标签:阿拉伯 子邮件 unit 编码方式 打印 问题: net code ref
统一规定英语字符与二进制位之间的关系。ASCII码一共规定了128个字符的编码。例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号)只占用了一个字节的后面7位,最前面的1位统一规定为0。
世界上存在多种编码方式,同一个二进制数字可以被解释成不同的符号。之所以电子邮件经常出现乱码,是因为发信人和收信人使用的编码方式不一样。作为所有符号的编码,Unicode纳入了世界上所有的符号,给予每一个符号一个独一无二的编码。它是一个庞大的集合,可以容纳100多万个符号。例如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询http://www.unicode.org/或者汉字对应表。
Unicode的问题:
Unicode只是一个符号集,只规定了符号的二进制编码,但没有规定存储方式。例如,汉字严的Unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101)即需要2个字节。不同的符号需要的字节数量不同。存在如下2个问题:
1 如何区别Unicode和ASCII?
计算机怎么知道3个字节表示一个符号,而不是分别表示3个符号呢?
2 容易出现空间浪费
英文字母仅需一个字节。如果Unicode统一规定每个符号用3个或4个字节表示,那么存储英文字母时会出现2个或3个字节全是0,浪费空间。
于是,出现了Unicode的多种实现方式,例如 UTF-8, UTF-16, UTF-32。
码点(code point)是指与一个编码表中的某个字符对应的代码值。在Unicode标准中,码点采用十六进制书写,并加上前缀U+,例如U+0041就是字母A的码点。Unicode码点可以分成17个代码级别(code plane),每个代码级别可以用一个平面(Plane)表示,编号从 0 开始。
第一个平面即是 BMP(Basic Multilingual Plane 基本多语言平面),也叫 Plane 0,它的码点(code point)范围是 U+0000 ~ U+FFFF,这也是我们最常用的平面,其中包栝了经典的ASCII码,日常用到的字符绝大多数都落在这个平面内。其余的16个附加级别称为SP(Supplementary Planes增补平面),码点从U+10000到U+10FFFF,其中包栝了一些增补字符(supplementary character)。
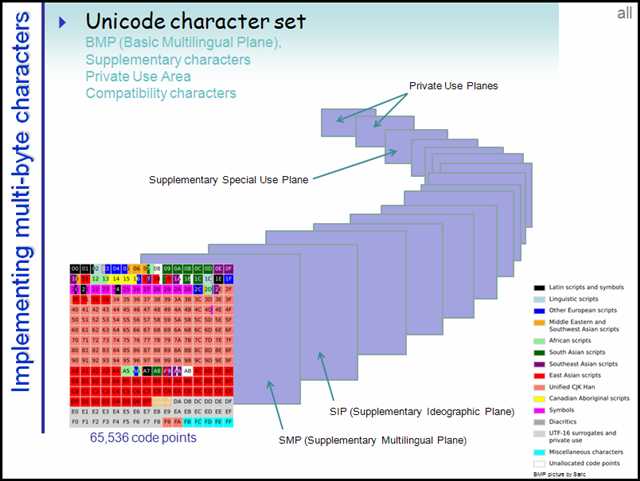
代码单元是指一种转换格式(UTF)中最小的一个分隔,称为代码单元(code unit)。因此,一种转换格式只会包含整数个代码单元。
各种UTF编码方案下的代码单元:
1. UTF-8 的 8 指的就是最小为8bit一个单元,也即一字节为一个单元,UTF-8 可以包含一个单元,二个单元,三个单元,四个单元,对应即是一,二,三,四个字节。
2. UTF-16 的 16 指的就是最小为16bit一个单元,也即两字节为一个单元。UTF-16可以包含一个单元,二个单元,对应二,四个字节。我们操作UTF-16时就是以它的单元为基本单位的。
3. 同理,UTF-32 以 32bit 一个单元,它只包含这一个单元就够了,也即4个字节。
所以,现在我们清楚了:UTF-X 中的数字 X 就是各自代码单元的位数。
标签:阿拉伯 子邮件 unit 编码方式 打印 问题: net code ref
原文地址:https://www.cnblogs.com/lingxue3769/p/12214395.html