bert模型在tensorflow1.x版本时,也是先发布的命令行版本,随后又发布了bert-tensorflow包,本质上就是把相关bert实现封装起来了。
tensorflow2.0刚刚在2019年10月左右发布,谷歌也在积极地将之前基于tf1.0的bert实现迁移到2.0上,但近期看还没有完全迁移完成,所以目前还没有基于tf2.0的bert安装包面世,因为近期想基于现有发布的模型做一个中文多分类的事情,所以干脆就弄了个基于命令行版本的。过程中有一些坑,随之记录下来。
1. colab:因为想用谷歌免费的GPU(暂时没研究TPU怎么用),所以直接在colab上弄。
2. 中文多分类:
2.1. 训练数据来源:在百度百科上找了大概100多个词条的数据,自己随便标注成大概8个类别吧。把百科的概述、正文、属性等信息进行清洗后连到一起,类似于这种格式:
label info
1 词条1的描述balabala
0 词条2的描述balabala
然后再按照9:1分成两个集合,分别明明为train.tsv 和 dev.tsv,作为训练集和测试集。注意每个训练集的第一行都是标题行,这个是我的数据解析器里面这么定义的。
2.2. 预训练模型:谷歌已经提供了基于tf2.0 keras网络结构的中文预训练模型,页面地址是:https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/1。直接使用就可以了。注意,基于tf1.0的中文预训练模型(bert_chinese_L-12_H-768_A-12)不能在tf2.0里使用,要用脚本转换,但我们既然已经有了最新的模型,就直接用啦。
2.3. bert代码:在github上直接下载:https://github.com/tensorflow/models.git。注意bert已经被谷歌从tensorflow中分离出来,放在models目录下当成第三方独立代码了,所以需要自己下载配置。
2.4. 数据预处理脚本:在2.3步骤下载下来的bert代码里,位置是:models/official/nlp/bert/create_finetuning_data.py,其中已经定义好了支持若干种数据格式的类及实现,因为我需要处理上面自己定义的那种格式的数据,所以自己写了一个处理百度百科的类放到里面了,如果大家有自己的数据格式,修改后覆盖原来的文件就ok了,具体需要改的是:classifier_data_lib.py和create_finetuning_data.py 这两个文件
2. tf-nightly和bert代码下载:目前这个时间段基于tf2.0的bert只能在tf-nightly下面使用(看社区里的留言,应该在tf2.1正式发布的时候就会提供bert正式版了),所以要安装tf-nightly并且在这下面运行后面的代码。
3. 数据预处理脚本的执行:这个就按照命令行的模式在colab里调用脚本create_finetuning_data.py就可以了,没什么难的,有个坑是目前tf2.0的中文预训练模型没提供基于gs的存储位置,而预处理脚本中需要vocab.txt来分词,所以要先离线把模型下载下来,解压缩后,把里面的vocab.txt拿出来并上传到colab上,然后在预训练脚本里制定文件位置就ok(我把vocab.txt放到我的github上了,可以直接调用获取,但如果想获取最新的vocab.txt,最好自己下载然后加压获取。后续谷歌应该会提供在线模型地址,就不用这么麻烦了)
4. finetune:直接调用脚本models/official/nlp/bert/run_classifier.py,这里有个坑是脚本参数里需要bert_config.json,但上面的中文预处理模型没提供这个模型配置文件,所以干脆从其他tf1.0的模型里copy了一个过来(我用的是uncased_L-12_H-768_A-12的bert_config.json)
代码我都放到github上了,大家自己取用即可,欢迎拍砖、吐槽、交流!
https://github.com/liloi/bert-tf2/blob/master/bert-tf2-zh-demo.ipynb
打开并open in colab后,直接在colab中运行即可,有两个点要注意:
1. 安装完tf-nightly和requirements.txt之后,需要重启运行时环境,因为更换了tf了嘛
2. 最后为了看模型效果,用了tensorboard,但发现一直报错,后来社区里说是nightly版本的问题,所以按照社区的建议加了个重装tb-nightly的动作,也需要重启和运行时环境。
最终运行的效果:
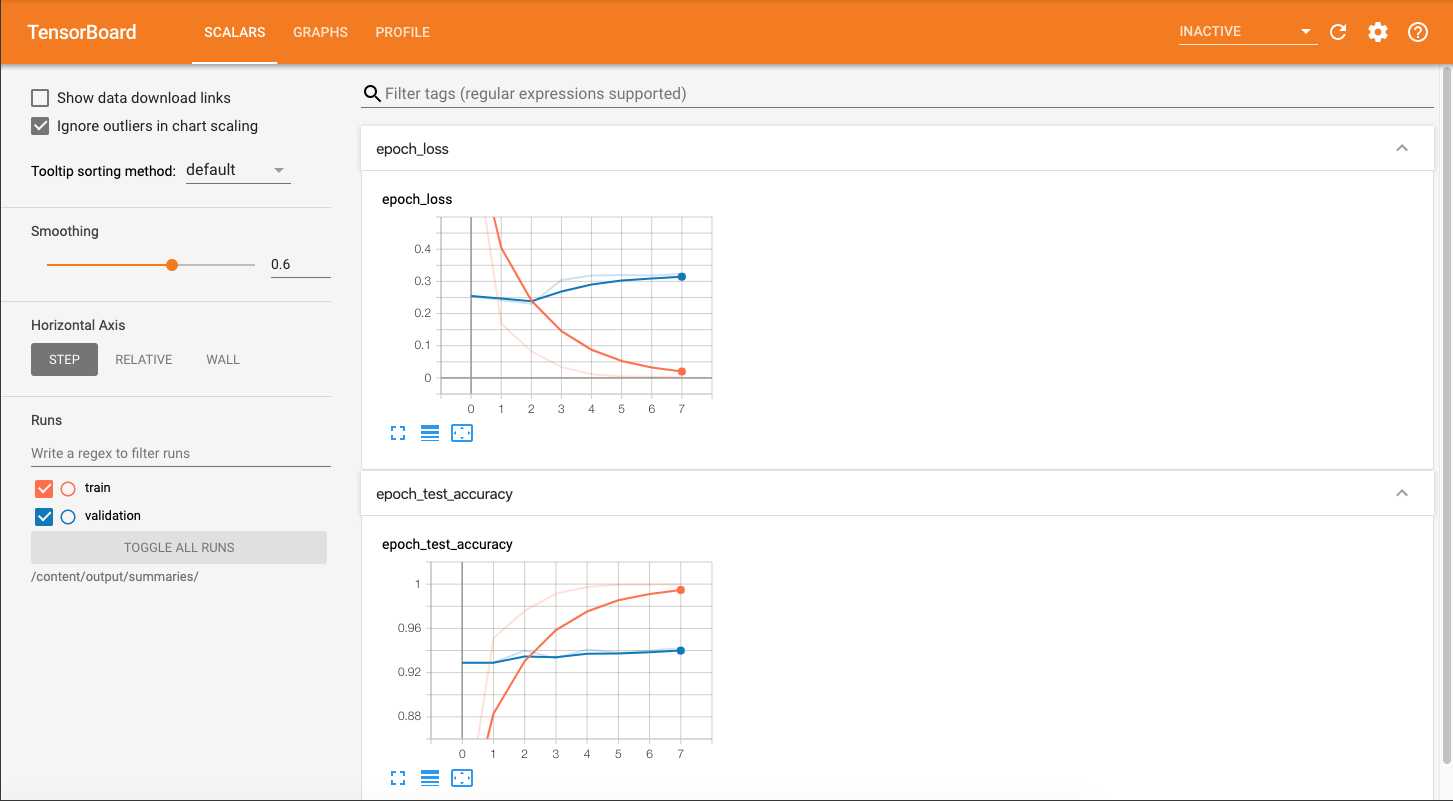
在epoch2之后就过拟合了,所以训练3轮应该就够了
colab上基于tensorflow2.0的BERT中文多分类
原文地址:https://www.cnblogs.com/zhongmiaozhimen/p/12228839.html