标签:世界 完整 表示 lib put sorted ros 电量 get
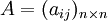 称为成对比较矩阵。
称为成对比较矩阵。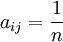 ,n=1,2,...,9,当且仅当a j i = n。
,n=1,2,...,9,当且仅当a j i = n。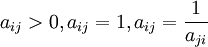 。(备注:当i=j时候,a i j = 1)
。(备注:当i=j时候,a i j = 1)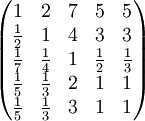 a 14 = 5表示品德与年龄重要性之比为5,即决策人认为品德比年龄重要。
a 14 = 5表示品德与年龄重要性之比为5,即决策人认为品德比年龄重要。
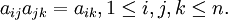
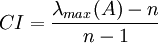
n
1
2
3
4
5
6
7
8
9
RI
0
0
0.58
0.90
1.12
1.24
1.32
1.41
1.45
注解:
从有关资料查出检验成对比较矩阵A 一致性的标准RI:RI称为平均随机一致性指标,它只与矩阵阶数n 有关(一般不超过9个)。
按下面公式计算成对比较阵A 的随机一致性比率CR:
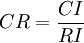 。
。
判断方法如下: 当CR<0.1时,判定成对比较阵A 具有满意的一致性,或其不一致程度是可以接受的;否则就调整成对比较矩阵A,直到达到满意的一致性为止。
例子的矩阵

特征向量: 0.47439499 0.26228108 0.0544921 0.09853357 0.11029827 (相加等于1)
算法过程 先对数组进行列相加----- [2.04285714,3.91666667,17 ,10.5 ,10.33333333]
再用等到的结果除以原矩阵得到一个新的矩阵:

再对矩阵进行行相加等到-------[2.37197494 1.31140538 0.2724605 0.49266783 0.55149136]
在进行归一化处理(上面的结果被阶数除)得到上面的特征向量(结果发现品德的影响最大)
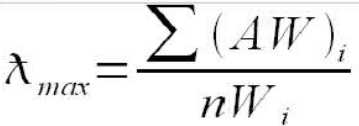
AW = 特征向量*原矩阵(一开始的),然后拿到每一行的和---- [2.42456102 1.34394248 0.27386595 0.50012206 0.55461416]
所以可得 (AW/阶数*特征向量) 5.07293180152562
计算得到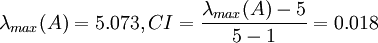 ,查得RI=1.12,
,查得RI=1.12,
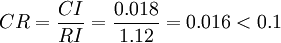
这说明A 不是一致阵,但A 具有满意的一致性,A 的不一致程度是可接受的。
层次总排序及决策
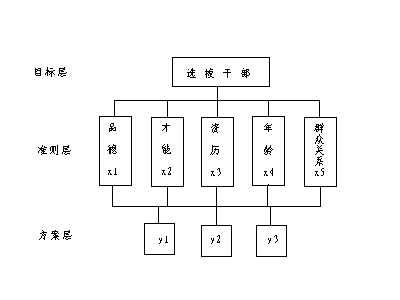
现在来完整地解决例2的问题,要从三个候选人y 1 , y 2 , y 3中选一个总体上最适合上述五个条件的候选人。对此,对三个候选人y = y 1 , y 2 , y 3分别比较他们的品德( x 1 ),才能( x 2 ),资历( x 3 ),年龄( x 4 ),群众关系( x 5 )。
先成对比较三个候选人的品德,得成对比较阵
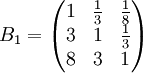
经计算,B 1的权向量
ω x 1 ( Y ) = (0.082,0.236,0.682) z
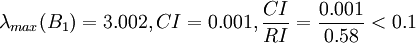
故B 1的不一致程度可接受。ω x 1 ( Y )可以直观地视为各候选人在品德方面的得分。
类似地,分别比较三个候选人的才能,资历,年龄,群众关系得成对比较阵
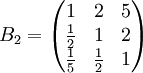
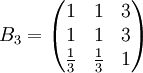
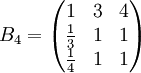 B5=
B5=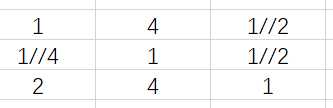
可得 5个特征向量

然后在通过
第一个人:(0.08199023*0.47439499 (一开始的那个特征向量)+0.59488796*0.26228108 +0.42857143*0.0544921 +0.63274854*0.09853357 +0.34595035*0.11029827 ) = 总得分
后两个人类似
最后得 第一个人得 0.31878206
第二个人得 0.23919592
第三个人得 0.44202202
所以3号是第一候选人
层次分析法的用途举例
例如,某人准备选购一台电冰箱,他对市场上的6种不同类型的电冰箱进行了解后,在决定买那一款式时,往往不是直接拿电冰箱整体进行比较,因为存在许多不可比的因素,而是选取一些中间指标进行考察。例如电冰箱的容量、制冷级别、价格、型号、耗电量、外界信誉、售后服务等。然后再考虑各种型号冰箱在上述各中间标准下的优劣排序。借助这种排序,最终作出选购决策。在决策时,由于6种电冰箱对于每个中间标准的优劣排序一般是不一致的,因此,决策者首先要对这7个标准的重要度作一个估计,给出一种排序,然后把6种冰箱分别对每一个标准的排序权重找出来,最后把这些信息数据综合,得到针对总目标即购买电冰箱的排序权重。有了这个权重向量,决策就很容易了。
层次分析法应用的程式
运用AHP法进行决策时,需要经历以下4个步骤:
1、建立系统的递阶层次结构;
2、构造两两比较判断矩阵;(正互反矩阵)
3、针对某一个标准,计算各备选元素的权重;
4、计算当前一层元素关于总目标的排序权重。
5、进行一致性检验。
附录 示例代码(python)

#!/usr/bin/env python # -*- coding: utf-8 -*- import numpy as np RI_dict = {1: 0, 2: 0, 3: 0.58, 4: 0.90, 5: 1.12, 6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45} def get_w(array): row = array.shape[0] # 计算出阶数 a_axis_0_sum = array.sum(axis=0) # print(a_axis_0_sum) b = array / a_axis_0_sum # 新的矩阵b # print(b) b_axis_0_sum = b.sum(axis=0) b_axis_1_sum = b.sum(axis=1) # 每一行的特征向量 # print(b_axis_1_sum) w = b_axis_1_sum / row # 归一化处理(特征向量) nw = w * row AW = (w * array).sum(axis=1) # print(AW) max_max = sum(AW / (row * w)) # print(max_max) CI = (max_max - row) / (row - 1) CR = CI / RI_dict[row] if CR < 0.1: # print(round(CR, 3)) # print(‘满足一致性‘) # print(np.max(w)) # print(sorted(w,reverse=True)) # print(max_max) # print(‘特征向量:%s‘ % w) return w else: print(round(CR, 3)) print(‘不满足一致性,请进行修改‘) def main(array): if type(array) is np.ndarray: return get_w(array) else: print(‘请输入numpy对象‘) if __name__ == ‘__main__‘: # 由于地方问题,矩阵我就写成一行了 e = np.array([[1, 2, 7, 5, 5], [1 / 2, 1, 4, 3, 3], [1 / 7, 1 / 4, 1, 1 / 2, 1 / 3], [1 / 5, 1 / 3, 2, 1, 1], [1 / 5, 1 / 3, 3, 1, 1]]) a = np.array([[1, 1 / 3, 1 / 8], [3, 1, 1 / 3], [8, 3, 1]]) b = np.array([[1, 2, 5], [1 / 2, 1, 2], [1 / 5, 1 / 2, 1]]) c = np.array([[1, 1, 3], [1, 1, 3], [1 / 3, 1 / 3, 1]]) d = np.array([[1, 3, 4], [1 / 3, 1, 1], [1 / 4, 1, 1]]) f = np.array([[1, 4, 1 / 2], [1 / 4, 1, 1 / 4], [2, 4, 1]]) e = main(e) a = main(a) b = main(b) c = main(c) d = main(d) f = main(f) try: res = np.array([a, b, c, d, f]) ret = (np.transpose(res) * e).sum(axis=1) print(ret) except TypeError: print(‘数据有误,可能不满足一致性,请进行修改‘)
matlab 代码
%层次分析法(AHP)
disp(‘请输入判断矩阵A(n阶)‘);
A = input(‘A=‘);
标签:世界 完整 表示 lib put sorted ros 电量 get
原文地址:https://www.cnblogs.com/h694879357/p/12229557.html