) //此函数为批量出队函数,为多消费者安全(multi consumer) static __rte_always_inline unsigned int rte_ring_sc_dequeue_bulk(struct rte_ring *r, void **obj_table, unsigned int n, unsigned int *available) //此函数为批量出队函数,为单消费者安全(single consumer) static __rte_always_inline unsigned int rte_ring_dequeue_bulk(struct rte_ring *r, void **obj_table, unsigned int n, unsigned int *available) //此函数为批量出队函数,具体安全性质取决于创建队列时的标志(flags) static inline unsigned rte_ring_count(const struct rte_ring *r) //此函数用于查看队列中元素的数量
可以看到上述函数列表(只是代表性的一部分)基本分为三类接口
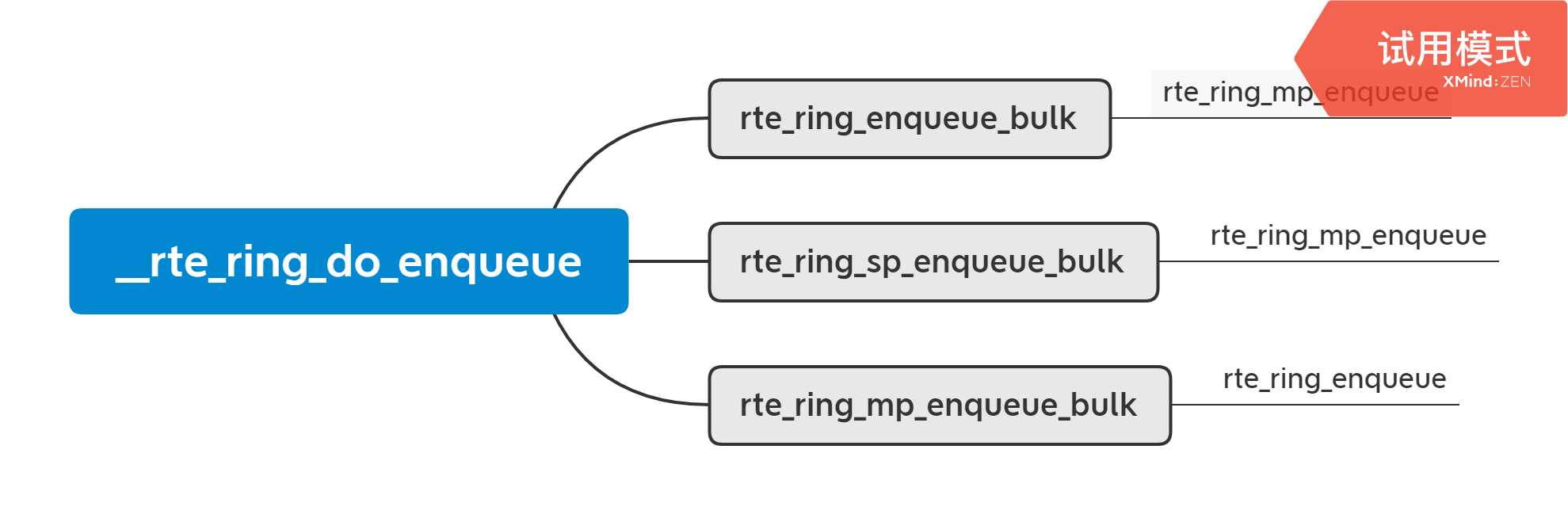
图3.出队的操作函数
实际上如果让我们自己设计一个队列,基本上也逃离不出去这些接口,并且根据图3可以看出,所有的出队函数基本都是基于__rte_ring_do_enqueue的封装而已。
那么实际使用起来的步骤可以基本可以为以下流程图描述
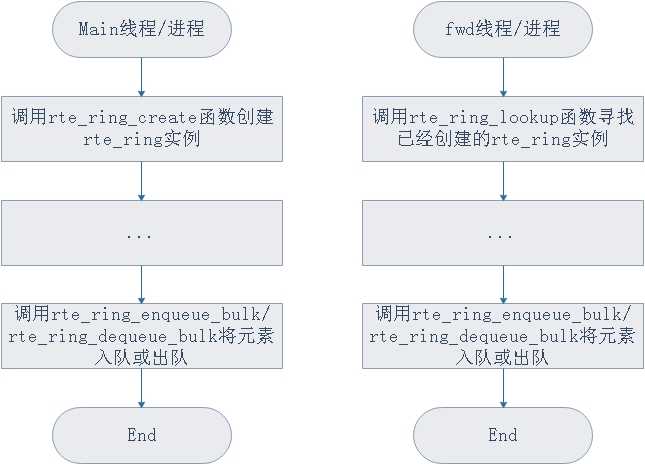
图3.dpdk ring常见的使用流程
使用流程还是非常简单的,因为队列本身作为一个常见的数据结构使用起来并不复杂,具体使用的例子可以看dpdk的example/multiprocess/中的例子。
但是使用的时候有几个地方需要注意:
可以看到dpdk的rte_ring使用上还是蛮简单的,因此接下来就从源码出发解析一下dpdk的rte_ring的无锁实现。
【DPDK ring 的无锁实现】
先说结论:
无锁的实现依赖于一个汇编指令: cmpxchg
翻译过来就是compare and change
我们先看看dpdk的ring是如何实现无锁的,我们拿__rte_ring_do_enqueue和__rte_ring_do_dequeue这两个函数开刀,这两个函数分别是入队和出队的底层实现函数,其余所有的入队和出队函数都是基于这两个函数进行了上层封装而已。
先想一下,在多生产者和多消费者场景下,分别要应付哪些问题?
我们先看第一个问题和第二个问题是如何实现的,但是在分析实际函数的实现之前,我们要先分析一下rte_ring。
struct rte_ring { char name[RTE_MEMZONE_NAMESIZE] __rte_cache_aligned; // ring的名称,lookup的时候就是根据名称进行查找对应的ring int flags; // 标记,用来描述队列是单/多生产者还是单/多消费者安全 const struct rte_memzone *memzone; // 所属的memzone,memzone是dpdk内存管理底层的数据结构 uint32_t size; // 队列长,为2^n。如果flags为RING_F_EXACT_SZ // 队列size为初始化时队列长度的向上取2的n次幂,例如如果为 // 7,那么向上取最近的2^n幂的数为8.如果flags不为 // RING_F_EXACT_SZ,那么初始化队列的时候队列长必须为2^n幂 uint32_t mask; // 掩码,为队列长 - 1,用来计算位置的时候取余用 uint32_t capacity; // 队列容量,一般不等于队列长度,把队列容量理解为实际可以 // 使用的元素个数即可。例如初始化时count为7并且指定标志为 // RING_F_EXACT_SZ,那么count最后为8,但是capacity为7,因为 // 8是向上取2^n幂取出来的,实际上仍然是创建时所需的个数,8. char pad0 __rte_cache_aligned; // 填充,考虑到性能,要使用填充法保证cache line struct rte_ring_headtail prod __rte_cache_aligned; // 生产者位置,里面有一个生产者头,即prod.head,还有一个生 // 产者尾,即prod.tail。prod.head代表着下一次生产时的起始 // 生产位置。prod.tail代表消费者可以消费的位置界限,到达 // prod.tail后就无法继续消费,通常情况下生产完成后, // prod.tail = prod.head,意味着刚生产的元素皆可以被消费 char pad1 __rte_cache_aligned; struct rte_ring_headtail cons __rte_cache_aligned; // 消费者位置,里面有一个消费者头,即cons.head,还有一个消 // 费者尾,即cons.tail。cons.head代表着下一次消费时的起始 // 消费位置。cons.tail代表生产者可以生产的位置界限,到达 // cons.tail后就无法继续生产,通常情况下消费完成后, // cons.tail = cons.head,意味着刚消费的位置皆可以被生产 char pad2 __rte_cache_aligned; /**< empty cache line */ };
上述数据结构为rte_ring的数据结构,rte_ring就代表着一条ring,是ring的抽象。其中重要的是两个地方,一个是prod,一个是cons,前者代表生产者,后者代表消费者,里面分别有两个标记,关于标记的用途已经在上述代码的注释中阐述。
但是还有一点,ring中存放的数据在哪?dpdk的ring中存放的数据位置可以见图4.
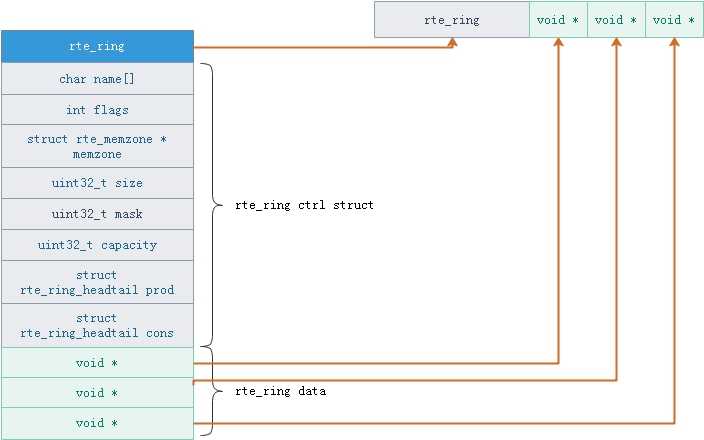
图4.dpdk ring的内存分布图
可以看到,rte_ring的data中存放的是指针(就因为是指针才能利用cmpxchg实现“无锁”),并且data分布在struct rte_ring紧邻的空间中(图中青色的内存块)。在分析实际的函数前,再看几个流程图,结合rte_ring中的数据结构来看,理解会更加深刻(当然这部分的内容在《深入浅出dpdk》一书中的4.4.2节也有描述)。
1.入队操作,以单生产者单消费者(多生产者和多消费者基本差不多)为例。初始状态为图5所示。初始状态中队列中有4个元素,分别是obj1、obj2、obj3、obj4.
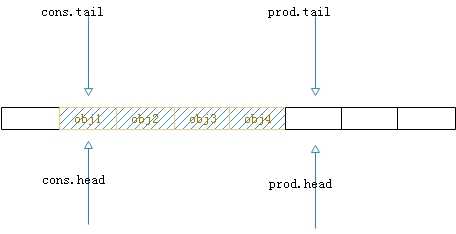
图5.初始状态
2.第一步,新元素入队,先偏移prod.head到新的生产者头位置,例如现在位置为5,若生产元素的个数为2,那么新位置即为index = 7,但是由于涉及到多生产者,其中多生产者无锁的奥秘就在这一步,因此先占位置,如图6。
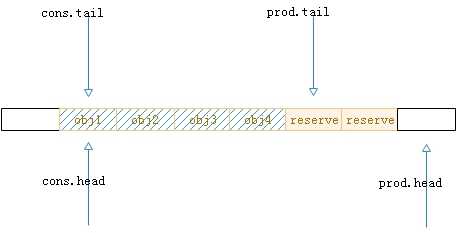
图6.入队的第一步操作
3.第二步,元素写入。
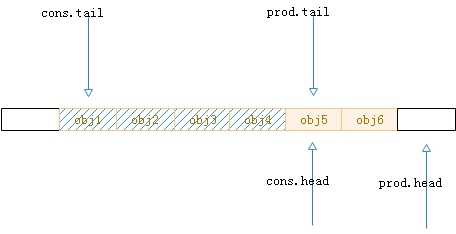
图7.入队的第二步操作
4.第三步,更新生产者的尾指针,也就是prod.tail,因为第二步只是将元素写入而已,涉及生产-消费的流程,还要告诉消费者“可以消费”,prod.tail的作用便是如此,所以需要更新,但是假设当前消费者开始消费,那么流程便如图7所示,消费者的头标记只能到达生产者尾标记的位置。
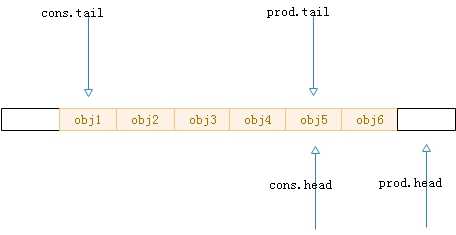
图8.出队的第一步操作
5.第四步,消费者开始消费元素,此时生产者的tail标记开始更新。
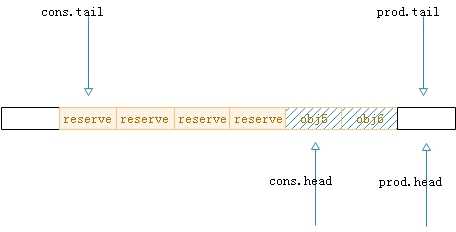
图9.出队的第二步操作
6.第五步,与生产者相同,消费者消费数据后,被消费后的空间不能立即用于生产,还需要更新tail标记才可以(cons.tail)
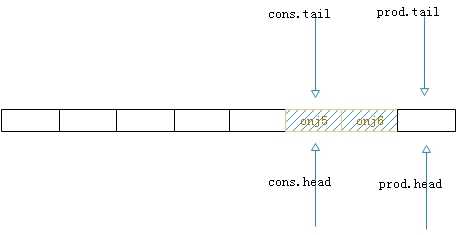
图10.生产-消费后的最终状态
接下来,理解了上述生产-消费的流程后,既可以分析具体的函数了,接下来将站在生产者的视角进行分析代码实现(消费者与生产者几乎相同),拿生产者的入队函数__rte_ring_do_enqueue来分析。
static __rte_always_inline unsigned int __rte_ring_do_enqueue(struct rte_ring *r, void * const *obj_table, unsigned int n, enum rte_ring_queue_behavior behavior, unsigned int is_sp, unsigned int *free_space) { uint32_t prod_head, prod_next; uint32_t free_entries; //第一步,先偏移头指针,抢占生产位置 n = __rte_ring_move_prod_head(r, is_sp, n, behavior, &prod_head, &prod_next, &free_entries); if (n == 0) goto end; //第二步,塞数据 ENQUEUE_PTRS(r, &r[1], prod_head, obj_table, n, void *); //第三部,更新尾指针,让消费者可以消费 update_tail(&r->prod, prod_head, prod_next, is_sp, 1); end: if (free_space != NULL) *free_space = free_entries - n; return n; }
上述代码是一个典型的“三步走”。
那么很显然,第一步就是对付第一个问题的,即在多生产者下如何让生产者可以顺利生产并且多个生产者之间不会互相冲突,所以需要分析一下__rte_ring_move_prod_head函数。
static __rte_always_inline unsigned int __rte_ring_move_prod_head(struct rte_ring *r, unsigned int is_sp, unsigned int n, enum rte_ring_queue_behavior behavior, uint32_t *old_head, uint32_t *new_head, uint32_t *free_entries) { const uint32_t capacity = r->capacity; unsigned int max = n; int success; do { //1.先确定生产者要生产多少个元素 n = max; //2.拿到现在生产者的head位置,也就是即将生产的位置 *old_head = r->prod.head; //内存屏障 rte_smp_rmb(); //3.计算剩余的空间 *free_entries = (capacity + r->cons.tail - *old_head); //4.比较生产的元素个数和剩余空间 if (unlikely(n > *free_entries)) n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *free_entries; if (n == 0) return 0; //5.计算生产后的新位置 *new_head = *old_head + n; if (is_sp) r->prod.head = *new_head, success = 1; else //6.如果是多生产者的话调用cpmset函数实现生产位置抢占 success = rte_atomic32_cmpset(&r->prod.head, *old_head, *new_head); } while (unlikely(success == 0)); return n; }
上述函数逻辑是一个非常简单的实现逻辑,而关键在于第6点和do while循环,cmpset函数是什么?又是如何实现的生产位置抢占呢?
1 static inline int 2 rte_atomic32_cmpset(volatile uint32_t *dst, uint32_t exp, uint32_t src) 3 { 4 uint8_t res; 5 6 asm volatile( 7 MPLOCKED 8 "cmpxchgl %[src], %[dst];" 9 "sete %[res];" 10 : [res] "=a" (res), /* output */ 11 [dst] "=m" (*dst) 12 : [src] "r" (src), /* input */ 13 "a" (exp), 14 "m" (*dst) 15 : "memory"); /* no-clobber list */ 16 return res; 17 }
上述cmpset为x86体系下的实现,可以看到,是一段GCC内联的汇编指令,这段内联的嵌入汇编指令由三个汇编指令构成,最核心的一个指令便是第8行的“cmpxchg”,这便是我们最开始说的 "无锁的实现依赖于cmpxchg指令",那么这个指令究竟是什么意思呢?
cmpxchg指令的意思就是“compare and change”,即“比较并交换”。
举个例子,如果A等于B,则将C赋值给A;如果A不等于B,则拒绝将C赋值给A。
根据这个特征我们可以知道,在多生产者场景下,最担心的事情是什么呢?最担心的事情即为“前脚刚计算好生产位置(偏移),后脚还没等写入数据,结果就被另外一个生产者把刚刚计算好的生产位置给占了,结果自己没得空间生产”,将这个场景结合刚才的cmpxchg之后怎么解决呢?
如果生产位置没有变化(A等于B),那么就将最新的生产位置(计算偏移后的生产位置)赋值给生产者指针;如果生产位置发生了变化(有其他生产者也在生产),那么就取消更新生产者指针
核心实现就是上面这句话。关于rte_atomic32_cmpset函数,下一章【x86的cas】中会详细讲解。
那么头指针偏移部分代码的流程图可以总结如下:
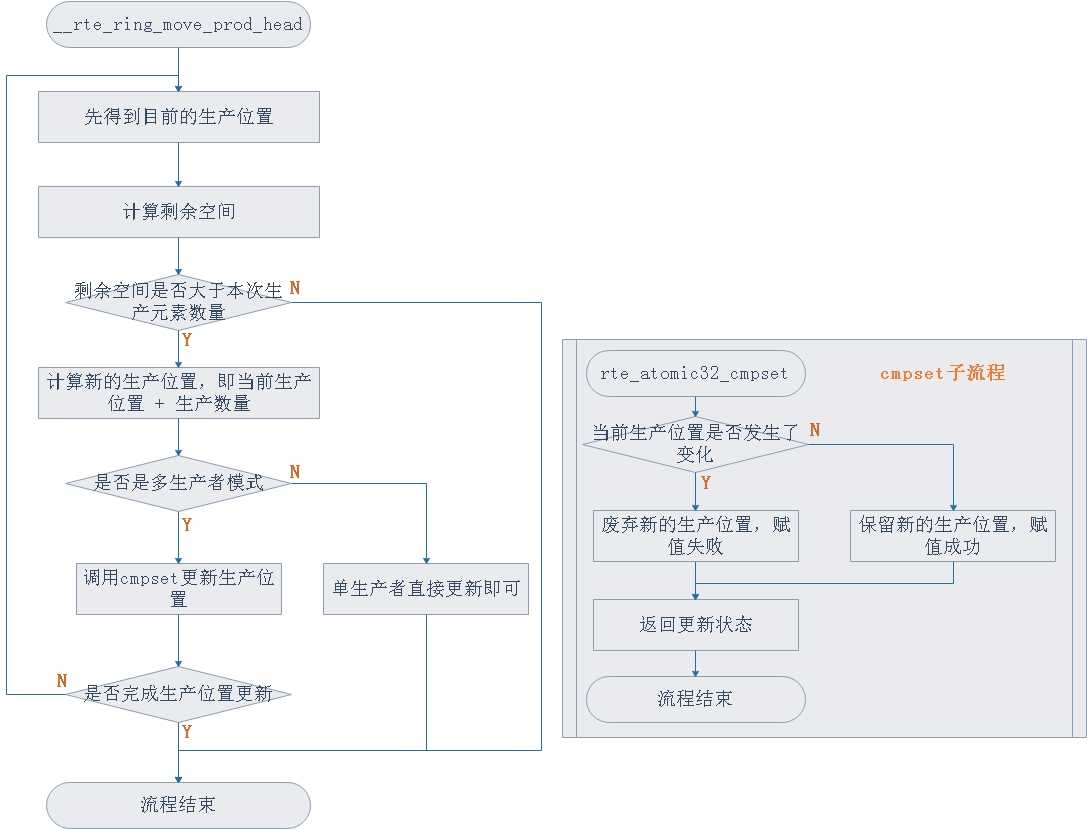
那么至此,第一个问题之“多生产者如何解决生产位置的问题得到了解决”,那么接下来就是第三个问题,“如何让消费者可以消费刚刚生产的数据?”
这个问题在“三步走”中的第三部中解决的。
static __rte_always_inline void update_tail(struct rte_ring_headtail *ht, uint32_t old_val, uint32_t new_val, uint32_t single, uint32_t enqueue) { //1.内存屏障 if (enqueue) rte_smp_wmb(); else rte_smp_rmb(); //2.如果有其他生产者生产数据,那么需要等待其将数据生产完更新tail指针后,本生产者才能更新tail指针 if (!single) while (unlikely(ht->tail != old_val)) rte_pause(); //3.更新tail指针,更新的位置为最新的生产位置,意味着刚刚生产的数据已经全部可以被消费者消费 ht->tail = new_val; }
这里面可能唯一会让人产生些许疑惑的就是step 2.这里有一个自旋锁,自旋等待"ht->tail == old_val"条件的成立,这是为什么呢?想一下这样的场景:
单生产者单消费者情况下:生产数据成功后,应该讲prod.tail指针前移至prod.head处,相当于告诉消费者队列中的数据都是可以消费的,但是如果此时是多生产者场景,由于有多个生产者,prod.tail指针可能随时发生变化,例如:
刚开始的时候,prod.head = prod.tail = 0,生产者A生产了3份数据,prod.head = 3并且prod.tail = 0,随后生产者B生产了2份数据,prod.head = 5并且prod.tail = 0,那么此时会满足“ht->tail == old_val”么?不会,ht->tail = prod.tail = 0,而old_val的值却为生产元素前的prod.head的值,也就是3.那么此时需要做的就是等待生产者A将3份数据完全生产完,并且将prod.tail更新至3,那么此时才会满足“ht->tail == old_val”。说白了就是得等别的生产者完全生产完才能生产。但是从最终结果而言,生产者A生产了3个元素,生产者B生产了2个元素,最终结果中,prod.tail = 5,也就是刚刚生产的5个元素可以全部被消费者消费。
所以从上面的“__rte_ring_do_enqueue”函数可以看出,想想所谓的无锁队列真的实现了理想的“无锁”么?
“rte_ring_do_dequeue”的函数执行流程与“__rte_ring_do_enqueue”的流程基本一致,无法后者为生产者视角,而前者为消费者视角,请读者根据上述“队列入队”的分析过程自行分析“队列出队”。
【x86的CAS】
可能有的读者在“无锁”这个概念上知道“无锁”的实现是一种"CAS"操作,那么什么才是CAS操作呢?
CAS的全程为“Compare And Swap”,意味比较并交换
“比较并交换”,这个概念和前一章中“cmpxchg”指令的含义基本一致。核心思想就是:
和预期结果比较,相同则赋值,不同则放弃
如果和预期不同,那么我会一遍一遍的去尝试,当没有人和我竞争了,和预期结果自然就会“相同”,再回到之前的内联汇编。
1 static inline int 2 rte_atomic32_cmpset(volatile uint32_t *dst, uint32_t exp, uint32_t src) 3 { 4 uint8_t res; 5 6 asm volatile( 7 MPLOCKED 8 "cmpxchgl %[src], %[dst];" 9 "sete %[res];" 10 : [res] "=a" (res), /* output */ 11 [dst] "=m" (*dst) 12 : [src] "r" (src), /* input */ 13 "a" (exp), 14 "m" (*dst) 15 : "memory"); /* no-clobber list */ 16 return res; 17 }
想读懂这个函数首先需要先了解内联汇编的正确写法和格式。当然,接下来要说的内联汇编格式为intel格式。由于涉及到内联汇编的文章有许多,在这里不会详细介绍内联汇编的格式和写法,更多的会聚焦于此函数的实现。
内联汇编的函数格式为:
1 asm ( assembler template 2 : output operands /* optional */ 3 : input operands /* optional */ 4 : list of clobbered registers /* optional */ 5 );
很简单,内联汇编由4个部分组成:
那么我们接着回到rte_atomic32_cmpset函数的实现,line 7是一个x86架构下的“lock”指令指令前缀,注意“lock”其实本质上不是一个指令,而是一个指令前缀,也就是用来修饰接下来的指令,支队接下来的指令有效力,并且修饰的指令必须是对内存有“读-改-写”三种操作的指令,就比如说cmpxchg指令就是。
#if RTE_MAX_LCORE == 1 #define MPLOCKED /**< No need to insert MP lock prefix. */ #else #define MPLOCKED "lock ; " /**< Insert MP lock prefix. */ #endif
在x86多核架构下,lock指令通常用来确保多核访问cache line是具有排他性的(相当于一把锁)。
第一个指令是cmpxchg,关于cmpxchg我们前面已经大致讲过此命令的作用。此命令的实际作用是:
比较源操作数和eax寄存器中的值,如果相同,则将目的操作数更新为源操作数,并且将标志寄存器中的ZF(zero flags)位置1;如果源操作数和eax寄存器中的值不通,则将源操作数写入eax寄存器中,并将标志寄存器中的ZF(zero flags)清0
那么对照上面的场景,一般eax寄存器中存的值都是初始值,也就是还没有计算入队偏移的初始值,由于在计算入队偏移操作时,其他生产者可能也在进行计算入队偏移,那么就会起冲突,具体体现就是生产者头指针发生变化,因此在cmpxchg指令中,再拿生产者头指针和初始值进行比较,如果相同这说明现在没有其他生产者在更新,那么源操作数(当前生产者头指针)和eax寄存器中的值(事先备份的初始值)必定相同,此时则可以安全的将目的操作数赋值至源操作数,也就是(prod.head = new_head);如果不同,这说明现在可能有其他生产者在生产导致生产者头指针发生变化(prod.head发生变化),那么此时便不能更新源操作数(prod.head)。
第二个指令是sete,这个指令就很简单了,就是单纯的将标志寄存器中的zf位的值赋值给目的操作数,也就是res。那就意味着如果cmpxchg执行交换成功,则zf位为1,那么经过sete设置后,res返回值也就是1;如果cmpxchg执行交换失败,则zf为0,那么经过sete设置后,res的返回值也就是0.
那么这个函数便是,如果cmpxchg成功,则函数返回1,如果cmpxchg失败,则函数返回0,那么根据函数的返回值,上层逻辑便知道更新生产者头指针是否成功,成功直接返回即可;不成功怎么办呢?也很简单,循环,我一次一次试(while循环),总会成功的。
可以看到,CAS操作实现无锁的本质上就是“比较”,比较什么呢?这取决于我们最担心什么?那我们最担心的是什么呢?我们最担心的无非就是
生产者的视角:我刚开始根据旧的生产者头指针 + 生产的元素数量,计算出生产后的指针位置,结果在我计算的过程中,由于有其他生产者干扰,导致旧的生产者头指针已经发生了变化,那么计算出的生产后的指针位置也是失效的。
消费者的视角:我刚开始根据旧的消费者头指针 + 消费的元素数量,计算出消费后的指针位置,结果在我计算的过程中,由于有其他消费者干扰,导致旧的消费者头指针已经发生了变化,那么计算出的消费后的指针位置也是失效的。
所以需要比较什么呢?比较是“预期值”与“实际值”,预期值是我们希望“旧的生产者头指针不会发生变化”,那么实际值便是“当前的生产者头指针位置”,那么我只需要比较两者便可以得知,是否有其他生产者干扰,只有符合预期的情况,我才可以进行接下来的操作,也就是赋值。
【后续】
【DPDK】【ring】从DPDK的ring来看x86无锁队列的实现
标签:def 素数 网络io atomic push 基于 开始 翻译 怎么
原文地址:https://www.cnblogs.com/jungle1996/p/12194243.html