标签:条件 数据 删除索引 orm 需求 rest 实现 读写 dex
Elasticsearch 是一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于Java/Lucene构建,可以用于全文搜索,结构化搜索以及近实时分析。可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架。 说明: Lucene:只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene,学习成本高,Lucene确实非常复杂。 Elasticsearch 是 面向文档型数据库,这意味着它存储的是整个对象或者 文档,它不但会存储它们,还会为他们建立索引,这样你就可以搜索他们了
目录:
应用场景
solr VS ES
核心概念
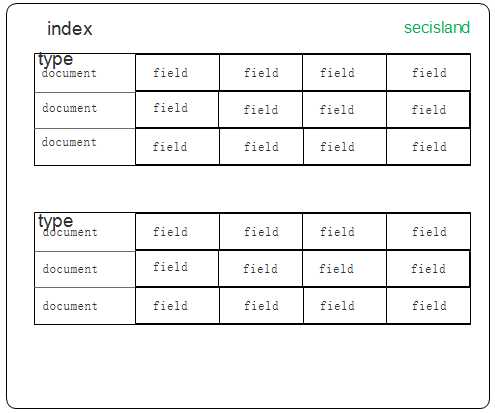
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns) Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
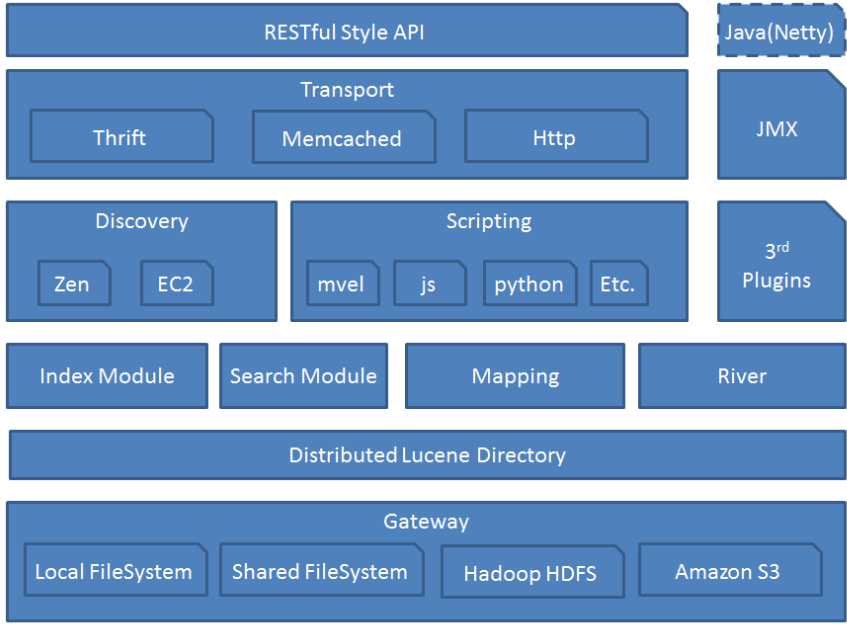
ES模块结构
$ curl -XPUT http://localhost:9200/twitter/ -d ‘
index :
number_of_shards : 3
number_of_replicas : 2
每个操作会自动路由主碎片所在的节点,在上面执行操作,并且同步到其他复制节点,通过使用“non blocking IO”模式所有复制的操作都是并行执行的,也就是说如果你的节点的副本越多,你网络上的流量消耗也会越大。复制节点同样接受来自外面的读操作,意义就是你的复制节点越多,你的索引的可用性就越强,对搜索的可伸缩行就更好,能够承载更多的操作
分片示例

PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
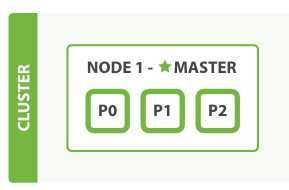
集群示例图如下: (此时集群健康状态为: yellow 三个从分片还没有被分配到节点上)



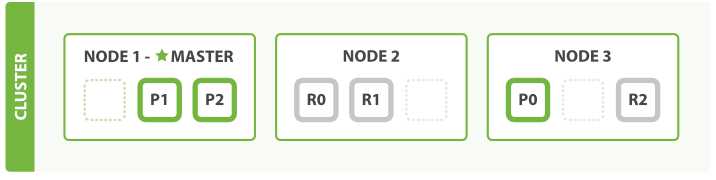
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
现在 blogs 的索引总共有9个分片:3个主分片和6个从分片, 又会变成一个节点一个分片的状态了,最终得到了三倍搜索性能的三节点集群


标签:条件 数据 删除索引 orm 需求 rest 实现 读写 dex
原文地址:https://www.cnblogs.com/lhxsoft/p/12225791.html