标签:数据 请求 reason get $set 解析 cut 运行 mongo
先上结果:
问题:
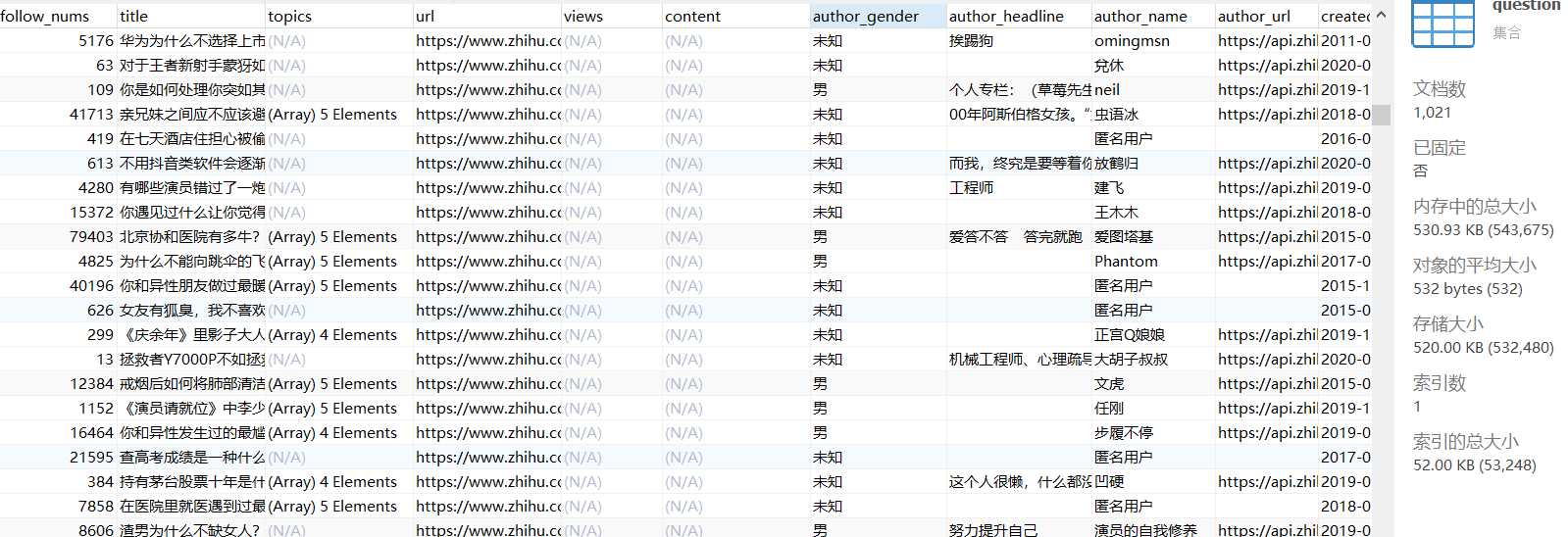
答案:
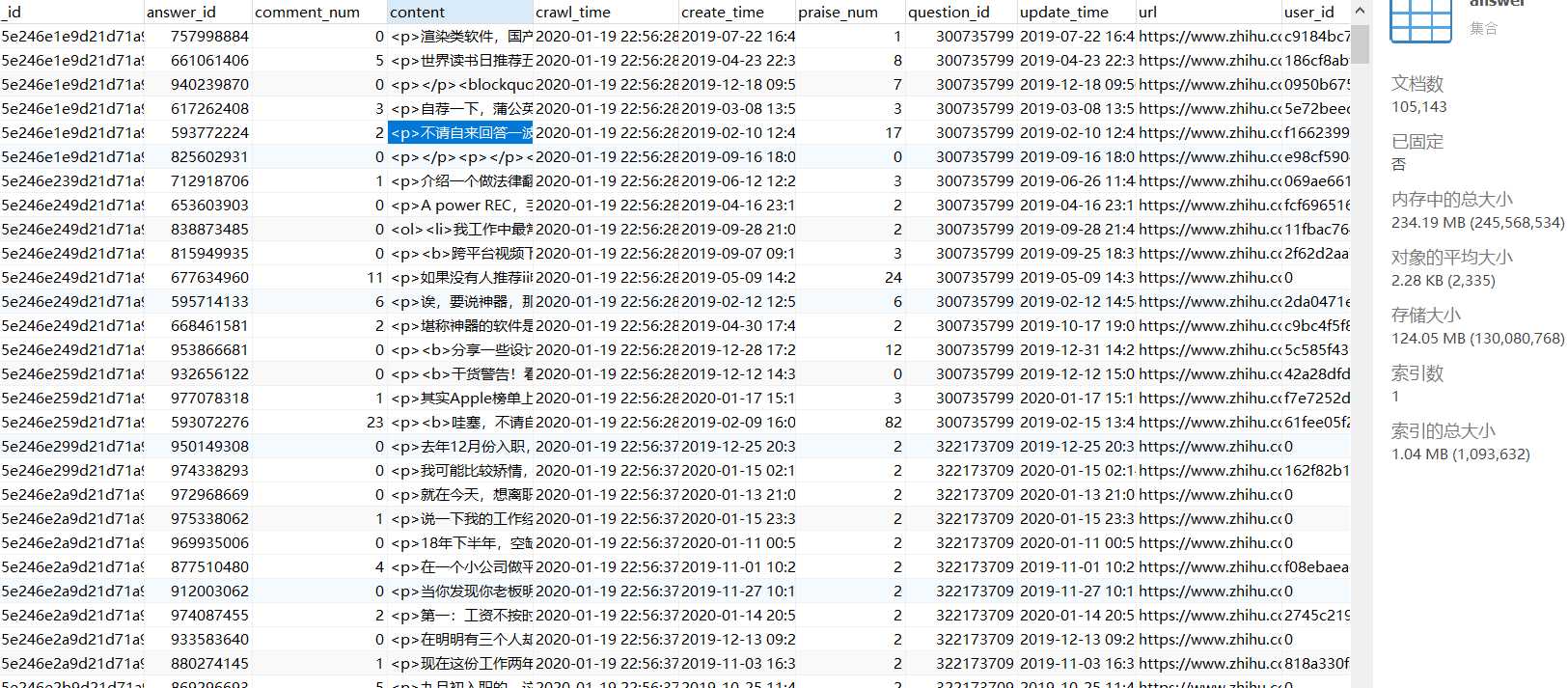
可以看到现在答案文档有十万多,十万个为什么~hh
正文开始:
分布式爬虫应该是在多台服务器(A B C服务器)布置爬虫环境,让它们重复交叉爬取,这样的话需要用到状态管理器。
状态管理器主要负责url爬取队列的管理,亦可以当爬虫服务器。同时配置好redis及scrapy-redis环境就行~
爬虫服务器主要负责数据的爬取、处理等。安装好scrapy-redis就行~
如下图:
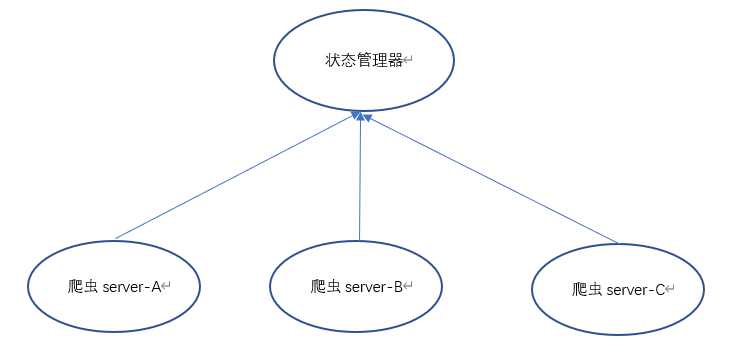
需要多台机器同时爬取目标url并且同时从url中抽取数据,N台机器做一模一样的事,通过redis来调度、中转,也就是说它没有主机从机之分。
要明白,scrapy是不支持分布式的。
分布式爬虫的优点
pip install scrapy-redis
然后这个知乎爬取项目要从scrapy讲起:
cmd中启动一个scrapy项目:
scrapy startproject ArticleSpider
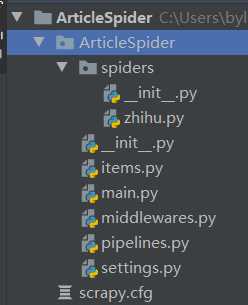
进入项目文件夹并开始一个爬虫:
cd ArticleSpider
scrapy genspider zhihu www.zhihu.com
目前的项目文件:
分析知乎的问题的api:
在知乎首页每次向下拉都会触发这个ajax请求,并且返回内容是问题的url、标题等,很明显它就是问题的api了~
https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=8c3313b2932c370198480b54dc89fd3a&desktop=true&page_number=2&limit=6&action=down&after_id=5
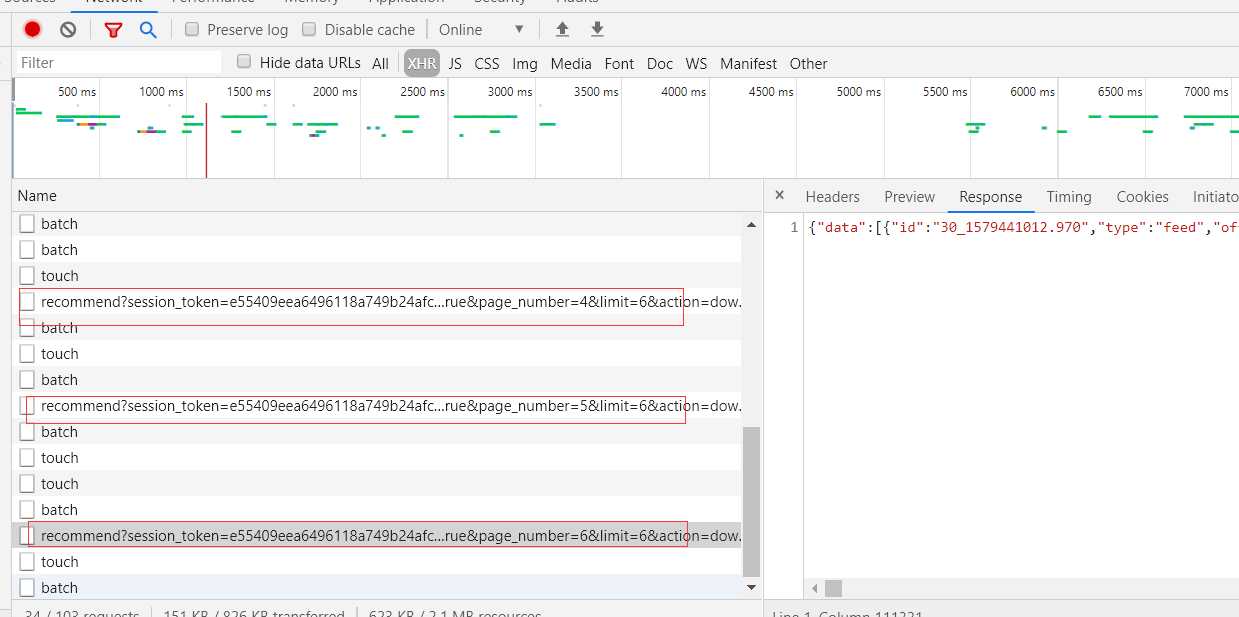
它的返回:

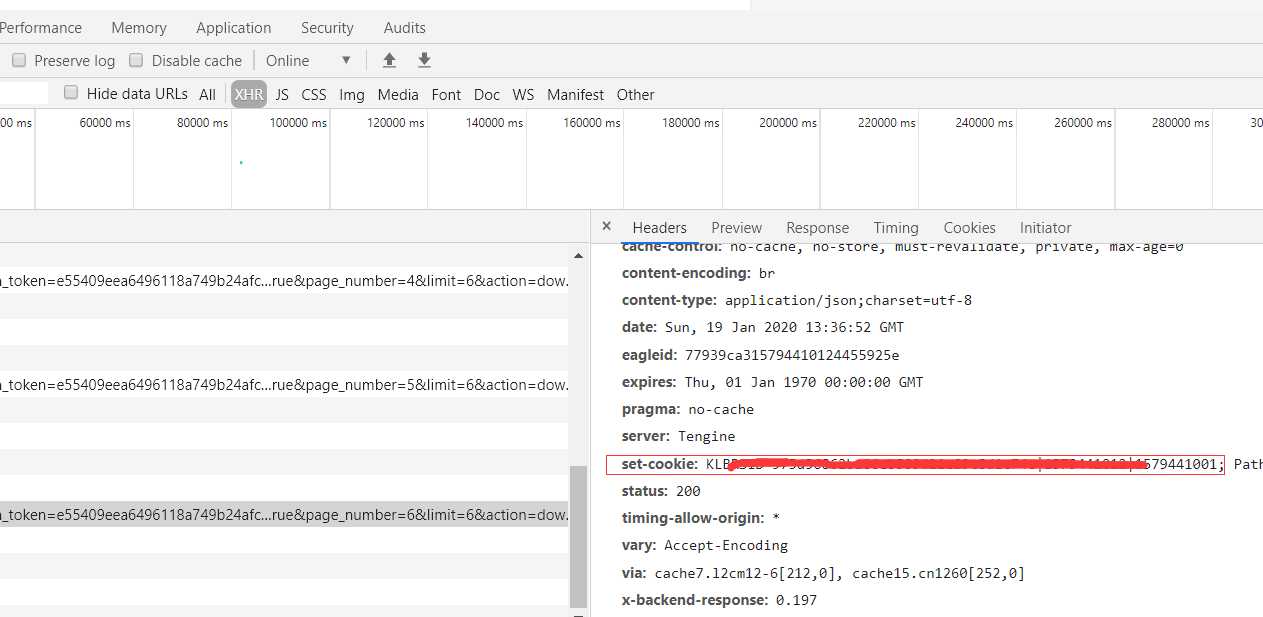
有趣的是每次请求它,它的response头都会返回一个set-cookie,意味着要用返回的新的cookie请求下一页的答案,否则返回错误。
看看问题api请求头带的参数:
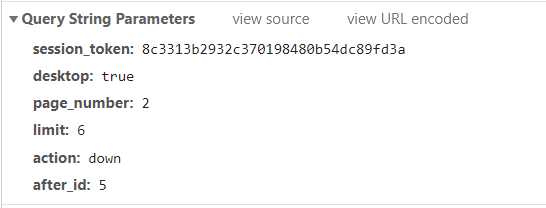
这是个get请求,其实第一条链接可以在请求首页后的html源码里找到,这样就找到了这几个参数,需要变动的只有页数page_number:
在html源码里的问题api:

我们需要先请求首页html然后以re匹配获得这条开始的问题api,然后伪造后面页数的请求。
答案api则是在往下拉所有答案时找到的:
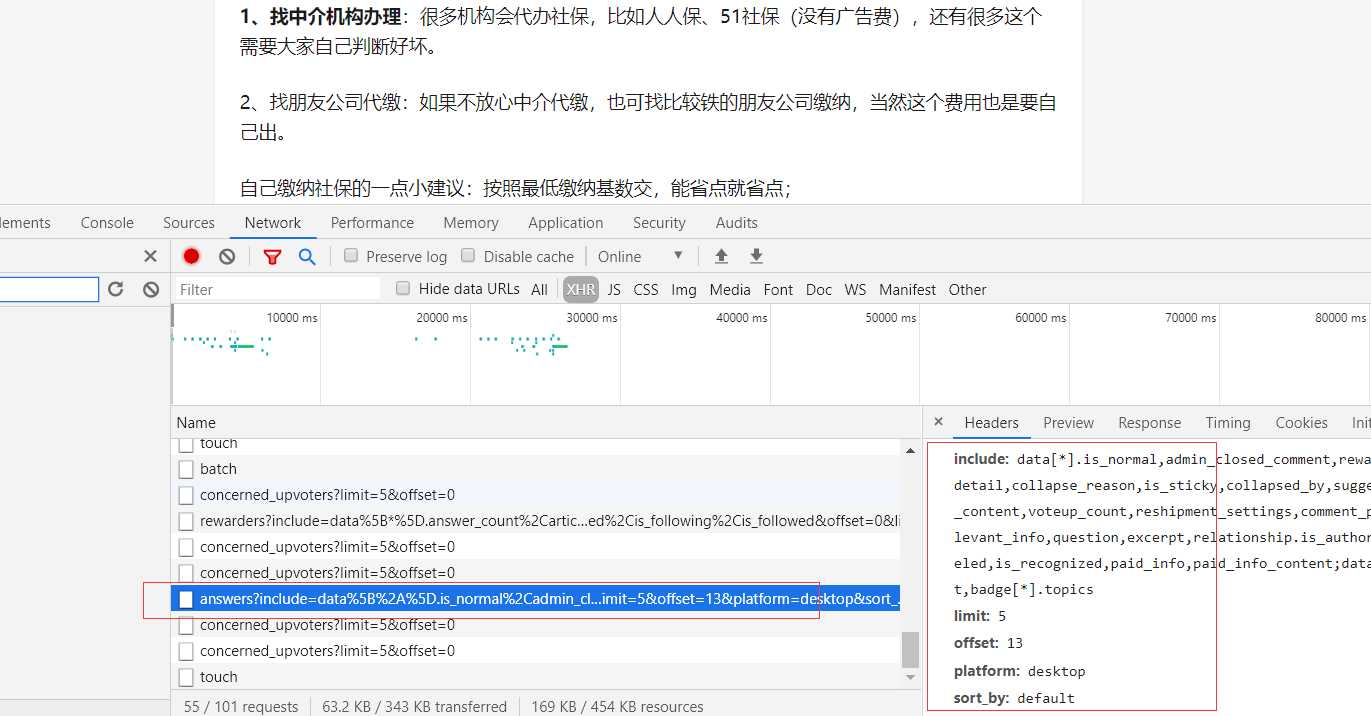
答案api的请求更容易处理,只需要修改问题的id及offset偏移量就行,甚至不用cookie来请求。
比如这条就是某个问题的答案api:
https://www.zhihu.com/api/v4/questions/308761407/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=13&platform=desktop&sort_by=default
它的返回:

class QuestionItem(scrapy.Item): ‘‘‘ 问题的item,问题和答案分两个集合保存在mongodb中 ‘‘‘ title = scrapy.Field() created = scrapy.Field() answer_num = scrapy.Field() comment_num = scrapy.Field() follow_nums = scrapy.Field() question_id = scrapy.Field() topics = scrapy.Field() url = scrapy.Field() author_url = scrapy.Field() author_name = scrapy.Field() author_headline = scrapy.Field() author_gender = scrapy.Field() crawl_time = scrapy.Field() class Answer_Item(scrapy.Item): ‘‘‘ 答案的item ‘‘‘ answer_id = scrapy.Field() question_id = scrapy.Field() url = scrapy.Field() user_name = scrapy.Field() user_id = scrapy.Field() content = scrapy.Field() praise_num = scrapy.Field() comment_num = scrapy.Field() create_time = scrapy.Field() update_time = scrapy.Field() crawl_time = scrapy.Field()
然后是spider.py的修改:
# -*- coding: utf-8 -*- import re import time import json import datetime import scrapy from ArticleSpider.items import QuestionItem, Answer_Item from scrapy.http import Request from scrapy_redis.spiders import RedisSpider def timestamp_2_date(timestamp): ‘‘‘ 用来将时间戳转为日期时间形式 ‘‘‘ time_array = time.localtime(timestamp) my_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array) return my_time def handle_cookie(response): ‘‘‘ 用来处理set-cookie ‘‘‘ cookie_section = response.headers.get(‘set-cookie‘) # 匹配cookie片段 sections = re.findall(‘(KLBRSID=.*?);‘, str(cookie_section)) print(sections) raw_cookie = response.request.headers[‘Cookie‘].decode(‘utf-8‘) # 替换cookie片段到完整cookie里 cookie = re.sub(‘KLBRSID=.*‘, sections[0], raw_cookie) return cookie class ZhihuSpider(RedisSpider): # spider名 name = ‘zhihu‘ # 允许访问的域名 allowed_domains = [‘www.zhihu.com‘] # redis_key,到时scrapy会去redis读这个键的值,即要访问的url,原来start_url的值也是放在redis里 redis_key = ‘zhihu:start_urls‘ # spider的设置,在这里设置可以覆盖setting.py里的设置 custom_settings = { # 用来设置随机延迟,最大5秒 "RANDOM_DELAY": 5, ‘ITEM_PIPELINES‘:{ # 如果要使用scrapy-redis, RedisPipeline必须设置, ‘scrapy_redis.pipelines.RedisPipeline‘: 3, # MongoPipeline则是用来保存爬取的数据的。 ‘ArticleSpider.pipelines.MongoPipeline‘: 4, }, "DOWNLOADER_MIDDLEWARES": { # CookieMiddleware用来给request设置cookie ‘middlewares.CookieMiddleware‘: 999, # RandomDelayMiddleware用来设置随机延迟 "middlewares.RandomDelayMiddleware": 888, # RandomUserAgentMiddleware用来设置随机user-agent ‘middlewares.RandomUserAgentMiddleware‘:777, } } # 上面这样设置好了就能使用scrapy-redis进行分布式的爬取,其他的比如parse()函数按照scrapy的逻辑设置就好 # 答案的api answer_api = ‘https://www.zhihu.com/api/v4/questions/{0}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit={1}&offset={2}&platform=desktop&sort_by=default‘ def parse(self, response): ‘‘‘ 解析首页,获取问题api ‘‘‘ # 每次请求知乎问题api都会返回一个新的set-cookie(只是一段cookie),用来设置新的cookie。旧的cookie无法访问下一页的链接 cookie = handle_cookie(response) print(cookie) # 请求首页后,在首页html源码里寻找问题的api question_api = re.findall(‘"previous":"(.*?)","next‘, response.text, re.S) question_url = question_api[0].replace(‘\\u002F‘, ‘/‘) # 用新的cookie请求问题api,回调函数为parse_question yield Request(url=question_url,callback=self.parse_question,headers={‘cookie‘:cookie}) def parse_question(self,response): ‘‘‘ 解析问题api返回的json数据 ‘‘‘ # 构造新cookie cookie = handle_cookie(response) dics = json.loads(response.text) for dic in dics[‘data‘]: try: ques_item = QuestionItem() if ‘question‘ in dic[‘target‘]: # 问题标题 ques_item[‘title‘] = dic[‘target‘][‘question‘][‘title‘] # 问题创建时间 ques_item[‘created‘] = dic[‘target‘][‘question‘][‘created‘] ques_item[‘created‘] = timestamp_2_date(ques_item[‘created‘]) # 回答数 ques_item[‘answer_num‘] = dic[‘target‘][‘question‘][‘answer_count‘] # 评论数 ques_item[‘comment_num‘] = dic[‘target‘][‘question‘][‘comment_count‘] # 关注人数 ques_item[‘follow_nums‘] = dic[‘target‘][‘question‘][‘follower_count‘] # 问题id ques_item[‘question_id‘] = dic[‘target‘][‘question‘][‘id‘] #问题url ques_item[‘url‘] = dic[‘target‘][‘question‘][‘id‘] ques_item[‘url‘] = ‘https://www.zhihu.com/question/‘ + str(ques_item[‘url‘]) # 问题标签 if ‘uninterest_reasons‘ in dic: topics = [] for i in dic[‘uninterest_reasons‘]: topics.append(i[‘reason_text‘]) ques_item[‘topics‘] = topics # 作者url ques_item[‘author_url‘] = dic[‘target‘][‘question‘][‘author‘][‘url‘] # 作者名 ques_item[‘author_name‘] = dic[‘target‘][‘question‘][‘author‘][‘name‘] # 作者签名 ques_item[‘author_headline‘] = dic[‘target‘][‘question‘][‘author‘][‘headline‘] # 作者性别 ques_item[‘author_gender‘] = dic[‘target‘][‘question‘][‘author‘].get(‘gender‘) if ques_item[‘author_gender‘]: if ques_item[‘author_gender‘] == 0: ques_item[‘author_gender‘] = ‘女‘ else: ques_item[‘author_gender‘] = ‘男‘ else: ques_item[‘author_gender‘] = ‘未知‘ # 爬取时间 ques_item[‘crawl_time‘] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") yield ques_item except: pass # 问题api里会有个is_end的值,用来判断是否还有下一页 if not dics[‘paging‘][‘is_end‘]: # 有下一页,获取next里的下一页链接 next_url = dics[‘paging‘][‘next‘] # 用新的cookie请求下一页问题url yield Request(url=next_url, callback=self.parse_question, headers={‘cookie‘: cookie}) # 请求答案api,api需要传入question_id, limit及页码 yield Request(url=self.answer_api.format(ques_item[‘question_id‘], 20, 0), callback=self.parse_answer) def parse_answer(self,response): #处理answerAPI返回的json ans_json = json.loads(response.text) # is_end的值意味着当前url是否是最后一页 is_end = ans_json[‘paging‘][‘is_end‘] totals_answer = ans_json[‘paging‘][‘totals‘] # 下一页url next_url = ans_json[‘paging‘][‘next‘] for answer in ans_json[‘data‘]: ans_item = Answer_Item() # 答案id ans_item[‘answer_id‘] = answer[‘id‘] # 答案对应的问题id ans_item[‘question_id‘] = answer[‘question‘][‘id‘] # 答案url ans_item[‘url‘] = answer[‘url‘] # 答者用户名 ans_item[‘user_name‘] = answer[‘author‘][‘name‘] if ‘name‘ in answer[‘author‘] else None # 答者id ans_item[‘user_id‘] = answer[‘author‘][‘id‘] if ‘id‘ in answer[‘author‘] else None # 答案内容 ans_item[‘content‘] = answer[‘content‘] if ‘content‘ in answer else None # 赞同人数 ans_item[‘praise_num‘] = answer[‘voteup_count‘] # 评论人数 ans_item[‘comment_num‘] = answer[‘comment_count‘] # 答案创建时间 ans_item[‘create_time‘] = answer[‘created_time‘] ans_item[‘create_time‘] = timestamp_2_date(ans_item[‘create_time‘]) # 答案修改时间 ans_item[‘update_time‘] = answer[‘updated_time‘] ans_item[‘update_time‘] = timestamp_2_date(ans_item[‘update_time‘]) # 爬取时间 ans_item[‘crawl_time‘] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") yield ans_item # offset偏移,一页20,每问题只爬50页回答。即offest>1000 offset = next_url.split(‘offset=‘)[1].split(‘\u0026‘)[0] if int(offset)>1000: pass else: # 当当前页不为最后一页且offset不大于1000时,继续请求下一页答案 if not is_end: yield scrapy.Request(url=next_url, callback=self.parse_answer)
settings.py添加以下行:
# 指定使用scrapy-redis的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定使用scrapy-redis的去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues SCHEDULER_PERSIST = True FEED_EXPORT_ENCODING = ‘utf-8‘ # redis配置 REDIS_HOST = ‘填状态管理器服务器ip,请一定要保证redis数据库能远程访问‘ REDIS_PORT = 6379 # redis密码 REDIS_PARAMS = {‘password‘: ‘123456‘} # 当scrapy-redis爬完之后会空等, 等待redis提供继续爬取的url。但是如果已经爬完了。没必要继续等,设置这个当意味启动3600s时停止spider。 CLOSESPIDER_TIMEOUT = 3600
pipelines.py的修改,将数据保存到远程mongodb数据库服务器:
from pymongo import MongoClient class ArticlespiderPipeline(object): def process_item(self, item, spider): return item class MongoPipeline(object): def __init__(self, databaseIp=‘远程mongodb服务器ip‘, databasePort=27017, user="", password="",): self.client = MongoClient(databaseIp, databasePort) # self.db = self.client.test_database # self.db.authenticate(user, password) def process_item(self, item, spider): postItem = dict(item) # 把item转化成字典形式 print(postItem) if item.__class__.__name__ == ‘QuestionItem‘: mongodbName = ‘zhihu‘ self.db = self.client[mongodbName] # 更新插入问题数据 self.db.question.update({‘question_id‘:postItem[‘question_id‘]},{‘$set‘:postItem},upsert=True) elif item.__class__.__name__ == ‘Answer_Item‘: mongodbName = ‘zhihu‘ self.db = self.client[mongodbName] # 更新插入答案数据 self.db.answer.update({‘answer_id‘: postItem[‘answer_id‘]}, {‘$set‘: postItem}, upsert=True) # 会在控制台输出原item数据,可以选择不写 return item
middlewares.py的修改:
import logging import random import time class RandomDelayMiddleware(object): ‘‘‘ 这个类用来设置自定义的随机延时 ‘‘‘ def __init__(self, delay): self.delay = delay @classmethod def from_crawler(cls, crawler): delay = crawler.spider.settings.get("RANDOM_DELAY", 10) if not isinstance(delay, int): raise ValueError("RANDOM_DELAY need a int") return cls(delay) def process_request(self, request, spider): if ‘signin?next‘ in request.url: raise IgnoreRequest delay = random.randint(0, self.delay) logging.debug("### random delay: %s s ###" % delay) time.sleep(delay) class RandomUserAgentMiddleware(): ‘‘‘ 这个类用来给spider随机设置user_agent里的请求头 ‘‘‘ user_agent = [ ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36‘, ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0‘, ‘Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko‘, ] def process_request(self, request, spider): request.headers[‘User-Agent‘] = random.choice(self.user_agent) class CookieMiddleware(): ‘‘‘ 这个类用来给spider随机设置cookie,scrapy要求cookies是字典类型 ‘‘‘ def process_request(self, request, spider): with open(‘cookies.txt‘) as f: raw_cookie = f.read() # 当请求首页时,提供cookie if request.url in ‘https://www.zhihu.com/‘: request.headers[‘cookie‘] = raw_cookie print(‘---‘,request.headers)
使用py文件 启动scrapy-redis:
from scrapy.cmdline import execute import sys import os # os.path.abspath(__file__)当前py文件的路径 # os.path.dirname(os.path.abspath(__file__))当前文件目录 # 设置工程目录 sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 相当于在cmd里执行scrapy crawl zhihu execute([‘scrapy‘,‘crawl‘,‘zhihu‘])
启动后scrapy-redis会等待start_urls push进redis
我在centos服务器布置好了redis,在终端执行以下命令以将知乎首页放进redis:
redis-cli auth 123456 lpush zhihu:start_urls https://www.zhihu.com
可以看到当多个服务器启动该爬虫进程,其间协作运行:
最后,已将该项目放github,若有需要的话请上去拿~
https://github.com/dao233/spider/tree/master/ArticleSpider
END~
标签:数据 请求 reason get $set 解析 cut 运行 mongo
原文地址:https://www.cnblogs.com/byadmin/p/12215657.html