标签:很多 没有 直接 日期类型 而且 数值 个人 构建 strong
最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下:
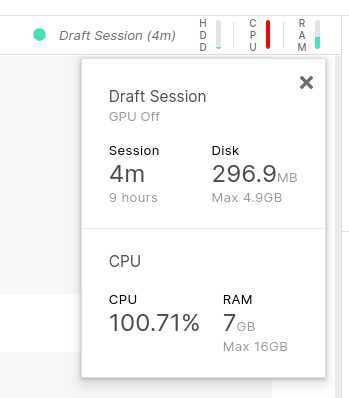
在处理数据过程中发现会超出,虽然我们都知道对于大数据的处理有诸如spark等分布式处理框架,但是依然存在下面的问题:
所以这里还是考虑针对数据进行内存方面的优化,以达到减少内存占用,并在kernel上正常运行为最终目的;
这个不用多说,虽然一般为了省事,都是开头一起load到内存中,但是特殊情况下,这里还是要注意的,如下:
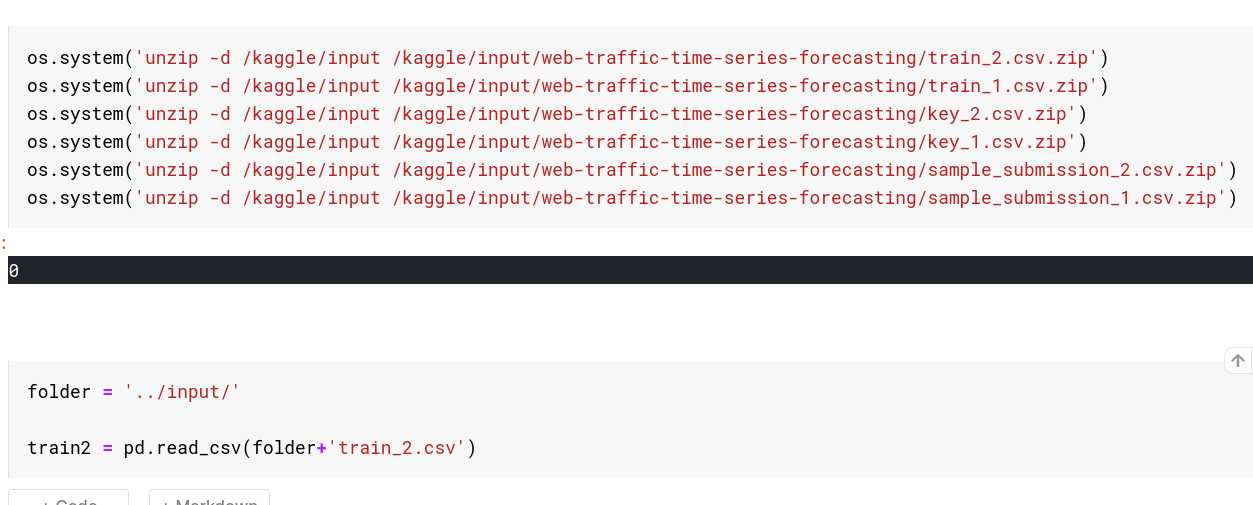
可以看到,虽然可用数据文件很多,但是由于当前处理需要的仅仅是train2.csv,所以只加载其即可,不要小看这一步,这里每个文件加载过来都是几百M的;
这里是在预处理部分能做的对内存影响最大的一部分,基本思路如下:
如下是未做转换前的DataFrame信息:
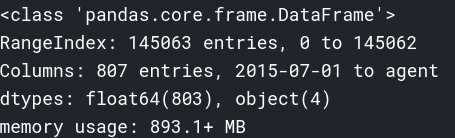
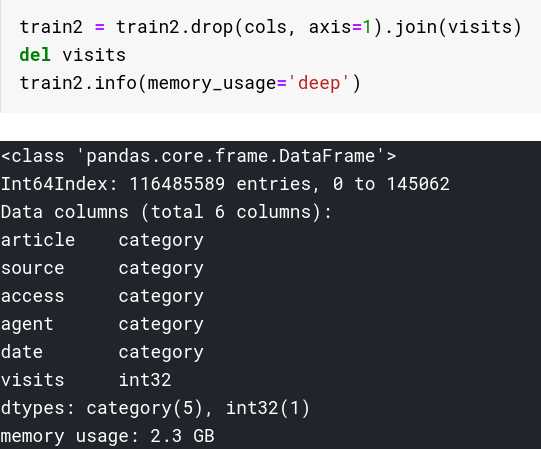
如下是我对原始数据各字段的类型转换以及转换后的DataFrame信息:
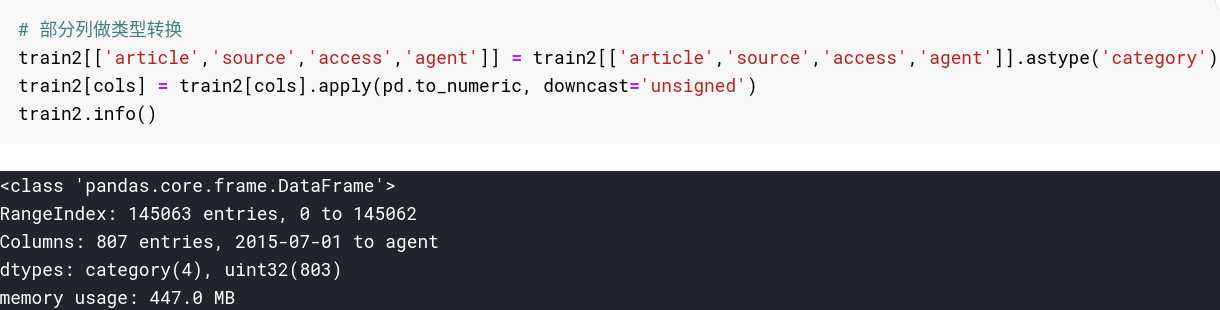
看到内存占用直接降了一半,不要小看这几百M,在DataFrame进行各种apply、groupby运算时,临时占用的内存是非常多的,也很容易超过峰值导致kernel重启;
PS:当然,这里如果直接加载时指定数据类型也是可以的,我这边为了展示转换前后效果,所以直接指定,实时上更常见的做法时,先直接加载,info或者describe看数据信息,然后判断数据应该的类型,修改代码为直接指定;
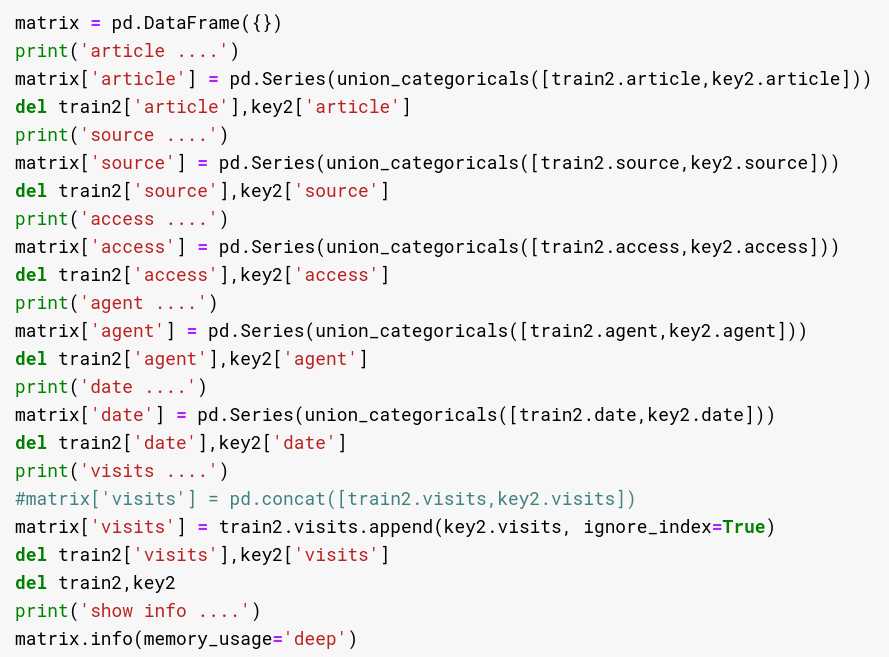
做过时序数据预测的朋友应该直到,时序数据构建时,一个特点是需要连接训练和测试数据,然后同时针对这些数据做时序上的延迟特征、各种维度的统计特征等等,因此这里就涉及到数据连接,一定要注意要用union_categoricals代替pd.concat,如果直接使用concat,那么category类型的列会被转为object,那么在连接的过程中,内存就会超过峰值,导致kernel重启,那就悲剧了。。。。
如下,是对数据做reshape的操作,这个是该竞赛数据的一个特点,由于其把每一天对应的访问数据都放到了一起,也就是一行中包含了一篇文章的每一天的访问量,而这是不利于后续做延迟特征构建的,需要将每一天的信息单独作为一行,因此需要reshape:
如下这种连接、即时销毁的方式虽然看着丑,但是效果还是可以的:
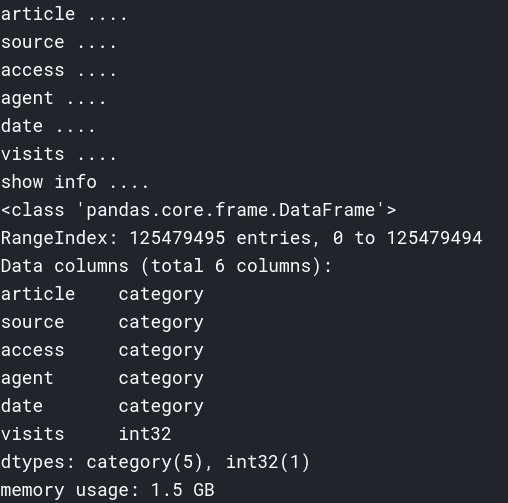
如下是采取这种方式链接后的DataFrame信息,其实难点不在于DataFrame多大,而是它在运算过程中的内存峰值会超过限制:
https://www.kaggle.com/c/web-traffic-time-series-forecasting
https://www.kaggle.com/holoong9291/web-traffic-time-series-forecasting
大家可以到我的Github上看看有没有其他需要的东西,目前主要是自己做的机器学习项目、Python各种脚本工具、数据分析挖掘项目以及Follow的大佬、Fork的项目等:
https://github.com/NemoHoHaloAi
由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
标签:很多 没有 直接 日期类型 而且 数值 个人 构建 strong
原文地址:https://www.cnblogs.com/helongBlog/p/12216059.html