标签:etc 根据 封装 含义 没有 dfs 输出 nec 做了
目录
SparkStreaming主要用作对流数据的实时处理,比如:实时的 web 日志数据分析、实时追踪页面访问统计数据等。
流数据的特点有:
Spark Streaming 是在 Spark 上建立的可扩展的高吞吐量实时处理流数据的框架,数据可以是来自多种不同的源,例如 kafka、Flume、Twitter、ZeroMQ 或者 TCP Socket 等。在这个框架下,支持对流数据的各种运算,比如 map、reduce、join 等。处理过后的数据可以存储到文件系统或数据库。
教程给出的Streaming 的框架是下图这样的,左边是流数据源,右边是处理后输出数据的存储目标。

也就是说,之前用的hdfs文件系统在sparkStreaming应用里还是能用的。
Dstream是这一组件的基本数据抽象,其中文含义是“离散化流”,这个概念对于SparkStreaming,就像RDD对于Spark本身。
它代表一个随时间推移而受到的连续数据流,这既可以是从数据源中接收的输入数据流,也可以是通过转化输入流生成的已处理数据流。在它的内部,DStream 是由一系列连续的 RDD 表示,每个 RDD 都包含来自特定时间间隔的数据。
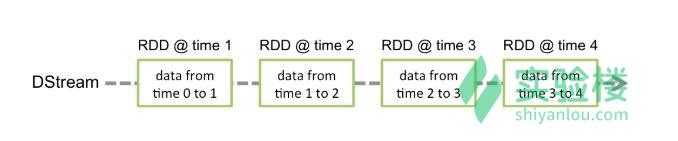
应用于 DStream 上的任何操作都会转换为底层的 RDD 操作。下面是教程里面的示例图片,可以看出来,每一个时刻的“行”RDD一起组成了一个lineDStream,然后,对这个lineDStream做了flatMap操作之后,整体上“行”DStream变成了单词DStream,实际上这是底层的每一个对应每个时刻的RDD都被flatMap转化成每个时刻的单词RDD才实现的。
在最底层,Spark Streaming 对数据的处理方式采用的方法是对 Stream 数据进行时间切片,分成小的数据片段,通过类似批处理的方式处理数据片段。
从整体上来讲,Spark Streaming 的处理思路就是:将连续的数据持久化、离散化,然后进行批量处理。
DStream 相当于对 RDD 的再次封装 ,它提供了转化操作和输出操作两种操作方法。
这个就是“流数据”的上下文对象,就像之前的Sparkcontext对象(sc)的给RDD提供的操纵功能一样,这个上下文对象提供了DStream的创建和转化还有数据的接收和处理的功能。没有StreamingContext对象就不能使用这些功能。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1)) //这里把conf配置对象传给对应的方法对于RDD的操纵是要使用sparkContext的,如果还需要用SparkContext来操纵RDD,那就需要知道StreamingContext 内部会就会创建 SparkContext
调用方法就是圆点调用符号
ssc.sparkContext每个 Input DStreams(数据源) ,除了 file stream,都会关联一个 Receiver(接收器)对象,接收器对象就可以接收数据源中的数据并存储到内存中。
Spark Streaming 提供了两种类型的内置数据源:
基础数据源。可以直接使用 StreamingContext 的 API,比如文件系统,socket 连接,Akka。对于简单的文件,可以使用 streamingContext 的 textFileStream 方法处理。
高级数据源。比如 Flume,Kafka,Kinesis,Twitter 等可以使用工具类的数据源。使用这些数据源需要对应的依赖
DStream 的转化操作分为无状态和有状态两种。
每个批次的数据不依赖于之前批次的数据。
| 转化操作 | 含义 |
|---|---|
| map(func) | 根据 func 函数生成一个新的 DStream |
| flatMap(func) | 跟 map 方法类似,但是每一项可以返回多个值。func 函数的返回值是一个集合 |
| union(otherStream) | 取 2 个 DStream 的并集,得到一个新的 DStream |
| count() | 计算 DStream 中所有 RDD 的个数 |
| reduce(func) | 计算 DStream 中的所有 RDD 通过 func 函数聚合得到的结果 |
| countByValue() | 如果 DStream 的类型为 K,那么返回一个新的 DStream,这个新的 DStream 中的元素类型是(K, Long),K 是原先 DStream 的值,Long 表示这个 Key 有多少次 |
| reduceByKey(func, [numTasks]) | 对于是键值对(K,V)的 DStream,返回一个新的 DStream 以 K 为键,各个 value 使用 func 函数操作得到的聚合结果为 value |
| join(otherStream, [numTasks]) | 基于(K, V)键值对的 DStream,如果对(K, W)的键值对 DStream 使用 join 操作,可以产生(K, (V, W))键值对的 DStream |
| cogroup(otherStream, [numTasks]) | 跟 join 方法类似,不过是基于(K, V)的 DStream,cogroup 基于(K, W)的 DStream,产生(K, (Seq[V], Seq[W]))的 DStream |
| transform(func) | 基于 DStream 中的每个 RDD 调用 func 函数,func 函数的参数是个 RDD,返回值也是个 RDD |
| updateStateByKey(func) | 对于每个 key 都会调用 func 函数处理先前的状态和所有新的状态 |
需要使用之前批次的数据或中间结果来计算当前批次的数据。
有状态转化操作包括 Window 操作(基于窗口的转化操作) 和 UpdateStateByKey 操作(追踪状态变化的转化操作)
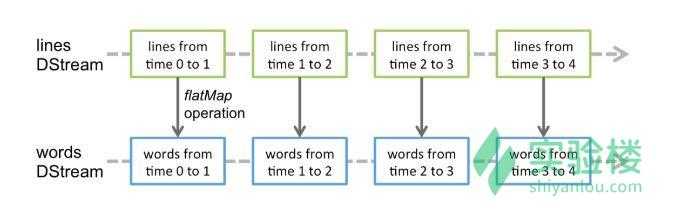
Window操作用作把几个批次的DStream合并成一个DStream,换句话说就是把这个窗口之内的DStream变成一个DStream
每个 window 操作都需要 2 个参数:
window length。顾名思义,就是窗口的长度。每个 window 对应的批次数(下图中是 3,time1-time3 是一个 window, time3-time5 也是一个 window)
sliding interval。顾名思义,窗口每次滑动的间隔。每个 window 之间的间隔时间,下图下方的 window1,window3,window5 的间隔。图中这个值为 2。
UpdateStateByKey 操作
使用 UpdateStateByKey 方法需要做以下两步:
定义状态:状态可以是任意的数据类型
定义状态更新函数:这个函数需要根据输入流把先前的状态和所有新的状态
不管有没有新数据进来,在每个批次中,Spark 都会对所有存在的 key 调用 func 方法,如果 func 函数返回 None,那么 key-value 键值对不会被处理。
以一个例子来讲解 updateStateByKey 方法,这个例子会统计每个单词的个数在一个文本输入流里:
runningCount 是一个状态并且是 Int 类型,所以这个状态的类型是 Int,runningCount 是先前的状态,newValues 是所有新的状态,是一个集合,函数如下:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}updateStateByKey 方法的调用
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)DStream 中的数据一般会输出到数据库、文件系统等外部系统中
| 输出操作 | 含义 |
|---|---|
| print() | 打印出 DStream 中每个批次的前 10 条数据 |
| saveAsTextFiles(prefix, [suffix]) | 把 DStream 中的数据保存到文本文件里。每次批次的文件名根据参数 prefix 和 suffix 生成:”prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) | 把 DStream 中的数据按照 Java 序列化的方式保存 Sequence 文件里,文件名规则跟 saveAsTextFiles 方法一样 |
| saveAsHadoopFiles(prefix, [suffix]) | 把 DStream 中的数据保存到 Hadoop 文件里,文件名规则跟 saveAsTextFiles 方法一样 |
| foreachRDD(func) | 遍历 DStream 中的每段 RDD,遍历的过程中可以将 RDD 中的数据保存到外部系统中 |
注:
foreachRDD 方法会遍历 DStream 中的每段 RDD,遍历的过程中可以将 RDD 中的数据保存到外部系统中。将数据写到外部系统通常都需要一个 connection 对象,一种很好的方式就是使用 ConnectionPool,ConnectionPool 可以重用 connection 对象在多个批次和 RDD 中。示例代码如下:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}DStream 的输出操作也是延迟执行的(惰性操作),就像 RDD 的 action 操作一样。RDD 的 action 操作在 DStream 的输出操作内部执行的话会强制 Spark Streaming 执行从而获得输出。
项目例子中我们通过实现一个 Spark Streaming 应用连接给定 TCP Socket,接收字符串数据并对数据进行 MapReduce 计算单词出现的频次。这个例子来自官方文档并做了一些修改。
Spark Streaming 上构建应用与 Spark 相似,都要先创建 Context 对象,并对抽象数据对象进行操作,Streaming 中处理的数据对象是 DStream。
// 引入spark.streaming中的StreamingContext模块
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// 注:最后一项在Spark 1.3及其之后的版本中不是必需的
// 下面这一句在 Spark Shell 中是不必输入的,因为 Spark Context 对象在 Spark Shell 启动过程中就已经创建好
// 创建本地的SparkContext对象,包含2个执行线程,APP名字命名为StreamWordCount
// val conf = new SparkConf().setMaster("local[2]").setAppName("SteamWordCount")
// 直接通过 Spark Context 对象 sc ,创建本地的StreamingContext对象,第二个参数为处理的时间片间隔时间,设置为1秒
val ssc = new StreamingContext(sc, Seconds(1))所以两个关键的东西就是,SparkContext对象和数据处理的时间间隔。这里把数据处理的时间间隔设置成一秒。
这里是从一个socket获取数据的,对应的指定数据源的函数是“socketTextStream”,注意这步在没有nc命令让计算机开启9999端口的监听时,也可以输入并且不会报错,原因在于在ssc.start()输入之前所有的业务逻辑或者说执行操作的代码都可以被看做是惰性的操作,只有调用了start()之后Streamingcontext才运行之前输入的表示业务逻辑的代码,也就是说,按照我们的代码,只要在start()调用之前用nc开启监听就可以让程序正确运行。
// 创建DStream,指明数据源为socket:来自localhost本机的9999端口
val lines = ssc.socketTextStream("localhost", 9999)lines 数据源可以来自各种不同的数据源,但原理都类似,调用不同的创建函数去连接 Kafka、 Flume、HDFS/S3、Kinesis 和 Twitter 等数据源。

对表示每行的DStream分割成每个单词的DStream。
这个操作和之前学的对RDD的操作基本没有什么区别,最大的不同是调用flatMap方法的对象不再是一个RDD对象而是一个DStream对象。
// 使用flatMap和Split对1秒内收到的字符串进行分割
val words = lines.flatMap(_.split(" "))然后做最简单的求和
// map操作将独立的单词映射到(word,1)元组
val pairs = words.map(word => (word, 1))
// reduceByKey操作对pairs执行reduce操作获得(单词,词频)元组
val wordCounts = pairs.reduceByKey(_ + _)写入文件系统
// 输出文件夹的前缀,Spark Streaming会自动使用当前时间戳来生成不同的文件夹名称
val outputFile = "/tmp/ss"
// 将结果输出
wordCounts.saveAsTextFiles(outputFile)要注意的是,到这里上面这些语句其实都还没有被执行,只有StreamingContext对象调用了start()方法,上面这些语句才作为业务逻辑不停的被执行,而且,时间间隔是调用StreamingContext对象的时候指定好的,这里就是一秒。就是说,调用了start方法之后,9999端口上监听到的数据每隔一秒就会被sparkStreaming计算一次单词数,然后保存到对应的文件系统路径下。
每隔一秒还是挺快的,我就上了个厕所
就这样了,
Spark学习9 Spark Streaming流式数据处理组件学习
标签:etc 根据 封装 含义 没有 dfs 输出 nec 做了
原文地址:https://www.cnblogs.com/ltl0501/p/12232332.html