标签:记事本 write ram sel its 框架 tty efi 方法
记事本内容:
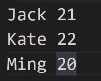
打印结构:
方法1:
object SparkSessionTest {
case class Person(name:String,age:Int)
def main(args: Array[String]): Unit = {
val sparkSession=SparkSession.builder().appName("SparkSessionTest")
.master("local[*]")
.getOrCreate()
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val rowRdd=rdd.map(_.split(" ")).map(row=>Person(row(0),row(1).toInt))
import sparkSession.implicits._
rowRdd.toDF
sparkSession.stop()
}
}
方法2:
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val schemaFiled="name,age"
val schemaString=schemaFiled.split(",")
val schema =StructType(
List(
StructField(schemaString(0),StringType,nullable = true),
StructField(schemaString(1),IntegerType,nullable = true)
)
)
val rowRdd= rdd.map(_.split("")).map(p=>Row(p(0),p(1).toInt))
val df=sparkSession.createDataFrame(rowRdd,schema)
df.show()
结果展示:

parquet的优势
支持列存储+嵌套数据格式+适配多个计算框架
节省表扫描时间和反序列的时间
压缩技术稳定出色,节省存储空间
Spark操作 Parquet文件比操作CSV等普通文件的速度更快
加载数据:sparkSession.read.parquet(“/nginx/20200110.parquet”)
写入数据:df.write.mode(SaveMode.Overwrite).parquet(“/path/to”)
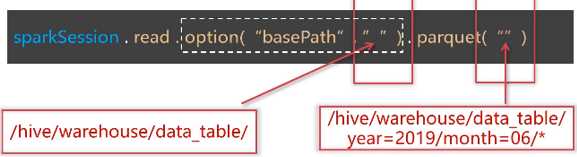
分区文件
加载批量数据:
Df.show()//只显示前20条数据 Df.show(3)//只显示前3条数据 df.show( false)//每列可以显示多于20个字符 dt show(3, false)
Df.select (“字段1”,”字段2”).show() Df.select(col(“”) as(“别名1”),col(“字段2”)+1).show()
df.first()//获取第一行数据,返回RoW df.head( 3)//获取前3行数据,返回 Array Row] df.take (3)//获取前3行数据,返回 Array[Row] df.takeaslist(3//获取前3行数据,返回List[Row] df.limit(3).show()//返回新的 Data Frame,不是 Action操作
Df.where(“age>21”).show() Df.filter(“age>21”).show() Df.where(col(“age”)>21).show() Ds.where($”age”>21).show()
Df.where(“age=21”).show Df.where(col(“age”)===21).show Df.where(col(“age”)=!=21).show
Val ageFilter_1 =col(“age”)>21 Val agefilter_2=col(“age”)<25 Val ageFilter_3=agefilter_1.or(ageFilter_2) Df.where(col(“name”)===”jack”).where(ageFilter_3)
Val ageFilter_1 =col(“age”)>21 Val ageFilter_2=col(“age”)<25 Val ageFilter_3 =ageFilter_1.ll(ageFilter_2) Df.where(col(“name”)===”jack”) .where(ageFitler_3) .show
//按照身份统计人数
Df.groupBy(col(“province”)) .count .show
按照城市,手机运营商分组统计人数并按人数排序
//方法1
Df.groupby(col(“city”),col(“”op_phone“”)) .count .withColumnRenamed(“count”,”num”) .orderBy(col(“num”).desc) .show
//方法2 Ds.groupBy($”city”,$”op_phone”) .count .withColumnRenamed(“count”,”num”) .sort($”num”.desc) .show
按年统计注册用户最高的积分,以及平均积分
Df.groupBy(year(col(“add_time”))) .agg(max(col(“total_mark”).as(“max_mark”)), Avg(col(“total_mark”).as(“avg_mark”)) ) .show

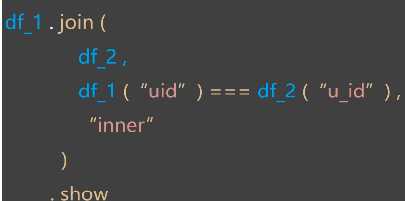


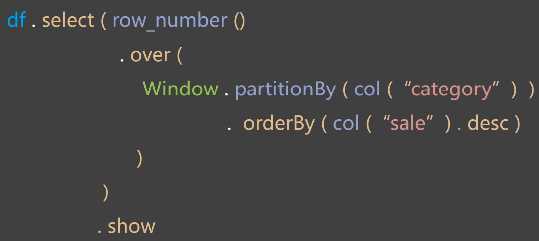
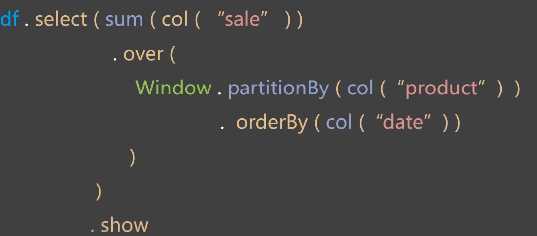
标签:记事本 write ram sel its 框架 tty efi 方法
原文地址:https://www.cnblogs.com/shaozhiqi/p/12213047.html