标签:经理 style 提问 ++ enum idt lang 定时 特殊
在上一节主要介绍了单个字符的处理,现在我们已经有了对单个字符分析的能力,比如:
接下来,需要利用字符组装标记。
标记可以是一个变量名、一个符号或一个关键字。
比如代码 var x = String.fromCharCode(100); 中,一共可解析出以下标记:

为什么有些字符会组成一个标记,而有些字符又不行呢?
可以这么理解:标记里的字符一定是不能拆开的,就像“东西”这个词是一个最小的整体,如果拆成两个字,就不能表达原来的意思了。
比如代码 0.1.toString 中,包含以下标记:
前面的点紧跟数字,是小数的一部分,所以和数字一起作为一个标记。当点不紧跟数字时,也可以作独立标记使用。
代码中的字符串,不管内容有多长,都将被解析为一个字符串标记。
++ 是一个独立的加加标记,而 + + (中间差一个空格)是两个加标记。
为什么标记需要按这个规则解析?因为 ES 规范就这么规定的。在英文编程语言中,一般都是用空格来分割标记的,两个标记如果缺少空格,它们可能被组成新的标记。当然并不是随便两个字符就可以组成新标记,比如 !! 和 ! ! 都被解析成两个感叹号标记,因为根本不存在双感叹号标记。
关键字和普通的标识符都是一个单词,为什么关键字有特殊的标记类型,而其它单词统称为标识符呢?
主要为了方便后续解析,之后判断单词是否是关键字时,只需判断标记类型,而不是很麻烦地先判断是否是标识符再判断标识符的内容。
每个标记在源码中都有固定的位置,如果将源码看成字符串,那么这个标记第一个字符在字符串中的索引就是标记的开始位置,最后一个字符对应的就是结束位置。
在解析每个标记时,会跳过标记之间的空格、注释。如果把每个标记之前、上一个标记之后的空格、注释包括进来,这个标记的位置即标记的完整开始位置。一个标记的完整开始位置等同于上一个标记的结束位置。
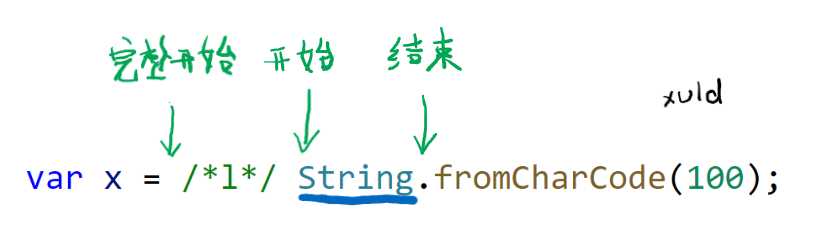
综上,任何源码都可以被解析成一串标记组成的数组,每个标记都有这些属性:
在 TS 源码中,用 SyntaxKind 枚举列出了所有标记类型:
export const enum SyntaxKind { CloseBraceToken, OpenParenToken, CloseParenToken, OpenBracketToken, // ...(略) }
同时,这些标记类型的值也有一个约定,即关键字标记都被放在一起,这样就可以很轻松地通过标记类型判断是否是关键字:
export function isKeyword(token: SyntaxKind): boolean { return SyntaxKind.FirstKeyword <= token && token <= SyntaxKind.LastKeyword; }
同理还有很多的类似判断,它们被放在了 tsc/src/compiler/utilities.ts 中。
TS 内部统一使用 SyntaxKind 存储标记类型(SyntaxKind 本质是数字,这样比较起来性能最高),为了方便报错时显示,TS 还内置了从文本内容获取标记类型和还原标记类型为文本内容的工具函数:
const textToToken = createMapFromTemplate<SyntaxKind>({ ...textToKeywordObj, "{": SyntaxKind.OpenBraceToken, // ...(略) }) const tokenStrings = makeReverseMap(textToToken); export function tokenToString(t: SyntaxKind): string | undefined { return tokenStrings[t]; } /* @internal */ export function stringToToken(s: string): SyntaxKind | undefined { return textToToken.get(s); }
一份代码中,一般会解析出上千个标记。如果将每个标记都存下来就会消耗大量的内存,而就像你读文章时,你只要盯着当前正在读的这几行字,而不需要将全文的字都记下来一样,解析代码时,也只需要知道当前正在读的标记,之前已经理解过的标记不需要再记下来。所以实践上出于性能考虑,采用扫描的方式逐个读取标记,而不是一口气将所有标记先读出来放在数组里。
什么是扫描的方式?即有一个全局变量,每调用一次扫描函数(scan()),这个变量的值就会被更新为下一个标记的信息。你可以从这个变量获取当前标记的信息,然后调用一次 scan() ,再重新从这个变量获取下一个标记的信息(当然这时候不能再读取之前的标记信息了)。
Scanner 类提供了以上所说的所有功能:
export interface Scanner { setText(text: string, start?: number, length?: number): void; // 设置当前扫描的源码 scan(): SyntaxKind; // 扫描下一个标记 getToken(): SyntaxKind; // 获取当前标记的类型 getStartPos(): number; // 获取当前标记的完整开始位置 getTokenPos(): number; // 获取当前标记的开始位置 getTextPos(): number; // 获取当前标记的结束位置 getTokenText(): string; // 获取当前标记的源码 getTokenValue(): string; // 获取当前标记的内容。如果标记是数字,获取计算后的值;如果标记是字符串,获取处理转义字符后的内容 }
如果你已经理解了 Scanner 的设计原理,那就可以回答这个问题:如何使用 Scanner 打印一个代码里的所有标记?
你可以先思考几分钟,然后看答案:
以下是可以直接在 Node 运行的代码,你可以直接断点调试看 TS 是如何完成标记解析的任务的。
const ts = require("typescript")
const scanner = ts.createScanner(ts.ScriptTarget.ESNext, true)
scanner.setText(`var x = String.fromCharCode(100);`)
while (scanner.scan() !== ts.SyntaxKind.EndOfFileToken) { // EndOfFileToken 表示结束
const tokenType = scanner.getToken() // 标记类型编码
const start = scanner.getTokenPos() // 开始位置
const end = scanner.getTextPos() // 结束位置
const tokenName = ts.tokenToString(tokenType) // 转为可读的标记名
console.log(`在 ${start}-${end} 发现了标记:${tokenName}`)
}
TS 早期是使用面向对象的类开发的,从 1.0 开始,为了适配 JS 引擎的性能,所有源码已经没有类了,全部改用函数闭包。
export function createScanner(languageVersion: ScriptTarget, skipTrivia: boolean, /**...(略) */): Scanner { let text = textInitial!; // 当前要扫描的源码 let pos: number; // 当前位置 // 以下是一些“全局”变量,存储当前标记的信息 let end: number; let startPos: number; let tokenPos: number; let token: SyntaxKind; let tokenValue!: string; let tokenFlags: TokenFlags; // ...(略) const scanner: Scanner = { getStartPos: () => startPos, getTextPos: () => pos, getToken: () => token, getTokenPos: () => tokenPos, getTokenText: () => text.substring(tokenPos, pos), getTokenValue: () => tokenValue, // ...(略) }; return scanner; // 这里是具体实现的函数,函数可以直接访问上面这些“全局”变量 }
核心的扫描函数如下:
function scan(): SyntaxKind { startPos = pos; // 记录扫描之前的位置 while (true) { // 这是一个大循环 // 如果发现空格、注释,会重新循环(此时重新设置 tokenPos,即让 tokenPos 忽略了空格) // 如果发现一个标记,则退出函数 tokenPos = pos; // 到字符串末尾,返回结束标记 if (pos >= end) { return token = SyntaxKind.EndOfFileToken; } // 获取当前字符的编码 let ch = codePointAt(text, pos); switch (ch) { // 接下来就开始判断不同的字符可能并组装标记 case CharacterCodes.exclamation: // 感叹号(!) if (text.charCodeAt(pos + 1) === CharacterCodes.equals) { // 后面是不是“=” if (text.charCodeAt(pos + 2) === CharacterCodes.equals) { // 后面是不是还是“=” return pos += 3, token = SyntaxKind.ExclamationEqualsEqualsToken; // 获得“!==”标记 } return pos += 2, token = SyntaxKind.ExclamationEqualsToken; // 获得“!=”标记 } pos++; return token = SyntaxKind.ExclamationToken; //获得“!”标记 case CharacterCodes.doubleQuote: case CharacterCodes.singleQuote: // ...(略) } } }
扫描的步骤很简单:先判断是什么字符,然后尝试组成标记。
标记的种类繁多,所以这部分源码也很长,但都是大同小异的判断,这里不再赘述(相信即使写了你也会快速跳过),有兴趣的自行读源码。
这里列出一些需要注意的点:
1. 并不是所有字符都是源码的一部分,所以,可能在扫描时对有些字符报错。
2. 最开头的 #! (Shebang)会被忽略(这部分虽然暂时没入ES 标准(发文时属于 Stage 2),但多数引擎都会忽略它)
3. 为了支持自动插入分号,扫描时还同时记录了当前标记之前有没有换行的信息。
4. TS 很贴心地考虑 GIT 合并冲突问题。
如果一个文件出现 GIT 合并冲突,GIT 会自动在该文件插入一些冲突标记,如:
<<<<<<< HEAD 这是我的代码 ======= 这是别人提交的代码 >>>>>>>
TS 在扫描到 <<<<<<< 后(正常的代码不太可能出现),会将这段代码识别为冲突标记,并在词法扫描时自动忽略冲突的第二段,相当于屏蔽了冲突代码,而不是将冲突标记看成代码的一部分然后报很多错。这样,即使代码存在冲突,当你在修改第一段代码时,不会受任何影响(包括智能提示等),但因为第二段被直接忽略,所以修改第二段代码不会有智能提示,只有语法高亮。
正则表达式和字符串一样,是不可拆分的一种标记,当碰到 / 后,它可能是除号,也可能是正则表达式的开头。在扫描阶段还无法确定它的真正意义。
有的人可能会说除号也可以通过扫描后面有没有新的除号(因为正则表达式肯定是一对除号)判断它是不是正则,这是不对的:
var a = 1 / 2 / 3 // 虽然出现了两个除号,但不是正则
实际上需要区分除号是不是正则,是看除号之前有没有存在表达式,这是在语法解析阶段才能知道的事情。因此在词法扫描阶段,直接不考虑正则,除号可能是除号(/)、除号等于(/=)、注释(//)。
当在语法扫描时,发现此处需要的是一个独立的表达式,而不可能是除号时,调用 scanner.reScanSlashToken(),将当前除号标记重新按正则扫描。
类似地、< 可能是小于号,也可能是 JSX 的开头。模板 `x${...}` 中的 } 可能是右半括号,也可能是模板字面量的最后一部分,这些都需要在语法分析阶段区分,需要提供重新扫描的方法。
TS 引入了很多关键字,但为了兼容 JS,这些关键字只有在特定场合才能作关键字,比如 public 后跟 class,才把 public 作关键字(这样不影响本来是正确的 JS 代码:var public = 0)。
这时,在语法分析时,就要先预览下一个标记是什么,才能决定如何处理当前的标记。
scanner 提供了 lookAhead 和 tryScan 两个预览用的函数。
函数的主要原理是:先记住当前标记和扫描的位置,然后执行新的扫描,读取到后续标记内容后,再还原成之前保存的状态。
function lookAhead<T>(callback: () => T): T { return speculationHelper(callback, /*isLookahead*/ true); } function tryScan<T>(callback: () => T): T { return speculationHelper(callback, /*isLookahead*/ false); } function speculationHelper<T>(callback: () => T, isLookahead: boolean): T { const savePos = pos; const saveStartPos = startPos; const saveTokenPos = tokenPos; const saveToken = token; const saveTokenValue = tokenValue; const saveTokenFlags = tokenFlags; const result = callback(); // If our callback returned something ‘falsy‘ or we‘re just looking ahead, // then unconditionally restore us to where we were. if (!result || isLookahead) { pos = savePos; startPos = saveStartPos; tokenPos = saveTokenPos; token = saveToken; tokenValue = saveTokenValue; tokenFlags = saveTokenFlags; } return result; }
lookAhead 和 tryScan 的唯一区别是:lookAhead 会始终还原到原始状态,而 tryScan 则允许不还原。
本节主要介绍了扫描器的具体实现。扫描器提供了以下接口:
如果你觉得理解起来比较吃力,那告诉你个不幸的消息——词法扫描是所有流程中最简单的。
有些人可能想要开发自己的编译器,这里给个提示,如果你设计的语言采用缩进式语法,你在实现词法扫描步骤中,需要记录每个标记之前的缩进数(TAB 按一个缩进处理)。如果这个标记不在行首,缩进数记位 -1。在语法解析阶段,如果发现下一个标记的缩进比当前存储的缩进大,说明增加了缩进,更新当前存储的缩进。
TS 源码中的词法扫描是比较复杂但完整的一种实现,如果仅仅为了语法高亮,这点复杂的没必要的,对语法高亮来说,使用正则匹配已经足够了,这是另一种词法扫描方案。
TS 这部分源码有 2000 行多,相信领悟文中介绍的方法、概念之后,你可以自己读完这些源码。
下一节将具体介绍语法解析的第一步:语法树。(不定时更新)
#如果你有问题可以在评论区提问#
标签:经理 style 提问 ++ enum idt lang 定时 特殊
原文地址:https://www.cnblogs.com/xuld/p/12210780.html