标签:val 归一化 col 运用 svm font imp 哪些 params
一、前言
虽然一直算IT男,但是基本没有接触过最前沿的IT知识,一直在做生产方面的IT,突发奇想,开始学习算法,学习算法有半年多了,从最初的Python,到线性回归、逻辑回归、SVM,聚类,NLP,CNN,RNN,GAN等神经网络,感觉知识的海洋真是浩瀚如海,今天打算开始分享一下我的一些学习情况,第一个当然就是最基础的泰坦尼克存活预测啦。
二、背景介绍
背景介绍:泰坦尼克号沉没是历史上最著名的沉船事故之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。在这个案例中我们将运用机器学习来预测哪些乘客可以存活。
数据介绍:PassengerId:乘客ID,Survived:是否存活,0是死了1是活了,Pclass:船舱等级,Name:名字,Sex:性别,Age:年纪,SibSp:有几个兄弟姐妹,Parch:父母和小孩个数,Ticket:船票,Fare:船票价格,Cabin:客舱,Embarked:出发港口
实战介绍:这是一个kaggle比赛的一个题目,我应用的是Python3.7+Anaconda3进行操作的,主要分三步,数据分析、数据清洗和建模预测
三、数据集及代码
https://pan.baidu.com/s/1JuCWhOEgvAV6gocicddQ4A 提取码:1t9w
四、实战
a、数据分析
1、导入pandas和numpy库
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号
2、加载数据
data_train = pd.read_csv(‘train.csv‘)
data_test = pd.read_csv(‘test.csv‘)
3、查看数据的整体情况
data_train.shape#查看训练集的shape data_test.shape#查看测试集的shape
data_train.head(4)#查看一下前几行

data_train.info()#查看个数,空值情况以及数据类型

4、针对列业务数据进行单独分析
data_train.Pclass.value_counts()#查看船舱等级情况
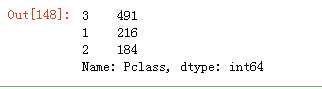
data_train.Sex.isnull().sum()#看看是否有空值

#画图查看和存活有关系吗
fig = plt.figure() fig.set(alpha=0.65) ax = fig.add_subplot(3,3,1) Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts() Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts() df_Pclass = pd.DataFrame({"Survived_1":Survived_1,"Survived_0":Survived_0}) df_Pclass.plot(kind=‘bar‘,stacked = True) df_Pclass.plot(kind=‘bar‘,stacked = False)
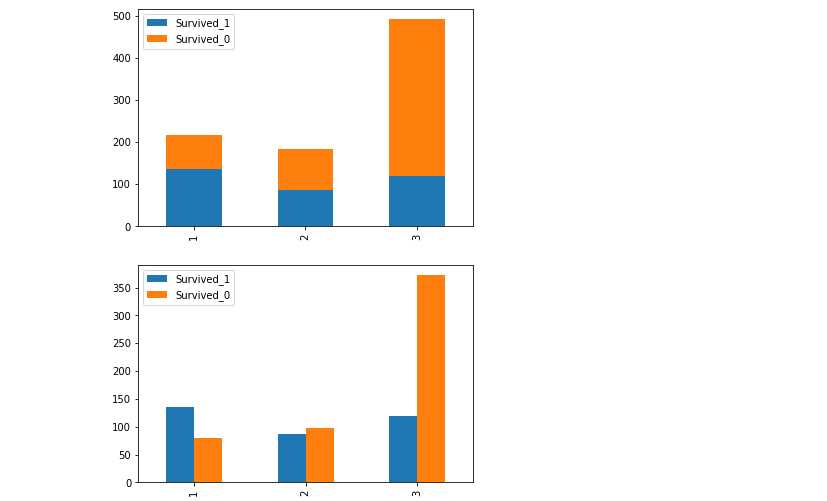
#得到信息,1等的活下来的概率高一点
#这个我感觉没啥可分析的
data_train.Sex.value_counts()#查看每类的个数

data_train.Sex.isnull().sum()#查看空值情况

#查看性别和存活的关系
fig = plt.figure() Survived_0 = data_train.Sex[data_train.Survived==0].value_counts() Survived_1 = data_train.Sex[data_train.Survived==1].value_counts() df_sex = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_sex.plot(kind=‘bar‘,stacked=True) plt.show()
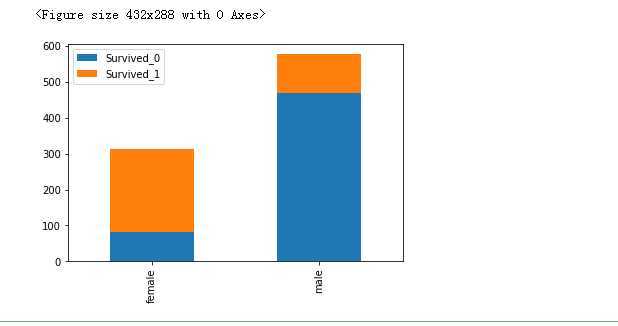
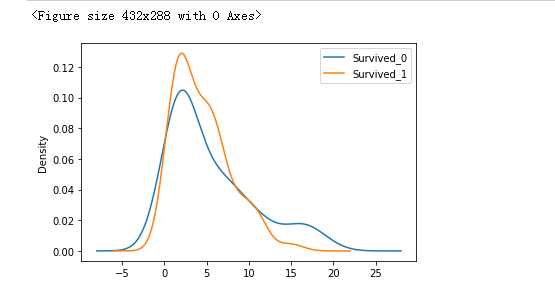
fig = plt.figure() Survived_0 = data_train.Age[data_train.Survived==0].value_counts() Survived_1 = data_train.Age[data_train.Survived==1].value_counts() df_sex = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_sex.plot(kind=‘kde‘,stacked=True) # plt.scatter(Survived_0.index,Survived_0.values) # plt.scatter(Survived_1.index,Survived_1.values) plt.show()
#分段看看
def get_age(age): if 0<age <= 8: return 0 if 8<age<=15: return 1 if 15<age<=22: return 2 if 22<age<=30: return 3 if 30<age<=38: return 4 if 38<age<=48: return 5 if 48<age<=58: return 6 if 58<age: return 7 else: return 8
data_train.Age = data_train.Age.apply(get_age)data_train.Age = data_train.Age.apply(get_age)
fig = plt.figure() Survived_0 = data_train.Age[data_train.Survived==0].value_counts() Survived_1 = data_train.Age[data_train.Survived==1].value_counts() df_sex = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) # df_sex.plot(kind=‘bar‘,stacked=True) df_sex.plot(kind=‘bar‘,stacked=False) # plt.scatter(Survived_0.index,Survived_0.values) # plt.scatter(Survived_1.index,Survived_1.values) plt.show()
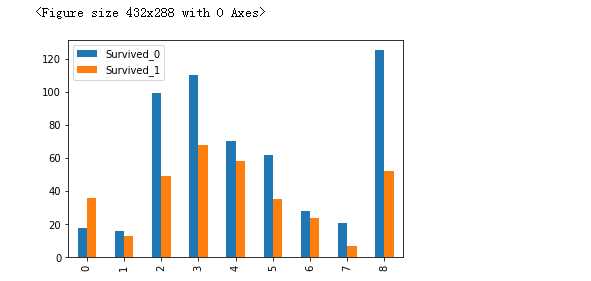
#年龄小 存活率大,但是也不一定 第三个栏位,28到38的也不少活着,后来一细分 发现20来岁的小伙子 活的概率也不高,看样子得做一下onehot
data_train.SibSp.value_counts()#看看分类情况

fig = plt.figure() Survived_0 = data_train.SibSp[data_train.Survived ==0].value_counts() Survived_1 = data_train.SibSp[data_train.Survived ==1].value_counts() df_sibsp = pd.DataFrame({"Survived_0":Survived_0,‘Survived_1‘:Survived_1}) df_sibsp.plot(kind=‘bar‘,stacked=True) plt.show()
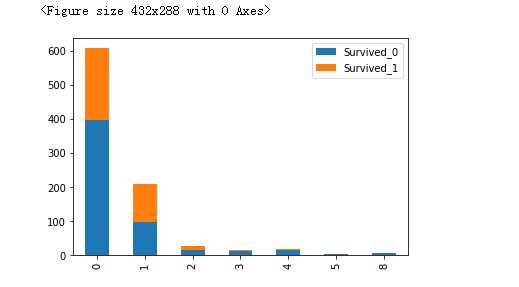
#看起来没有的容易死,一个的和两个的活的概率高,大于三个的基本就死了
data_train.Parch.value_counts()
fig = plt.figure() Survived_0 = data_train.Parch[data_train.Survived ==0].value_counts() Survived_1 = data_train.Parch[data_train.Survived ==1].value_counts() df_parch = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_parch.plot(kind = ‘bar‘,stacked = True) df_parch.plot(kind = ‘bar‘,stacked = False)
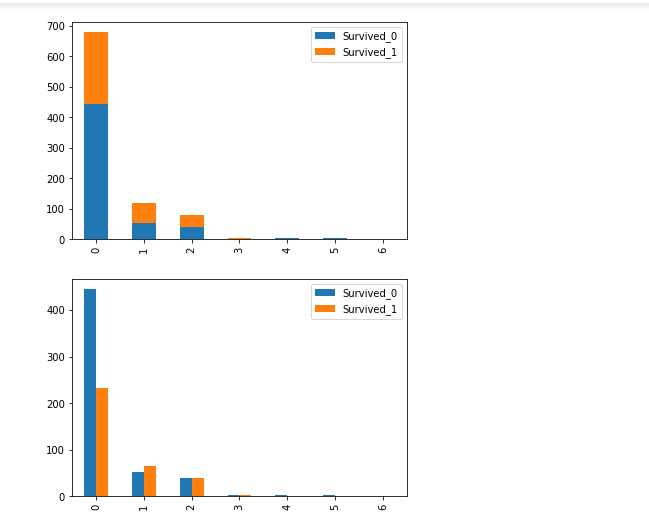
#还是独生子死亡率高,有一个或者两个的三个的反而基本都死了
#车票 这么多种类啊 ,看着头疼,不要了
def get_fare(fare): if fare<=8: return 0 elif 8<fare<=14: return 1 elif 14<fare<=30: return 2 elif 30<fare<=60: return 3 elif 60<fare: return 4
data_train.Fare = data_train.Fare.apply(get_fare)
fig = plt.figure() Survived_0 = data_train.Fare[data_train.Survived ==0].value_counts() Survived_1 = data_train.Fare[data_train.Survived ==1].value_counts() df_fare = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_fare.plot(kind = ‘bar‘)
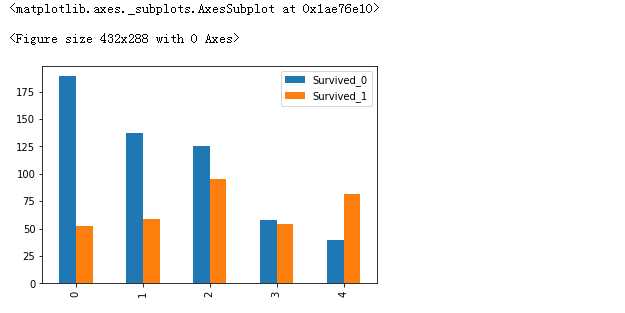
#通过这次,可以基本确定,这个车票买的越贵,人越容易存活
data_train.Cabin.isnull().sum() #这玩意也好多种类哟,又不是数字,还不好分段,还好多是空的,也可以分析一下,空和不空与死活有关系吗

data_train.loc[ (data_train.Cabin.notnull()), ‘Cabin‘ ] = "Yes" data_train.loc[ (data_train.Cabin.isnull()), ‘Cabin‘ ] = "No" Survived_0 = data_train.Cabin[data_train.Survived ==0].value_counts() Survived_1 = data_train.Cabin[data_train.Survived ==1].value_counts() df_fare = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_fare.plot(kind = ‘bar‘,stacked=True)
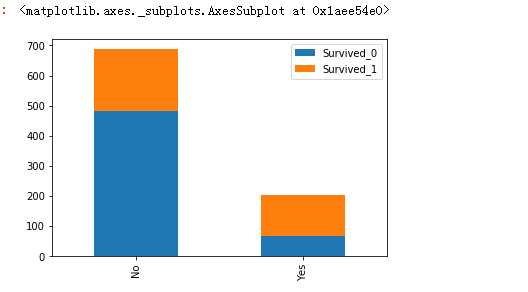
#这么看起来 貌似有点规律哟
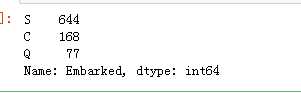
data_train.Embarked.value_counts()
Survived_0 = data_train.Embarked[data_train.Survived ==0].value_counts() Survived_1 = data_train.Embarked[data_train.Survived ==1].value_counts() df_fare = pd.DataFrame({‘Survived_0‘:Survived_0,‘Survived_1‘:Survived_1}) df_fare.plot(kind = ‘bar‘,stacked=True) df_fare.plot(kind = ‘bar‘,stacked=False)
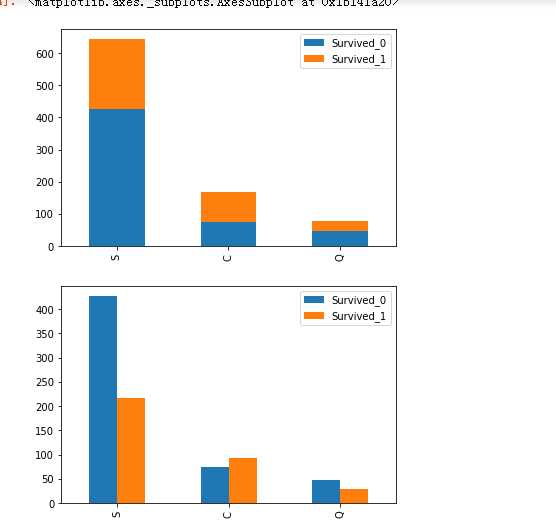
#C港的有点意思,可以能有一半多,其他俩看不出多大的规律来
fig = plt.figure(figsize=(15,20)) # fig.set(alpha=0.2) plt.subplot(5,3,1) data_train.Survived.value_counts().plot(kind=‘bar‘) plt.title("Survived(1 is Survived)") # puts a title on our graph plt.ylabel("counts") plt.subplot(5,3,2) data_train.Pclass.value_counts().plot(kind=‘bar‘) plt.title("船舱等级情况") plt.ylabel(‘counts‘) plt.subplot(5,3,3) data_train.Sex.value_counts().plot(kind=‘bar‘) plt.title(‘male or female‘) plt.ylabel(‘counts‘) plt.subplot(5,3,4) data_train.Age.value_counts().plot(kind=‘kde‘) plt.title(‘age‘) plt.ylabel(‘counts‘) plt.subplot(5,3,5) plt.scatter(data_train.Survived, data_train.Age) plt.ylabel(u"年龄") # sets the y axis lable plt.grid(b=True, which=‘major‘, axis=‘y‘) # formats the grid line style of our graphs plt.title(u"按年龄看获救分布 (1为获救)") plt.subplot(5,3,6) data_train.Parch.value_counts().plot(kind=‘bar‘) plt.title("兄弟姐妹个数") plt.ylabel("人数") plt.subplot(5,3,7) plt.scatter(data_train.Survived,data_train.Fare) plt.title("0:死,1:活") plt.ylabel("船票价格") plt.subplot(5,3,8) data_train.Fare.value_counts().plot(kind=‘kde‘) plt.title("船票价格") plt.ylabel("人员分布") plt.subplot(5,3,8) data_train.Embarked.value_counts().plot(kind=‘bar‘) plt.title("港口情况") plt.ylabel("人员分布")
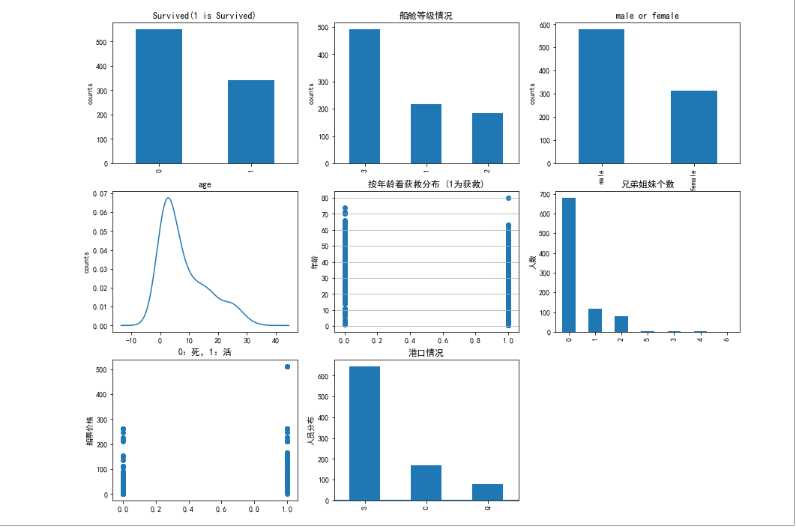
fig = plt.figure() p1_m = data_train.Sex[data_train.Sex == ‘male‘][data_train.Pclass == 1].value_counts() p2_m = data_train.Sex[data_train.Sex == ‘male‘][data_train.Pclass == 2].value_counts() p3_m = data_train.Sex[data_train.Sex == ‘male‘][data_train.Pclass == 3].value_counts() pd.DataFrame({‘p1_m‘:p1_m,‘p2_m‘:p2_m,‘p3_m‘:p3_m}).plot(kind=‘bar‘) p1_f = data_train.Sex[data_train.Sex == ‘female‘][data_train.Pclass == 1].value_counts() p2_f = data_train.Sex[data_train.Sex == ‘female‘][data_train.Pclass == 2].value_counts() p3_f = data_train.Sex[data_train.Sex == ‘female‘][data_train.Pclass == 3].value_counts() pd.DataFrame({‘p1_f‘:p1_f,‘p2_f‘:p2_f,‘p3_f‘:p3_f}).plot(kind=‘bar‘)
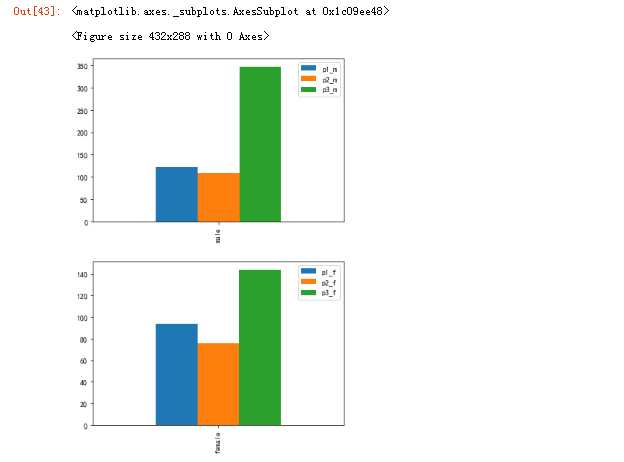
#整体来看,没啥关系,男的在高等的人数多点 比例稍微差点,但是感觉不怎么明显
df_pf1 = data_train.Fare[data_train.Pclass==1].value_counts() df_pf2 = data_train.Fare[data_train.Pclass==2].value_counts() df_pf3 = data_train.Fare[data_train.Pclass==3].value_counts() df_pf = pd.DataFrame({‘df_pf1‘:df_pf1,‘df_pf2‘:df_pf2,‘df_pf3‘:df_pf3}) plt.scatter(df_pf1.index,df_pf1.values,c=‘r‘,marker=‘.‘) # plt.subplot(1,3,2) plt.scatter(df_pf2.index,df_pf2.values,c = ‘y‘,marker=‘.‘) # plt.subplot(1,3,3) plt.scatter(df_pf3.index,df_pf3.values,c = ‘k‘,marker=‘.‘)
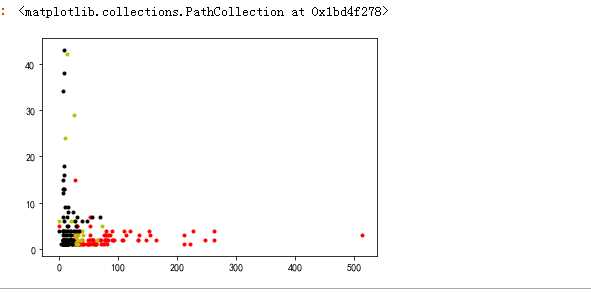
#一等票价高,三等的和二等的票价低,当然二等的比三等的票价高一点,符合相关逻辑,即票和船舱等级是正相关的
fig = plt.figure(figsize=(10,8)) df_pm1 = data_train.Embarked[data_train.Pclass==1].value_counts() df_pm2 = data_train.Embarked[data_train.Pclass==2].value_counts() df_pm3 = data_train.Embarked[data_train.Pclass==3].value_counts() df_pm = pd.DataFrame({‘df_pm1‘:df_pm1,‘df_pm2‘:df_pm2,‘df_pm3‘:df_pm3}) df_pm.plot(kind=‘bar‘)
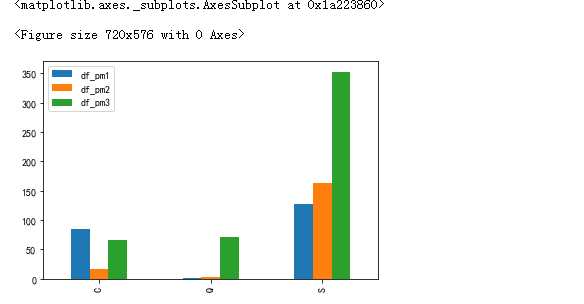
#从这里可以看出来,C港出发的人,貌似一等多,Q的三等的多,S的较为正常
fig = plt.figure(figsize=(18,8)) df_pa1 = data_train.Age[data_train.Pclass==1].value_counts() df_pa2 = data_train.Age[data_train.Pclass==2].value_counts() df_pa3 = data_train.Age[data_train.Pclass==3].value_counts() df_pa = pd.DataFrame({‘df_pa1‘:df_pa1,‘df_pa2‘:df_pa2,‘df_pm3‘:df_pa3}) # plt.subplot(1,3,1) plt.scatter(df_pa1.index,df_pa1.values,c=‘r‘,marker=‘.‘) # plt.subplot(1,3,2) plt.scatter(df_pa2.index,df_pa2.values,c = ‘y‘,marker=‘.‘) # plt.subplot(1,3,3) plt.scatter(df_pa3.index,df_pa3.values,c = ‘k‘,marker=‘.‘)
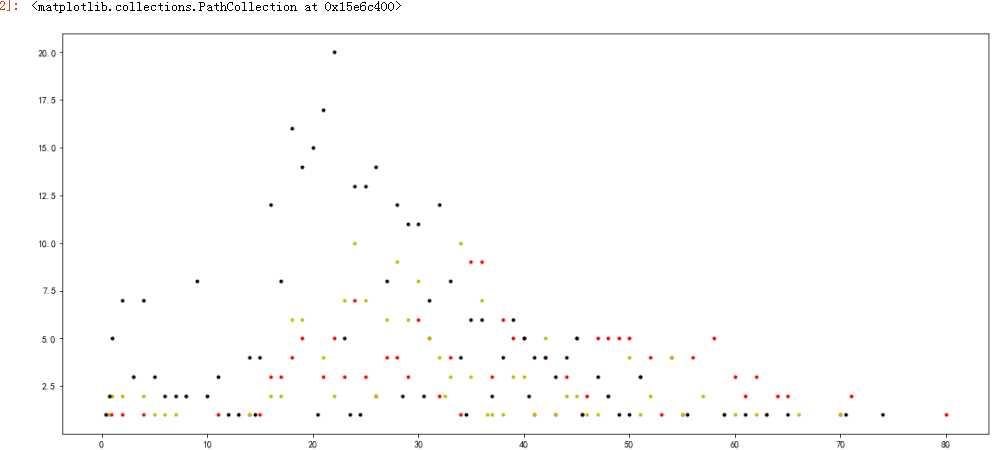
#图好难看啊 ,但是 虽然难看,但是可以稍微看到,黑的 也就是三等的,年轻人18—25之间十分的集中
df_as1 = data_train.Age[data_train.Sex==‘male‘].value_counts() df_as2 = data_train.Age[data_train.Sex==‘female‘].value_counts() # plt.subplot(1,3,1) plt.scatter(df_as1.index,df_as1.values,c=‘r‘,marker=‘.‘) # plt.subplot(1,3,2) plt.scatter(df_as2.index,df_as2.values,c = ‘k‘,marker=‘.‘)
#分布来看,也没发现女的在某些年龄段人数过多,比如少年,比如中年这两个段,特别是中年这个段存活异常,应该不是性别造成的
df_sf1 = data_train.Fare[data_train.Sex==‘male‘].value_counts() df_sf2 = data_train.Fare[data_train.Sex==‘female‘].value_counts() # plt.subplot(1,3,1) plt.scatter(df_sf1.index,df_sf1.values,c=‘r‘,marker=‘.‘) # plt.subplot(1,3,2) plt.scatter(df_sf2.index,df_sf2.values,c = ‘k‘,marker=‘.‘)
#就这么看来,女的好像买的贵哦 但是和之前船舱一样 也不怎么明显
df_sm1 = data_train.Embarked[data_train.Sex==‘male‘].value_counts() df_sm2 = data_train.Embarked[data_train.Sex==‘female‘].value_counts() pd.DataFrame({"df_sm1":df_sm1,"df_sm2":df_sm2}).plot(kind=‘bar‘)
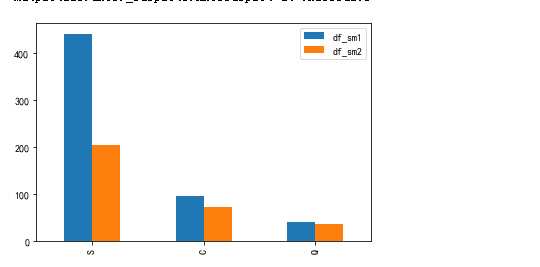
data_train[‘family‘] = data_train.SibSp + data_train.Parch
df_f0 = data_train.family[data_train.Survived==0].value_counts() df_f1 = data_train.family[data_train.Survived==1].value_counts() pd.DataFrame({‘df_f0‘:df_f0,‘df_f1‘:df_f1}).plot(kind=‘bar‘,sharey=True)
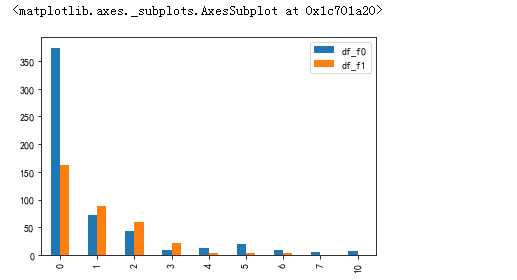
#1、2、3个的时候活下来的概率搞,其次是0个,绝对的单身狗吗 ,什么都没有,也是无语了
1、Pclass 船票等级越高,越容易存活下来,是线性的,不需要加维度
2、Sex,女的越容易存活下来
3、Age,小的容易活下来,可能是因为年纪关系,15-25的活的不多,可能与船票有关系,买的低等舱,反而中年人有钱,买的高等的,或下的不少,看来要进行升维度了
4、Sibsp,一两个活下来的概率搞,其实是0个,升维度啊 <br>
5、Pare,社会自古以来原来都这样,有钱人活下来的概率高啊,正相关,只需要做归一化
6、Cabin,空的太多,不打算要了
7、Embrbed,出发港口的话呢,C活的概率搞点,综合来看,可能是因为一等舱的人数多,再加上女的比例不少导致的,可以去掉吗
8、family,多加了一项,发现1,2,3个家庭成员的时候,活的概率大,其次是0个,这个和之前的相加结果好心很类似哦
标签:val 归一化 col 运用 svm font imp 哪些 params
原文地址:https://www.cnblogs.com/rgzngf/p/12231404.html