标签:hadoop 历史 图计算 交互式 控制 tor 批处理 hive 抽象
今天主要学习了对spark的初步认识以及相应名词的理解
包括Spark特点、 Scala特性、BDAS架构、Spark组件的应用场景、Spark基本概念、Spark运行架构、 Spark架构设计的优点 、Spark各种概念之间的相互关系
Hadoop 是基于磁盘的大数据计算框架 Spark是基于内存计算的大数据并行计算框架
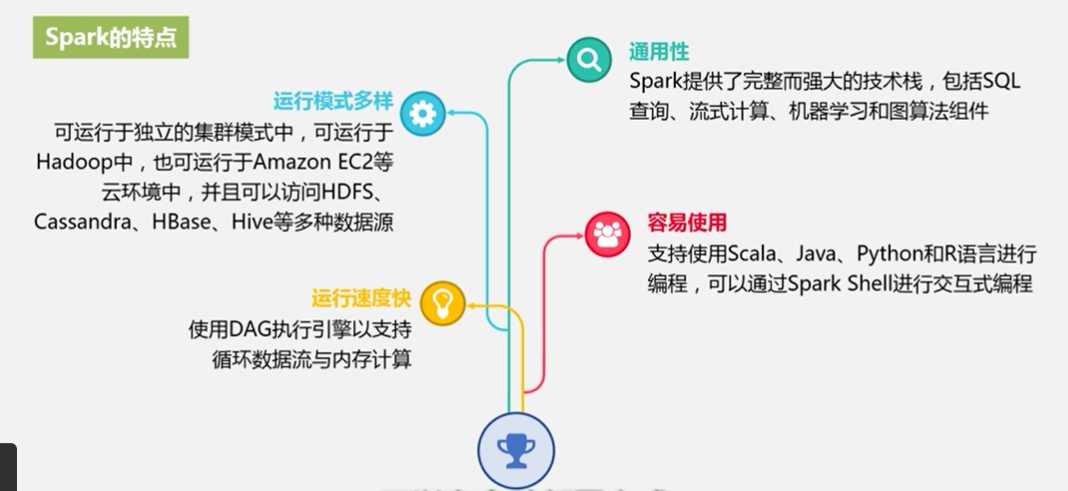
Spark特点
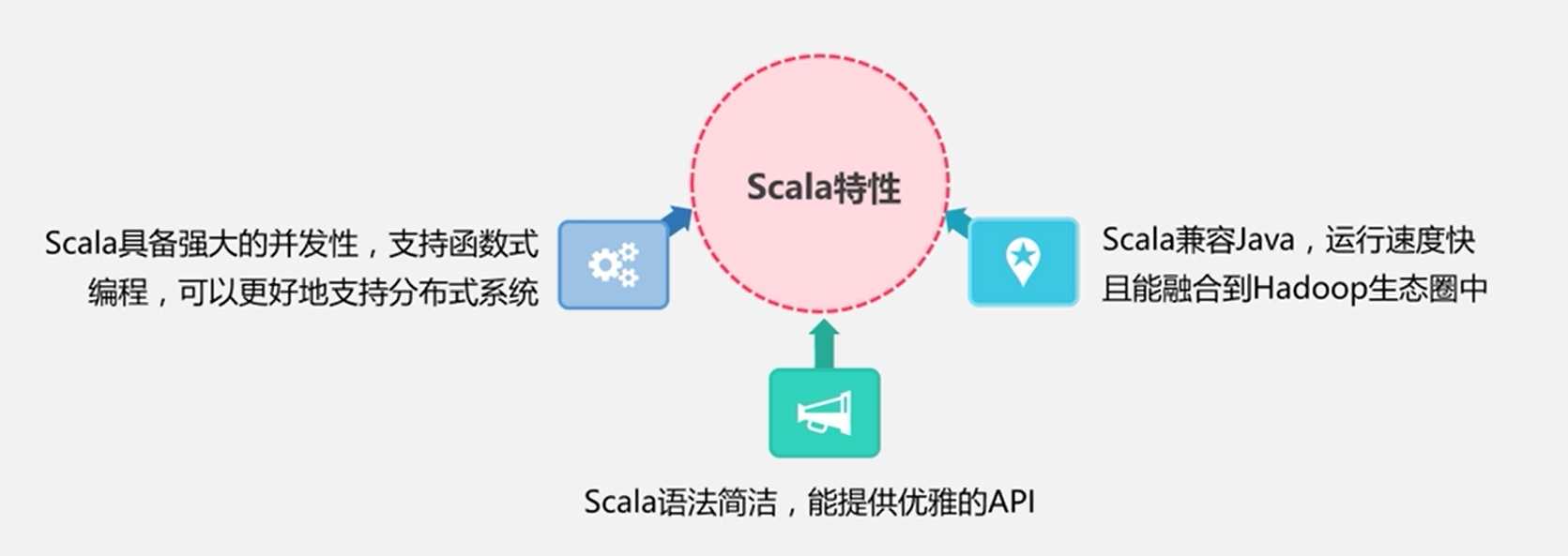
Scala特性
BDAS架构
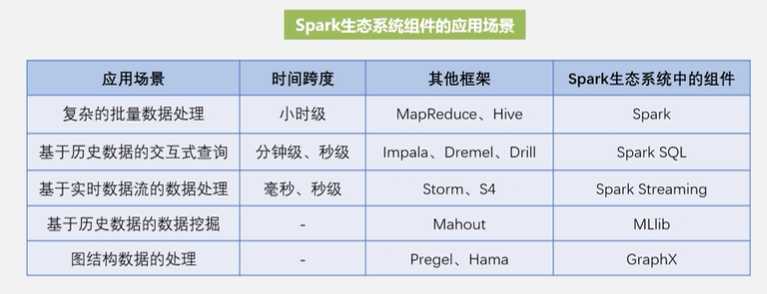
MapReduce 软件适用于做复杂的批量数据处理(数十分钟到数小时)
Cloudera Impala 软件(类似于hive)基于历史数据的交互式查询(数十秒到数分钟)
Storm 软件基于实时数据流的数据处理( 数百毫秒到数秒)
Spark可以同时满足企业各种应用需求(同时支持批处理 交互式查询 和流数据处理 )

希望这种架构可以满足企业不同类型的需求
最底层(Mesos Hadoop Yarn )是资源的虚拟化层
Spark基于内存计算功能依靠Spark Core实现
Spark SQL提供交互式查询分析
Spark Streaming 提供了流计算功能
MLlib 提供机器学习算法库的组件
Graphx提供图计算
Spark组件的应用场景
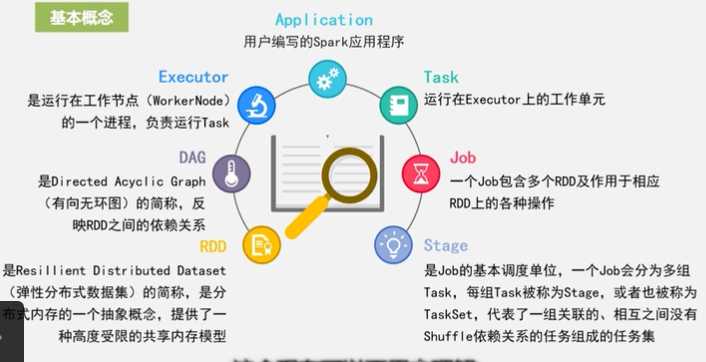
Spark基本概念
RDD (弹性分布式数据集)(分布式 内存的抽象概念 提供了一种高度受限的共享内存模型)
DAG(有向无环图)
Executor 运行具体Task的一个节点
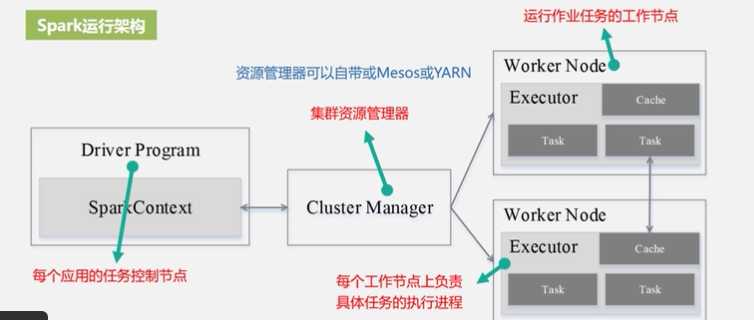
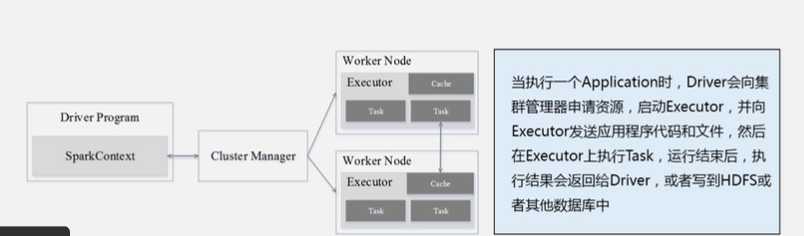
Spark运行架构
Cluster Manager 集群资源管理器
Worker Node运行作业任务的工作节点
Driver 每个应用的任务控制节点
Executor 每个工作节点上负责具体任务的的执行进程
Spark架构设计的优点
1.利用多线程来执行具体的任务 减少任务的启动开销
2.Executor 中有一个BlockManager存储模块 会将内存和磁盘共同作为存储设备 有效减少磁盘IO开销(优先写到内存)
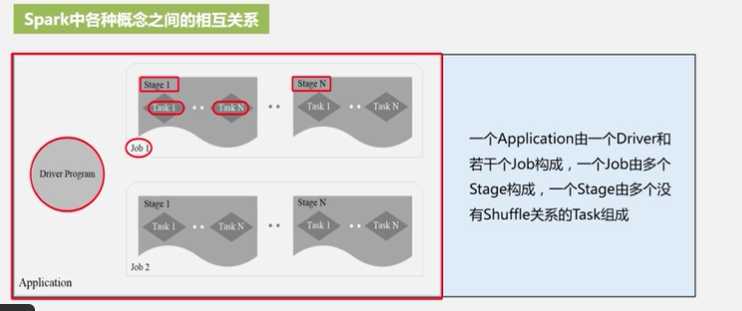
Spark各种概念之间的相互关系
标签:hadoop 历史 图计算 交互式 控制 tor 批处理 hive 抽象
原文地址:https://www.cnblogs.com/zzstdruan1707-4/p/12234789.html