标签:row src 带来 技术 union 子节点 bsp HERE clust
【1】索引覆盖
【1.1】索引覆盖的概念
在我的理解中,什么是索引覆盖?就是说,你的所有查询条件中,每个条件CBO都愿意去扫描索引来查询数据(无论是单列索引还是复合索引均可),然后根据索引扫描/查找的结果可以获取到我们要的结果集。
然后最后非聚集索引会根据不同where条件走的索引获取到叶子节点数据(也就是聚集索引键值),这个时候就获取到了 聚集索引值+本身索引列的值。
最后再拿不同where条件获取到的聚集索引值做等值比较匹配,均相等的就是我们想要的数据。这个也避免了回表去从实际存储数据的数据页去找数据。
【1.2】索引覆盖实践(MSSQL)
use master; create table test(id int,num int,num1 int); create clustered index CIX_id on test(id); create index IX_num on test(num); create index IX_num1 on test(num1); --create a test data, 10000 rows ;with temp as ( select 1 as id,5 as num,10 as num1 union all select id+1,num+5,num1+10 from temp where id<10000 ) insert into test select * from temp option(maxrecursion 0);
结果:
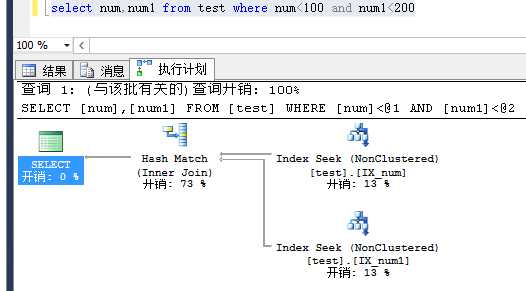
如上图,我们可以看到,并没有回表,优化器直接分别根据 num 和 num1 去读取这2列上的索引。
然后获取到 (1) 聚集索引键值+num (2)键值索引键值+num1
最后,直接对比匹配相等的聚集索引值(因为查出来的聚集索引键值并不一定保证是有序的《也可以理解成这个时候出来的聚集索引键值就是一个堆结果集》,所以这里MSSQL自动用了更优秀的匹配算法:HASH匹配,因为它是等值查询非常快的方法之一);
【1.3】索引覆盖实践(MYSQL)
【2】覆盖索引
【2.1】覆盖索引的概念
这就是我们经常说的覆盖索引和索引覆盖,大多数人并没有细细区分它们。
那到底什么叫覆盖索引呢?我的理解是,一个索引包含了所有我们要查的值。
【2.2】覆盖索引实践(MSSQL)
use master; create table test1(id int,num int,num1 int,num2 int); create clustered index CIX_id on test1(id); create index IX_num on test1(num); create index IX_num1_2 on test1(num1,num2); --create a test data, 10000 rows ;with temp as ( select 1 as id,5 as num,10 as num1, 11 as num2 union all select id+1,num+5,num1+10,num2+11 from temp where id<10000 ) insert into test1 select * from temp option(maxrecursion 0);
(1)复合索引列带来的覆盖索引
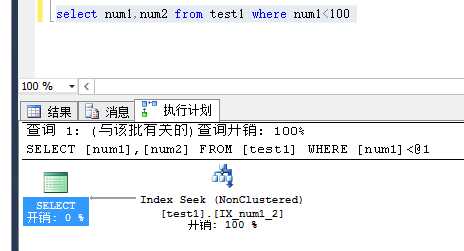
因为复合索引中已经包含了 num2的值,所以直接就可以查询出来了。
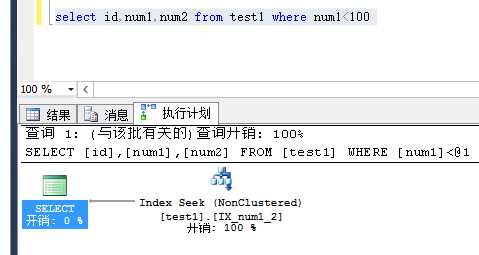
同理,因为 id 是聚集索引,已经在(num1,num2) 复合索引的叶子节点里了,所以也满足覆盖索引的特性(包含索要查询的所有数据),这里也没有回表,直接在索引查询中就搞定了。
同理单列索引、include包含,这些带来的效果都是一样的。
标签:row src 带来 技术 union 子节点 bsp HERE clust
原文地址:https://www.cnblogs.com/gered/p/12210055.html